- *: 모든 열 선택 - 모든 열 출력하고 맨 끝에 다시 한 번 특정 컬럼 출력해야 하는 경우) SELECT table.*, column FROM table; (ex) SELECT dept.*, deptno FROM dept;
3. 컬럼 별칭을 사용하여 출력되는 컬럼명 변경하기
SELECT empno as 사원 번호, ename as 사원 이름, sal as "Salary"
FROM emp;
- 컬럼명 as 컬럼 별칭(alias) - 컬럼 별칭에 " " 로 감싸줘야 하는 경우 - 대소문자 구분하여 출력할 때 - 공백문자 출력할 때 - 특수문자 출력할 때 ($, _, # 만 가능)
- 수식을 사용하여 결과 출력할 때 별칭 유용함 -> ORDER BY 절 사용할 때 유용
#(ex) 월급 = sal * (12 + 3000)
SELECT ename, sal * (12 + 3000) as 월급
FROM emp;
4. 연결 연산자 사용하기 ( || )
SELECT ename || sal
FROM emp;
- 컬럼과 컬럼 연결하여 출력 - (ex)
ENAME||SAL
KING5000
BLAKE2850
JONE2975
SELECT ename || '의 월급은 ' || sal || '입니다.' as 월급정보
FROM emp;
월급정보
KING의 월급은 5000입니다.
BLAKE의 월급은 2850입니다.
JONE의 월급은 2975입니다.
5. 중복된 데이터 제거해서 출력하기 (DISTINCT)
SELECT DISTINCT job
FROM emp;
SELECT UNIQUE job
FROM emp;
- 컬럼에 있는 데이터들 중 중복된 것은 하나씩만 출력 (UNIQUE한 값만 출력)
6. 데이터 정렬해서 출력하기 (ORDER BY)
SELECT ename, sal
FROM emp
ORDER BY sal asc;
- asc: 오름차순, desc: 내림차순 - ORDER BY 절은 작성 시에도, 실행 시에도 맨 마지막에 실행됨 -> SELECT 절에 사용한 컬럼 별칭을 ORDER BY 절에 사용할 수 있음
SELECT ename, sal as 월급
FROM emp
ORDER BY 월급 asc;
- ORDER BY 절에 컬럼 여러개 작성 가능
SELECT ename, deptno, sal
FROM emp
ORDER BY deptno asc, sal desc;
-> 먼저 deptno를 오름차순 정렬한 것을 기준으로, 같은 deptno 내에서는 sal 내림차순 정렬 - 컬럼명 대신 숫자로도 작성 가능 -> SELECT 절 컬럼 순서
7. WHERE 절 배우기
(1) 숫자 데이터 검색
ex) 월급이 3000인 직원들의 이름, 월급, 직업 출력
SELECT ename, sal, job
FROM emp
WHERE sal = 3000;
- 원하는 검색 조건을 WHERE 절에 작성하여 데이터 검색 - WHERE 절은 FROM 절 다음에 작성 - 비교 연산자
연산자
의미
>
크다
<
작다
>=
크거나 같다
<=
작거나 같다
=
같다
!=
같지 않다
^=
같지 않다
<>
같지 않다
BETWEEN AND
~ 사이에 있는
LIKE
일치하는 문자 패턴 검색
IS NULL
NULL값인지 여부
IN
값 리스트 중 일치하는 값 검색
- ORACLE은 FROM절 -> WHERE절 -> SELECT절 순서로 실행하기 때문에 WHERE 절에 컬럼 별칭 사용하면 에러남
(2) 문자와 날짜 검색
(ex) 이름이 SCOTT인 사원의 이름, 월급, 직업, 입사일, 부서번호
SELECT ename, sal, job, hiredate, deptno
FROM emp
WHERE ename = 'SCOTT';
(ex) 81년 11월 17일에 입사한 사원의 이름과 입사일
SELECT ename, hiredate
FROM emp
WHERE hiredate = '81/11/17';
- 현재 접속한 세션의 날짜 형식에 맞춰 작성
# 현재 접속한 세션의 날짜 형식 확인
SELECT *
FROM NLS_SESSION_PARAMETERS
WHERE PARAMETER = 'NLS_DATE_FORMAT';
# 현재 접속한 세션의 파라미터 변경
ALTER SESSION SET NLS_DATE_FORMAT = 'YY/MM/DD';
9. 산술 연산자 배우기 (*, /, +, -)
(ex) 연봉이 36000 이상인 사람들의 이름과 연봉 출력
SELECT ename, sal*12 as 연봉
FROM emp
WHERER sal*12 >= 36000;
(ex) 부서 번호가 10번인 사람들의 이름, 월급, 커미션, 월급 + 커미션 출력
SELECT ename, sal, comm, sal + comm
FROM emp
WHERE deptno = 10;
- 산술식의 컬럼값이 NULL인 경우 결과값도 NULL - NVL함수: 컬럼값이 NULL이면 0으로 출력하는 함수
10. 비교연산자 배우기
(1) <, >, <=, >=, !=, ^=, <>, =
(ex) 월급이 1200 이하인 사원들의 이름, 월급, 직업, 부서 번호 출력
SELECT ename, sal, job, deptno
FROM emp
WHERE sal <= 1200;
(2) BETWEEN AND
(ex) 월급이 1000에서 3000 사이인 사원들의 이름과 월급 출력
SELECT ename, sal
FROM emp
WHERE sal BETWEEN 1000 AND 3000;
SELECT ename, sal
FROM emp
WHERE (sal >= 1000 AND sal <= 3000);
- BETWEEN 하한값 AND 상한값
# 월급이 1000에서 3000 사이가 아닌 사원들
SELECT ename, sal
FROM emp
WHERE sal NOT BETWEEN 1000 AND 3000;
SELECT ename, sal
FROM emp
WHERE (sal < 1000 AND sal > 3000);
(ex) 1982년도에 입사한 사원들의 이름과 입사일 출력
SELECT ename, hiredate
FROM emp
WHERE hiredate BETWEEN '1982/01/01' AND '1982/12/31';
(3) LIKE
(ex) 이름의 첫 글자가 S인 사원들의 이름과 월급 출력
SELECT ename, sal
FROM emp
WHERE ename LIKE 'S%';
- % : 와일드 카드. 0개 이상의 임의의 문자와 일치 -> 'LIKE' 연산자와 함께 쓸 경우!
(ex) 이름 두번째 글자가 M인 사원의 이름 출력
SELECT ename
FROM emp
WHRERE ename LIKE '_M%';
- _ : 언더바. 한 자리수의 어떤 철자. 하나의 문자와 일치
(ex) 이름의 끝 글자가 T인 사원의 이름 출력
SELECT ename
FROM emp
WHERE ename LIKE '%T';
(ex) 이름에 A 포함하고 있는 사원들의 이름 출력
SELECT ename
FROM emp
WHERE ename LIKE '%A%';
(4) IS NULL
- NULL : 데이터가 할당되지 않은 상태. 알 수 없는 값. -> = 연산자로 비교 불가
# 커미션이 NULL인 사원들의 이름과 커미션 출력
SELECT ename, comm
FROM emp
WHERE comm IS NULL;
(5) IN
(ex) 직업이 salesman, analyst, manager인 사원들의 이름, 월급, 직업 출력
SELECT ename, sal, job
FROM emp
WHERE job IN ('SALESMAN', 'ANALYST', 'MANAGER');
- = 연산자는 하나의 값만 조회, IN 연산자는 여러 리스트의 값 조회 가능
11. 논리 연산자 배우기 (AND, OR, NOT)
(ex) 직업이 SALESMAN이고 월급이 1200 이상인 사원들의 이름, 월급 직업
SELECT ename, sal, job
FROM emp
WHERE job = 'SALESMAN' AND sal >= 1200;
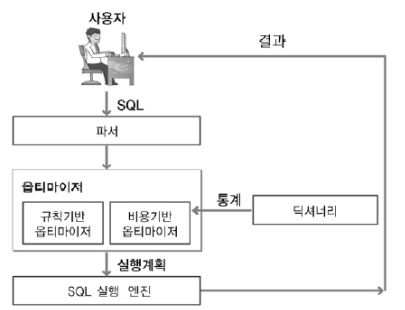
3) 사용자가 발생한 SQL과 그 실행계획시 라이브러리캐시(프로시저캐시)에 캐싱되어 있는지 확인
4) 캐싱되어 있다면 소프트파싱, 캐싱되어있지 않다면 하드파싱
으로 구성된다.
* 소프트파싱: SQL과 실행계획을 캐시에서 찾아 곧바로 실행단계로 넘어가는 경우
* 하드파싱: SQL과 실행계획을 캐시에서 찾지 못해 최적화 과정을 거치고나서 실행단계로 넘어가는 경우
* 라이브러리캐시는 해시구조로 엔진에서 관리된다. SQL마다 해시값에 따라 여러 해시 버킷으로 나뉘며 저장되고, SQL을 찾을 때는 SQL 문장을 해시 함수에 적용하여 반환되는 해시값을 이용해서 해시 버킷을 탐색한다.
2. 규칙기반 옵티마이저 (RBO)
실행계획을 정해진 룰에 따라 만든다.
룰은 데이터베이스 엔진마다 여러 가지가 있다.
예를 들어서 오라클의 RBO는 다음과 같다.
순위
액세스 경로
1
Single Row by Rowid
2
Single Row by Cluster Join
3
Single Row by Hash Cluster Key with Unique or Primary Key
4
Single Row by Unique or Primary Key
5
Clustered Join
6
Hash Cluster Key
7
Indexed Cluster Key
8
Composite Index
9
Single-Column Indexes
10
Bounded Range Search on Indexed Columns
11
Unbounded Range Search on Indexed Columns
12
Sort Merge Join
13
MAX or MIN of Indexed Column
14
ORDER BY on Indexed Column
15
Full Table Scan
자세한 과정은 잘 모르겠지만, 크게 보면 엑세스를 할 때에 인덱스를 이용하느냐, 전체 테이블을 스캔하느냐 등으로 나눌 수 있다. 1번부터 순서대로 맞는 경우에 진행하며, 아래로 갈수록 data가 흐트러져서 저장되기 때문에 비용이 많이 든다.
그리고 요즘에는 대부분 RBO보다 CBO를 이용한다.
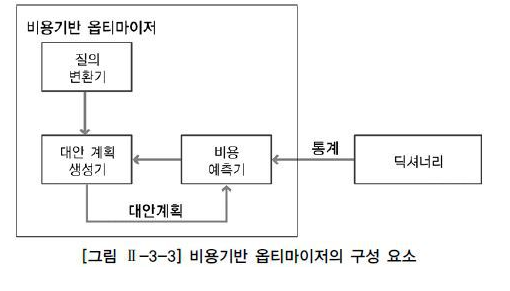
3. 비용기반 옵티마이저 (CBO)
비용을 기반으로 최적화를 수행하는 방식이다. 이때 비용이란 쿼리를 수행하는데 소요되는 일의 양 또는 시간 예상치이다.
딕셔너리에서 테이블과 인덱스를 통해 레코드 개수, 블록 개수, 평균 행 길이, 칼럼 값의 수, 칼럼 값 분포, 인덱스 높이, 클러스터링 팩터 등의 통계값을 기반으로 비용을 예측하는 방식이다. 이 예측된 비용에 따라 최적의 실행 계획을 도출한다. 최근에는 추가적으로 하드웨어적 특성을 반영한 시스템 통계정보 (CPU 속도, 디스크 I/O 속도 등)까지 이용한다.
4. SQL 실행계획
실행 계획은 SQL에서 요구한 사항을 처리하기 위한 절차와 방법을 의미한다. 즉, SQL을 어떤 순서로 어떻게 진행할 지 결정한다는 것이다.
실행 계획의 구성요소는 다음 다섯 가지가 있다.
조인 순서 (Join Order) : JOIN 수행에서 어떤 테이블이 먼저 조회되는가
조인 기법 (Join Method) : loop, merge, sorting 등
액세스 기법 (Access Method) : Index / Full table 등
최적화 정보 (Optimization Information) : 알고리즘
연산 (Operation) : 크다, 작다, 함수, MAX, MIN 등
5. INDEX
INDEX는 데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조이다.
CREATE INDEX IDX_### ON db, table (column);
ALTER TABLE db.table ADD INDEX IDX_###;
두 코드 모두 column에 대한 INDEX를 생성하는 코드이다.
ALTER TABLEdb.tableDROP INDEXIDX_###;
테이블에 있는 인덱스를 삭제하는 코드이다.
EXPLAIN SELECT * FROM db.table;
실행 계획을 확인하는 코드이다.
예제)
DESC kaggle.titanic;
EXPLAIN SELECT * FROM kaggle.titanic WHERE `Age` = 23;
>> Age가 23인 데이터를 찾기 위해 418개의 rows를 모두 검색하는 것이 플랜임을 알 수 있다.
[INDEX 생성 후]
DESCkaggle.titanic;
Age에 인덱스가 생성된 것을 확인할 수 있다.
EXPLAIN SELECT*FROMkaggle.titanicWHERE`Age` = 23;
>> IDX_AGE를 사용해서 reference를 통해서 쿼리를 실행하는 것이 플랜임을 알 수 있다.
create database kaggle;
use kaggle;
CREATE TABLE `org_test_import` (
`PassengerId` int NULL,
`Pclass` int NULL,
`Name` text,
`Sex` text,
`Age` text,
`SibSp` int NULL,
`Parch` int NULL,
`Ticket` text,
`Fare` text,
`Cabin` text,
`Embarked` text
) ENGINE=InnoDB ;
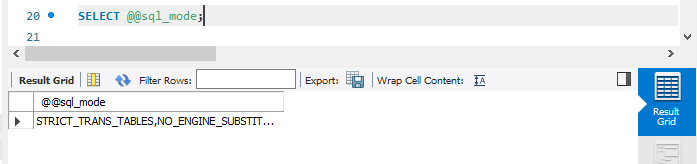
SELECT @@sql_mode;
set @@sql_mode = "";
CREATE TABLE `test` (
`PassengerId` int NULL,
`Pclass` int NULL,
`Name` text,
`Sex` text,
`Age` double,
`SibSp` int NULL,
`Parch` int NULL,
`Ticket` text,
`Fare` double,
`Cabin` text,
`Embarked` text
) ENGINE=InnoDB ;
INSERT INTO `kaggle`.`test` (
`PassengerId`,
`Pclass`,
`Name`,
`Sex`,
`Age`,
`SibSp`,
`Parch`,
`Ticket`,
`Fare`,
`Cabin`,
`Embarked` )
SELECT `org_test_import`.`PassengerId`,
`org_test_import`.`Pclass`,
`org_test_import`.`Name`,
`org_test_import`.`Sex`,
`org_test_import`.`Age`,
`org_test_import`.`SibSp`,
`org_test_import`.`Parch`,
`org_test_import`.`Ticket`,
`org_test_import`.`Fare`,
`org_test_import`.`Cabin`,
`org_test_import`.`Embarked`
FROM `kaggle`.`org_test_import`;
select age from `org_test_import`;
select age from `kaggle`.`test`;
SELECT * FROM `gender_submission`;
ALTER TABLE `test` ADD PRIMARY KEY (`PassengerId`);
ALTER TABLE `gender_submission` ADD PRIMARY KEY (`PassengerId`);
ALTER TABLE `gender_submission` ADD FOREIGN KEY (`PassengerId`) REFERENCES `test` (`PassengerId`);
SELECT COUNT (*) FROM `gender_submission`;
SELECT COUNT (*) FROM `test`;
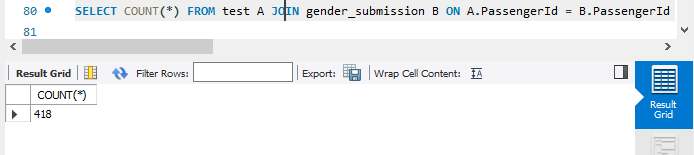
SELECT COUNT (*) FROM test A JOIN gender_submission B ON A.PassengerId = B.PassengerId;
CREATE TABLE `titanic` (
`PassengerId` int not NULL,
`Pclass` int NULL,
`Name` text,
`Sex` text,
`Age` double,
`SibSp` int NULL,
`Parch` int NULL,
`Ticket` text,
`Fare` double,
`Cabin` text,
`Embarked` text,
`Survived` int ,
primary key (`PassengerId` )
) ENGINE=InnoDB ;
INSERT INTO `kaggle`.`titanic` (
`PassengerId`,
`Pclass`,
`Name`,
`Sex`,
`Age`,
`SibSp`,
`Parch`,
`Ticket`,
`Fare`,
`Cabin`,
`Embarked`,
`Survived`)
SELECT
A.`PassengerId`,
`Pclass`,
`Name`,
`Sex`,
`Age`,
`SibSp`,
`Parch`,
`Ticket`,
`Fare`,
`Cabin`,
`Embarked`,
B.`Survived`
FROM test A JOIN gender_submission B ON A.PassengerId = B.PassengerId ;
SELECT COUNT(*) FROM `kaggle`.`titanic` ;
SELECT * FROM `kaggle`.`titanic` ;
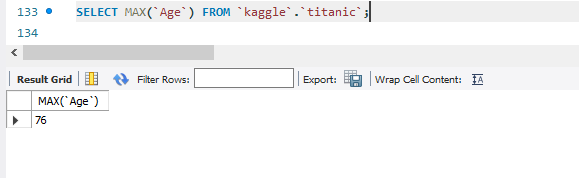
SELECT MAX(`Age`) FROM `kaggle`.`titanic`;
SELECT MIN(`Age`) FROM `kaggle`.`titanic` WHERE `Age` > 0;
SELECT AVG(`Age`), COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0;
SELECT sum(`Fare`) FROM `kaggle`.`titanic`;
SELECT `Name`, `Pclass`, `Sex`, `Age` FROM `kaggle`.`titanic` ORDER BY 1 ; ##첫번째 컬럼 기준으로 오름차순 (Name)
SELECT `Name`, `Pclass`, `Sex`, `Age` FROM `kaggle`.`titanic` ORDER BY 3 ;
SELECT `Name`, `Pclass`, `Sex`, `Age` FROM `kaggle`.`titanic` ORDER BY `Name` DESC ;
#10개 제한된 행 조회
SELECT * FROM `kaggle`.`titaic` WHERE `Name` LIKE 'A%' LIMIT 10; #이름이 A로 시작하는 row 10개
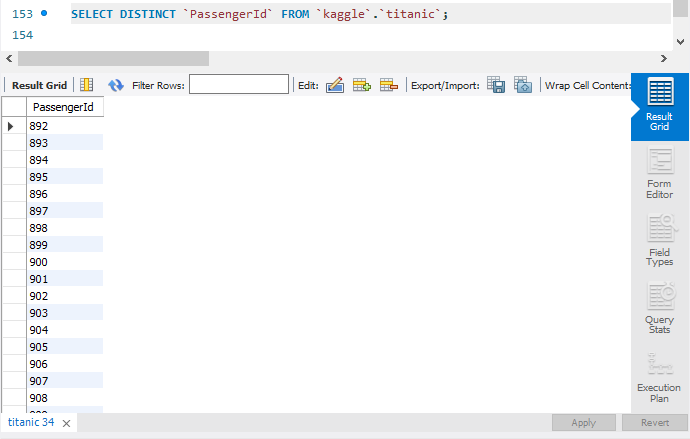
##`PassengerId` 유일한 값만 조회
SELECT DISTINCT `PassengerId` FROM `kaggle`.`titanic`;
SELECT DISTINCT `Sex` FROM `kaggle`.`titanic`;
SELECT `Sex`, COUNT(*) FROM `kaggle`.`titanic` GROUP BY 1; #첫번째 컬럼을 그룹화해서 카운트
SELECT `Sex`, COUNT(*) CNT FROM `kaggle`.`titanic` GROUP BY `Sex` HAVING CNT > 200; #count = cnt, cnt가 200이상인 그룹의 카운트 수
SELECT `Sex`, `survived`, COUNT(*) FROM `kaggle`.`titanic` GROUP BY `Sex`, `Survived` ;
##floor = 반올림
#연령 밴드별 조회
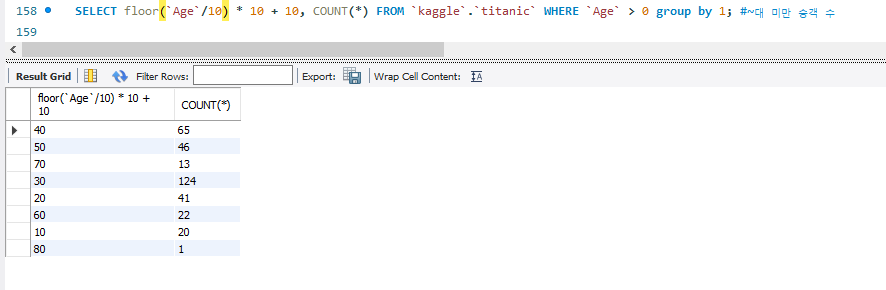
SELECT floor(`Age`/10) * 10 + 10, COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0 group by 1; #~대 미만 승객 수
SELECT floor(`Age`/10) * 10 + 10, COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0 group by 1 order by 1;
SELECT floor(`Age`/10) * 10 + 10, COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0 group by 1 order by 1 desc;
SELECT floor(`Age`/10) * 10 + 10, `survived`, COUNT(*) CNT FROM `kaggle`.`titanic`
WHERE `Age` > 0 group by 1, 1 HAVING CNT > 40 order by 1 desc, 2 desc;
#서브쿼리
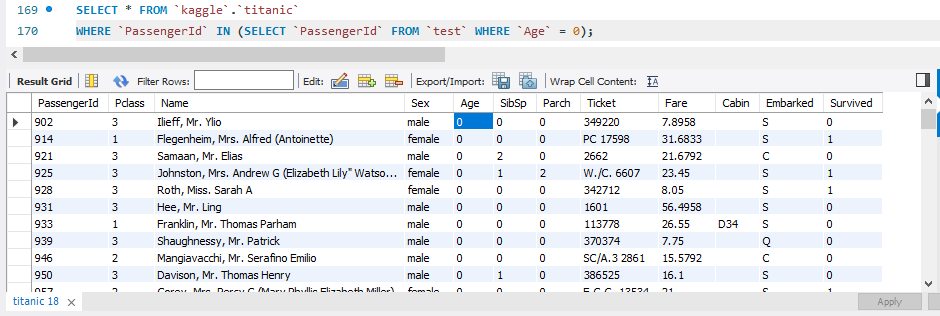
SELECT * FROM `kaggle`.`titanic`
WHERE `PassengerId` IN (SELECT `PassengerId` FROM `test` WHERE `Age` = 0); # NULL 값이었던 passengerId(age=0)를 titanic table에서 조회해라
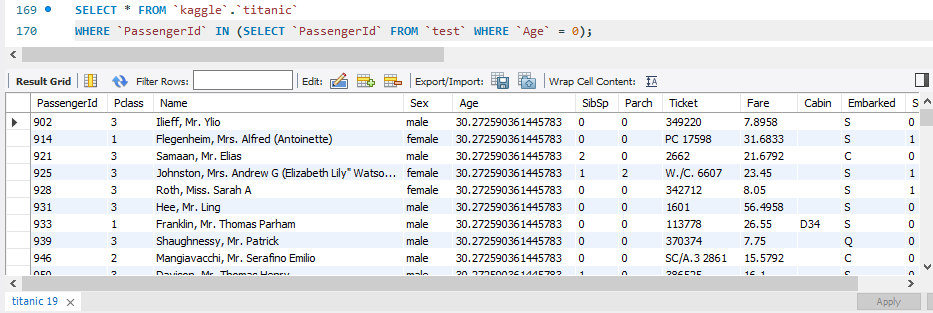
UPDATE `kaggle`.`titanic`
SET `Age` = 30.272590361445783
WHERE `PassengerId` IN (SELECT `PassengerId` FROM `test` WHERE `Age` = 0) ;
SELECT COUNT(*) FROM `gender_submission` ;
SELECT COUNT(*) FROM `test` ;
count( ) 는 투플의 개수를 세는 함수이다. FROM - 뒤에 WHERE - 을 붙여 조건을 걸 수 있다.
정확한 표현인지는 모르겠지만..
예제에 나온 SELECT COUNT(*) FROM 'gender_submission'; 은 'gender_submission' 테이블에 있는 전체 투플 수 (rows)를 count해준다.
SELECT COUNT(*) FROM test A JOIN gender_submission B ON A.PassengerId = B.PassengerId ;
'test' 테이블의 'PassengerId'와 'gender_submission'테이블의 'PassengerId'가 같을 경우에, 'test'테이블과 'gender_submission'테이블을 결합한다는 의미이다. 그리고, 그 결합한 것의 투플 수 (row 수)를 세는 코드이다.
두 테이블 다 418개의 투플을 갖고 있기 때문에, 이 결과도 418이 나온다.
CREATE TABLE `titanic` (
`PassengerId` int not NULL,
`Pclass` int NULL,
`Name` text,
`Sex` text,
`Age` double,
`SibSp` int NULL,
`Parch` int NULL,
`Ticket` text,
`Fare` double,
`Cabin` text,
`Embarked` text,
`Survived` int ,
primary key (`PassengerId` )
) ENGINE=InnoDB;
'titanic'이라는 테이블을 생성했다. 이 테이블에는 'test'테이블과 'gender_submission'테이블을 결합하여 저장할 것이다.
INSERT INTO `kaggle`.`titanic`
(`PassengerId`,
`Pclass`,
`Name`,
`Sex`,
`Age`,
`SibSp`,
`Parch`,
`Ticket`,
`Fare`,
`Cabin`,
`Embarked`,
`Survived`)
SELECT
A.`PassengerId`,
`Pclass`,
`Name`,
`Sex`,
`Age`,
`SibSp`,
`Parch`,
`Ticket`,
`Fare`,
`Cabin`,
`Embarked`,
B.`Survived`
FROM test A JOIN gender_submission B ON A.PassengerId = B.PassengerId ;
insert into, select, from join on 함수를 이용하여,
'test'테이블의 PassengerId값과 'gender_submission'테이블의 PassengerId값이 같을 경우,
두 테이블을 결합하여 각각의 값들을 'titanic' 테이블에 저장해 하나의 테이블로 만드는 것이다.
SELECT COUNT(*) FROM `kaggle`.`titanic` ;
'titanic' 테이블의 투플 수를 보여준다.
'gender_submission'의 'PassengerId'값은 외래키로, 'test' 테이블의 값을 참조한 것이기 때문에 모든 값이 같다.
따라서 모든 투플이 결합하여 저장되었기 때문에 count 수는 동일하게 418이다.
SELECT * FROM `kaggle`.`titanic` ;
'titanic' 테이블의 모든 값을 보여준다.
SELECT MAX(`Age`) FROM `kaggle`.`titanic`;
MAX함수는 이 속성에서 가장 큰 값을 보여준다.
SELECT MIN(`Age`) FROM `kaggle`.`titanic` WHERE `Age` > 0;
MIN함수는 반대로 이 속성에서 가장 크기가 작은 값을 보여준다.
WHERE은 조건문 느낌으로, 'Age'값이 0보다 큰 범위에서 가장 작은 값을 보여달라는 의미이다.
NULL값이 0으로 변환되었기 때문에 이 조건을 추가한 것이다.
아마 개월 수로 따져서 이러한 값이 들어가있는 것 같다.
SELECT AVG(`Age`), COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0;
AVG는 평균을 보여주는 값이다.
COUNT는 뒤에 WHERE `Age` > 0 의 조건이 붙었기 때문에 'Age' 값이 0보다 큰 투플의 개수를 알려준다.
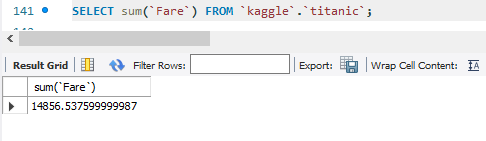
SELECT sum(`Fare`) FROM `kaggle`.`titanic`;
sum은 해당 속성의 투플 값들을 모두 더한 값을 반환한다.
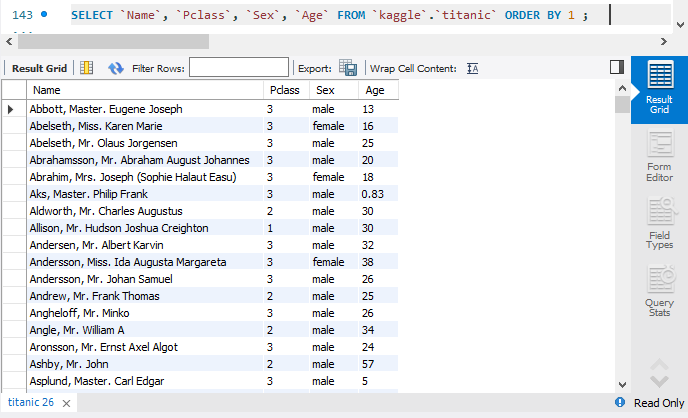
SELECT `Name`, `Pclass`, `Sex`, `Age` FROM `kaggle`.`titanic` ORDER BY 1 ;
ORDER BY 1은 SELECT 뒤에 나열된 4개의 속성들 중 첫번째 속성을 기준으로 오름차순 정렬하여 반환하라는 의미이다.
name 기준으로 오름차순 정렬된 것을 볼 수 있다
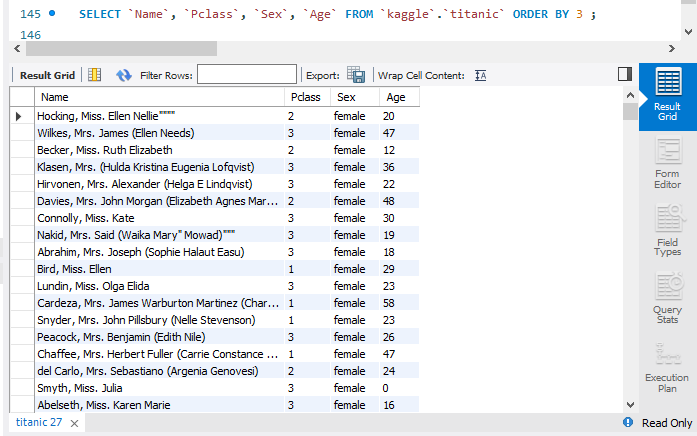
SELECT `Name`, `Pclass`, `Sex`, `Age` FROM `kaggle`.`titanic` ORDER BY 3 ;
마찬가지로 3번째 속성인 'Sex'를 기준으로 오름차순 정렬하라는 의미이다.
sex 기준으로 오름차순 정렬된 것을 볼 수 있다
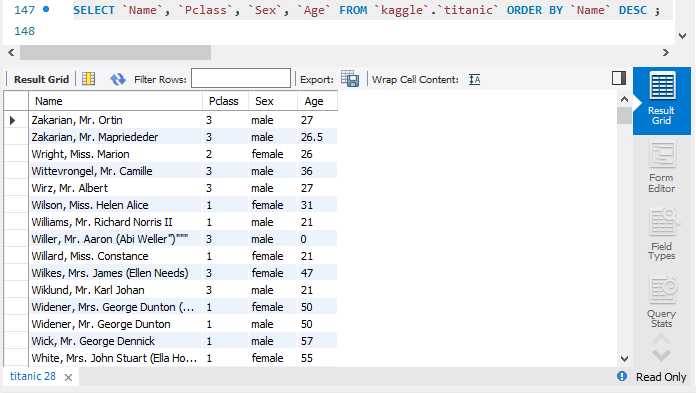
SELECT `Name`, `Pclass`, `Sex`, `Age` FROM `kaggle`.`titanic` ORDER BY `Name` DESC ;
ORDER BY - DESC는 해당 속성 기준으로 내림차순 정렬하라는 의미이다.
그리고 ORDER BY 뒤에 숫자보다는 이와 같이 속성명을 직접 써주는 것이 더욱 직관적이다.
name 기준으로 내림차순 정렬된 것을 볼 수 있다
SELECT * FROM `kaggle`.`titanic` WHERE `Name` LIKE 'A%' LIMIT 10;
LIKE 'A%' 은 'Name' 값들 중에서 A로 시작하는 값을 반환하라는 조건이다.
LIMIT 10은 그 중에서 상위 10개만 반환하라는 조건이다. 아마 조건에 대한 오름차순 정렬 후 10개인 것 같다.
SELECT DISTINCT `PassengerId` FROM `kaggle`.`titanic`;
DISTINCT 는 해당 속성의 값들 중 유일한 값만 조회하는 함수이다.
'PassengerId'의 경우 기본키로, 모든 투플이 유일하게 갖는 값이기 때문에 모든 값이 반환된다.
SELECT DISTINCT `Sex` FROM `kaggle`.`titanic`;
마찬가지로 'Sex' 의 값들 중 유일한 값들만 반환한다.
이 경우 투플 값이 male과 female 두 가지로 나뉘기 때문에 두개의 값만 반환된다.
SELECT `Sex`, COUNT(*) FROM `kaggle`.`titanic` GROUP BY 1;
GROUP BY는 해당 속성 값들을 그룹화하는 함수이다. 이 경우 'Sex'는 male과 female의 두개의 그룹으로 나뉠 것이다.
여기에 COUNT함수를 적용하면, 각각의 그룹에 속하는 투플 수를 보여준다.
SELECT `Sex`, COUNT(*) CNT FROM `kaggle`.`titanic` GROUP BY `Sex` HAVING CNT > 200;
위의 코드처럼 'Sex' 속성을 그룹화하여 count한 뒤, HAVING (조건) 을 이용해서 count값이 200보다 큰 값만 출력되도록 하는 코드이다.
count값을 CNT로 지정해서 HAVING 조건을 이용한 것이 특징이다.
위의 결과를 보면 male은 count값이 266, female은 152이기 때문에 male의 값만 출력되었다.
SELECT `Sex`, `survived`, COUNT(*) FROM `kaggle`.`titanic` GROUP BY `Sex`, `Survived` ;
'Sex' 속성과 'survived' 속성을 각각 그룹화하여 count값을 출력하는 코드이다.
이 값을 보면 남자는 모두 생존하지 못했고, 여자는 모두 생존했음을 알 수 있다.
SELECT floor(`Age`/10) * 10 + 10, COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0 group by 1;
floor는 반올림을 해주는 함수이다. 연령대별로 몇 명의 사람이 있는지 알아보기 위해서 'Age'를 10으로 나눈 값을 반올림하고, 10을 곱한 뒤, 0~9의 값이 있기 때문에 10을 더해준다. 그러면 이 값 미만의 사람들이 몇 명있는지 알아볼 수 있다.
SELECT floor(`Age`/10) * 10 + 10, COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0 group by 1 order by 1;
위의 값들을 오름차순으로 정렬하는 코드이다.
SELECT floor(`Age`/10) * 10 + 10, COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0 group by 1 order by 1 desc;
위의 값들을 내림차순으로 정렬하는 코드이다.
SELECT floor(`Age`/10) * 10 + 10, `survived`, COUNT(*) CNT FROM `kaggle`.`titanic`
WHERE `Age` > 0 group by 1, 1 HAVING CNT > 40 order by 1 desc, 2 desc;
위의 코드처럼 'Age'를 연령대 별로 나누고, 그 중 count값이 40보다 큰 값에 대해 'Age' 값과 'survived' 값을 각각 내림차순으로 정렬하는 코드이다.
#서브쿼리: 하나의 SQL문 안에 들어있는 또 다른 SQL문(쿼리)! 괄호( )로 나타낸다.
#서브쿼리가 조건절이 됨. 결과에 해당하는 데이터를 조건으로 해서 메인쿼리 실행.
SELECT * FROM `kaggle`.`titanic`
WHERE `PassengerId` IN (SELECT `PassengerId` FROM `test` WHERE `Age` = 0);
서브쿼리// 'test' 테이블에서 'Age'값이 0인 'PassengerId'를 찾는다.
메인쿼리// 그 'PassengerId'를 가진 값의 모든 데이터를 출력한다. ('PassengerId'가 JOIN으로 연결되어있기 때문에 같은 값임)
UPDATE `kaggle`.`titanic`
SET `Age` = 30.272590361445783
WHERE `PassengerId` IN (SELECT `PassengerId` FROM `test` WHERE `Age` = 0) ;
위의 코드대로 'Age' 값이 0인 데이터를 찾아서 그 값들의 'Age' 값을 평균인 30.272590361445783로 업데이트하는 코드이다.
업데이트한 후 위의 코드를 다시 실행시켜보면 'Age' 값이 모두 변경된 것을 볼 수 있다.
위의 코드는 'test' 테이블에서 'Age' 값이 0인 투플을 찾은 것이기 때문에 'titanic' 테이블에서 값을 변경한 뒤 다시 확인하기에 좋았다.
unsigned는 부호가 없다는 뜻이다. 예를 들어 tinyint의 경우, (signed) tinyint의 범위는 -128~127이며,
unsigned tinyint의 범위는 0~255이다.
NULL, NOT NULL은 NULL값이 될 수 있냐 없냐를 정해주는 것이다. 예제의 경우 학번과 이름은 NULL값이 될 수 없도록 했다.
varchar( )의 괄호 속 숫자는 최대로 들어갈 수 있는 byte 값이다.
`leave_yn`는 휴학여부 속성으로 0과 1로 구분되고, 투플값이 없을 경우 default 값은 0이 들어가도록 했다.
`last_update`는 업데이트 시각으로, 직접 적는 것이 아니라 CURRNET_TIMESTAMP를 이용하여 자동으로 저장된다.
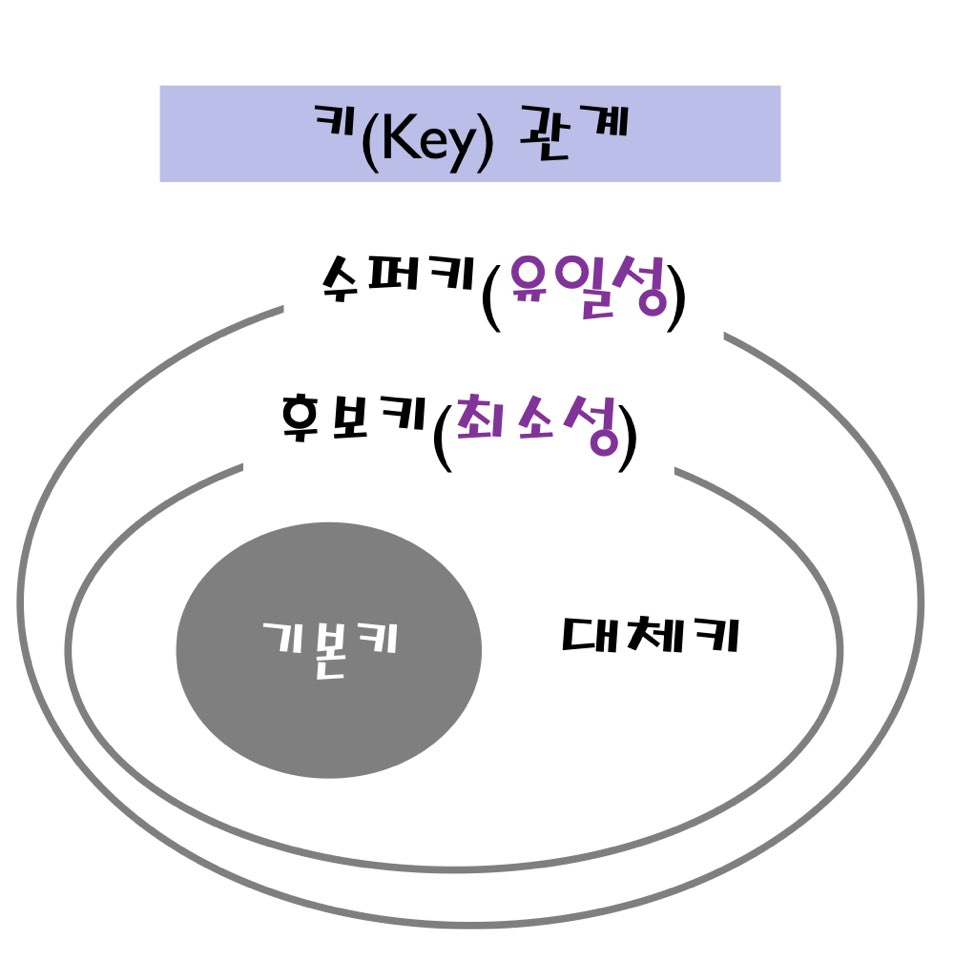
이 테이블의 기본키는 `student_id`로, 학번만 가지고도 투플들을 구분할 수 있다는 뜻이다.
MySQL의 스토리지 엔진으로 주로 MyISAM과 InnoDB가 사용된다.
스토리지 엔진은 데이터베이스 엔진이라고도 불리며, RDBMS가 데이터베이스에 대해 데이터를 삽입, 추출, 업데이트, 삭제하는 데 사용하는 기본 소프트웨어 컴포넌트이다.
MyISAM은 항상 테이블에 ROW COUNT를 가지고 있기 때문에 SELECT 명령 시 속도가 빠르고, '풀텍스트 인덱스'를 지원하는데, 이는 자연 언어를 이용해 검색할 수 있는 특별한 인덱스로 모든 데이터 문자열의 단어를 저장한다는 것이다. 이때문에 Read only 기능이 많은 서비스일수록 효율적으로 사용할 수 있는 엔진이다. 단점으로는, row level locking을 지원하지 못해서 select, insert, update, delete 명령 시 해당 테이블 전체에 locking이 걸린다는 것이다. 그래서 갱신이 많이 필요한 경우에는 유용하지 못하다.
InnoDB는 MyISAM과 대조적인 엔진으로, 우선 row level locking이 지원된다는 장점이 있고, 트랜잭션 처리가 필요한 대용량 데이터를 다룰 때 효율적이다. 데이터의 변화가 많은 서비스에 적합하다. 또한, 유일하게 외래키를 지원하는 표준적인 스토리지 엔진이다.단점으로는, 풀텍스트 인덱스를 지원하지 않는다는 것이 있다.
주로 InnoDB를 많이 사용한다고 하고, 이번 예제에서도 InnoDB를 사용하였다.
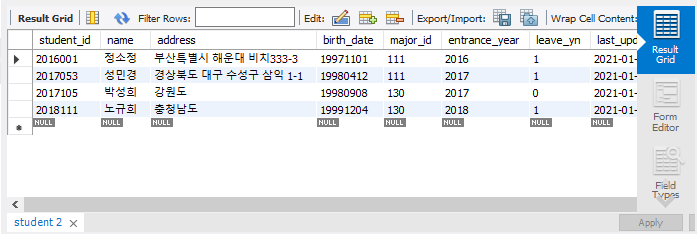
INSERT INTO `university`.`student` (student_id, name, address, birth_date, major_id, enterance_year, leave_yn) VALUES (2016001, '정소정', '서울시 서초구 방배동 911-1', '19971101', 111, 2016, 0), (2017053,'성민경','경상북도 대구 수성구 삼익 1-1','19980412',111,2017,1), (2018111,'노규희','충청남도','19991204',130,2018,1), (2017105,'박성희','강원도','19980908',130,2017,0);
student 테이블에 투플들을 삽입하는 코드이다.
INSERT INTO로 속성을 한 번 나열하고, VALUES를 통해 각각의 개체들을 추가한다.
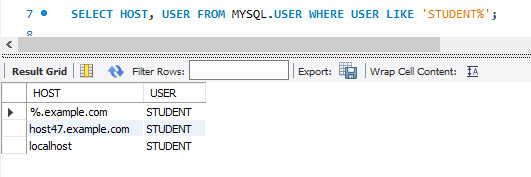
select * from `university`.`student`;
select from은 테이블에서 정보를 가져온다는 뜻이고, *은 테이블에 있는 모든 데이터를 가져온다는 뜻이다.
따라서 이 코드를 실행하면 university.student에 있는 4개의 투플들을 보여준다.
select * from `university`.`student` where student_id = 2016001;
where은 조건의 개념으로, 이 경우에는 학번이 2016001인 투플의 모든 데이터를 가져온다는 뜻이 된다.
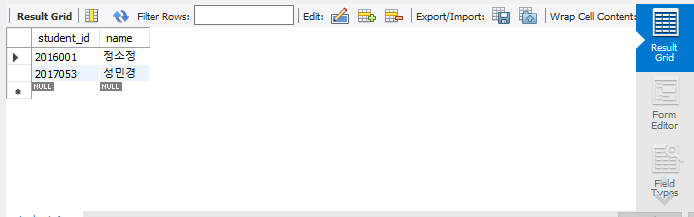
select student_id, name from `university`.`student` where major_id = 111;
이 경우에는 selcet student_id, name 이므로, 전공번호가 111인 투플의 학번과 이름을 가져온다.
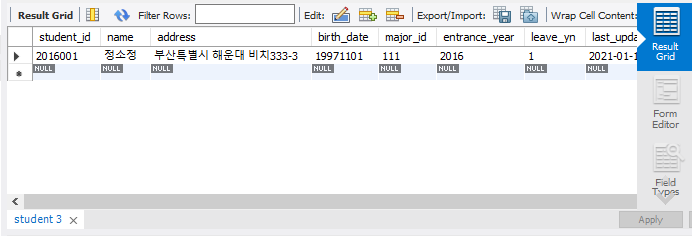
UPDATE `university`.`student` SET address = '부산특별시 해운대 비치333-3', leave_yn = 1 WHERE student_id = 2016001;
update는 말 그대로 테이블을 새로운 정보로 업데이트한다는 뜻이다.
이 경우, 학번이 2016001인 투플의 주소와 휴학여부 정보를 변경하게 된다.
select * from university.student where student_id = 2016001;
DELETE FROM university.student WHERE student_id = 2016001;
select * from university.student where student_id = 2016001;
select * from university.student;
select문은 마찬가지로 정보를 가져오는 코드이고,
DELETE문은 university DB의 student 테이블에서 student_id가 2016001인 투플을 삭제하는 코드이다.
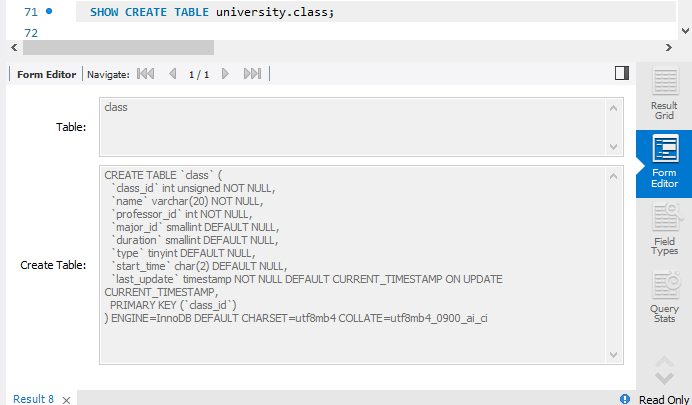
CREATE TABLE `university`.`class` ( `class_id` int unsigned NOT NULL , `name` varchar(20) NOT NULL , `professor_id` int NOT NULL , `major_id` smallint NULL , `duration` smallint NULL , `type` tinyint NULL , `start_time` char(2) NULL, `last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (class_id) ) ENGINE = InnoDB;
두번째로 universityDB 안에 'class'라는 테이블을 생성한 것이다.
속성으로는 class_id, name, professor_id, major_id, duratin, type, start_time, last_update가 있고 각각의 도메인이 달려있다.
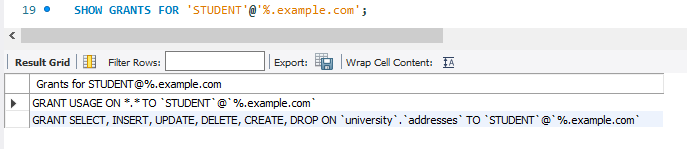
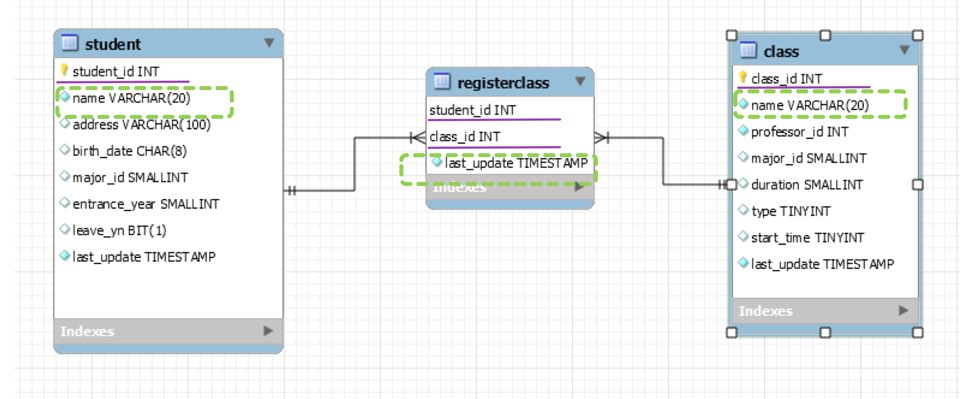
INSERT INTO `university`.`registerClass` (student_id, class_id) VALUES (2017053, 10000), (2017053, 50003);
resigterClass 테이블에 투플들을 생성하는 코드들이다.
코드를 보면 student_id와 class_id 투플값이 모두 student테이블의 student_id와 class테이블의 class_id에 있는 값들인 것을 확인할 수 있다. 외래키를 사용했기 때문이다.
#INSERT INTO `university`.`registerClass` #(student_id, class_id) #VALUES #(2017053, 45003);
이처럼 만약 참조되는 테이블에 없는 값을 value로 입력하면 오류가 뜬다.
SELECTS.NAME, C.NAME, R.last_update #조회할 것 -> 결합할 것 FROM student Sjoin registerClass Ron S.student_id = R.student_id #조건 join class Con R.class_id = C.class_id where S.student_id = 2017053;
SELECT S.NAME, C.NAME, R.last_update FROM student S join registerClass R on S.student_id = R.student_id join class C on R.class_id = C.class_id where S.student_id = 2018111;
SELECT S.NAME, C.NAME, R.last_update FROM student S join registerClass R on S.student_id = R.student_id join class C on R.class_id = C.class_id where S.student_id = 2017105;
join은 릴레이션 간의 조합을 검색하는 키워드이다.
예를 들어, 첫번째 예시는 학번이 2017053인 학생의 이름(from S)과 수강한 과목(C), 수강신청시간(R)을 조회하는 코드이다.
우선 join 다음에 나오는 on은 두 테이블이 결합할 조건을 의미한다.
이 예제에서는 student테이블의 student_id와 registerClass테이블의 student_id가 같을 경우,
student테이블의 name과 class테이블의 name과 registerClass테이블의 last_update를 결합한다는 의미이다.