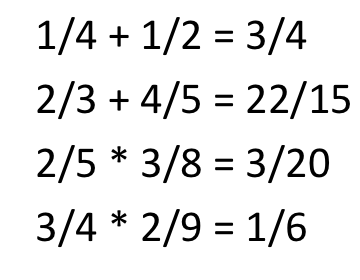[수업출처] 숙명여자대학교 소프트웨어학부 유석종교수님 자료구조 수업 & [파이썬으로 배우는 자료구조 프로그래밍]
* 수강생이 혼자 푼 답을 기록한 것으로 정답이 아닐 수 있습니다 😁
1.
l = [21, 7, 40, 29, 11, 5, 90, 78, 64, 15, 88]
max = 0
min = 1000
for i in range(len(l)):
if l[i] > max:
max = l[i]
if l[i] < min:
min = l[i]
print((min, max))
(5, 90)
2.
def mul(n, m):
l = []
for i in range(1, n):
if i % m == 0:
l.append(i)
return l
print(mul(10, 3))
[3, 6, 9]
3.
def gcd(a, b):
while a % b != 0:
a, b = b, a % b
return b
def fraction(num):
down = 10**len(str(num))
up = num * down
common = gcd(up, down)
new_up = int(up // common)
new_down = int(down // common)
print(new_up, '/', new_down)
fraction(3.14) # 157/50
4.
def palindrome(string):
while len(string) > 1:
if string[0] != string[-1]:
return False
else:
string = string[1:-1]
return True
palindrome('abnnba') # True
palindrome('sdfg') # False
5.
l = [1]
num = 1
for i in range(14):
num += 3
l.append(num)
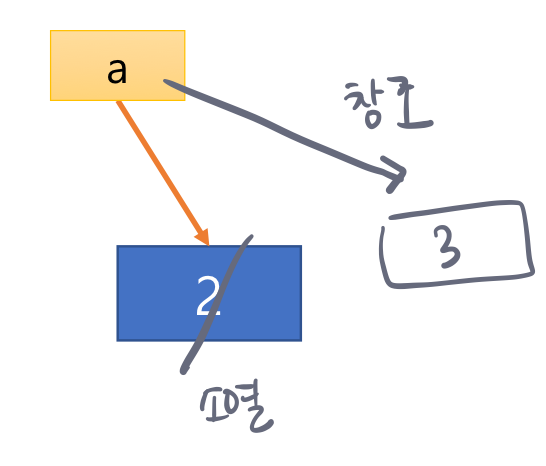
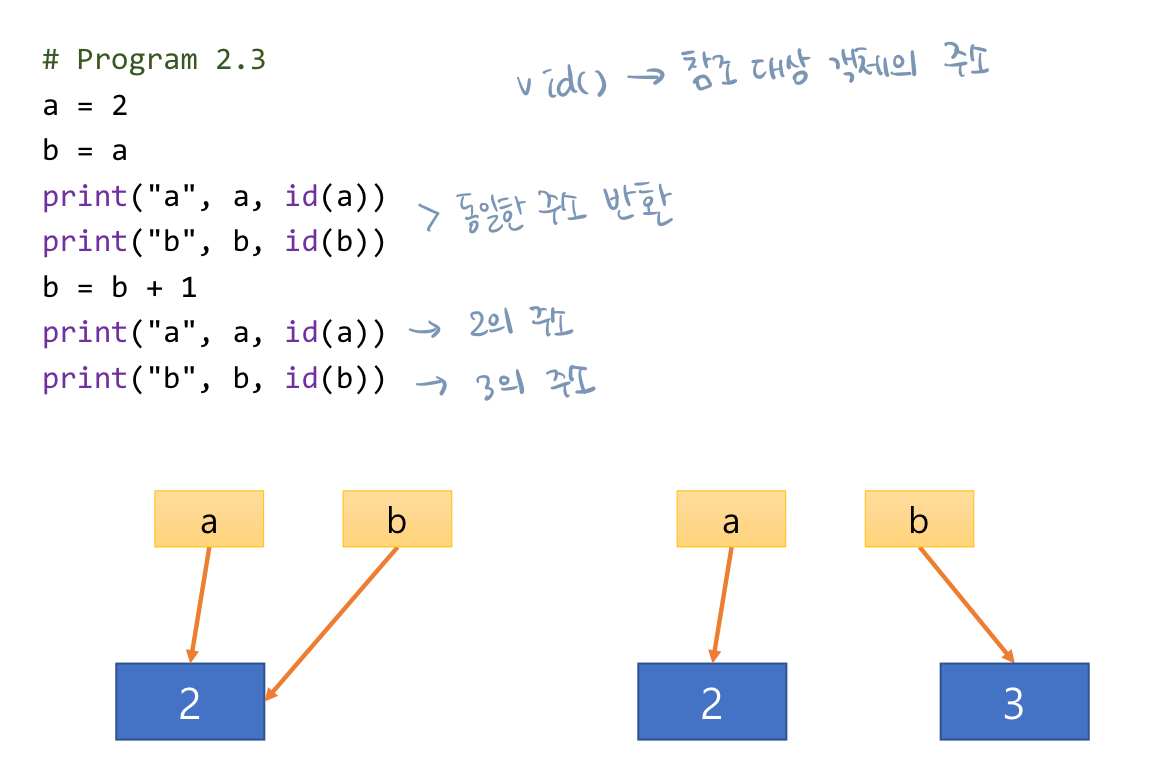
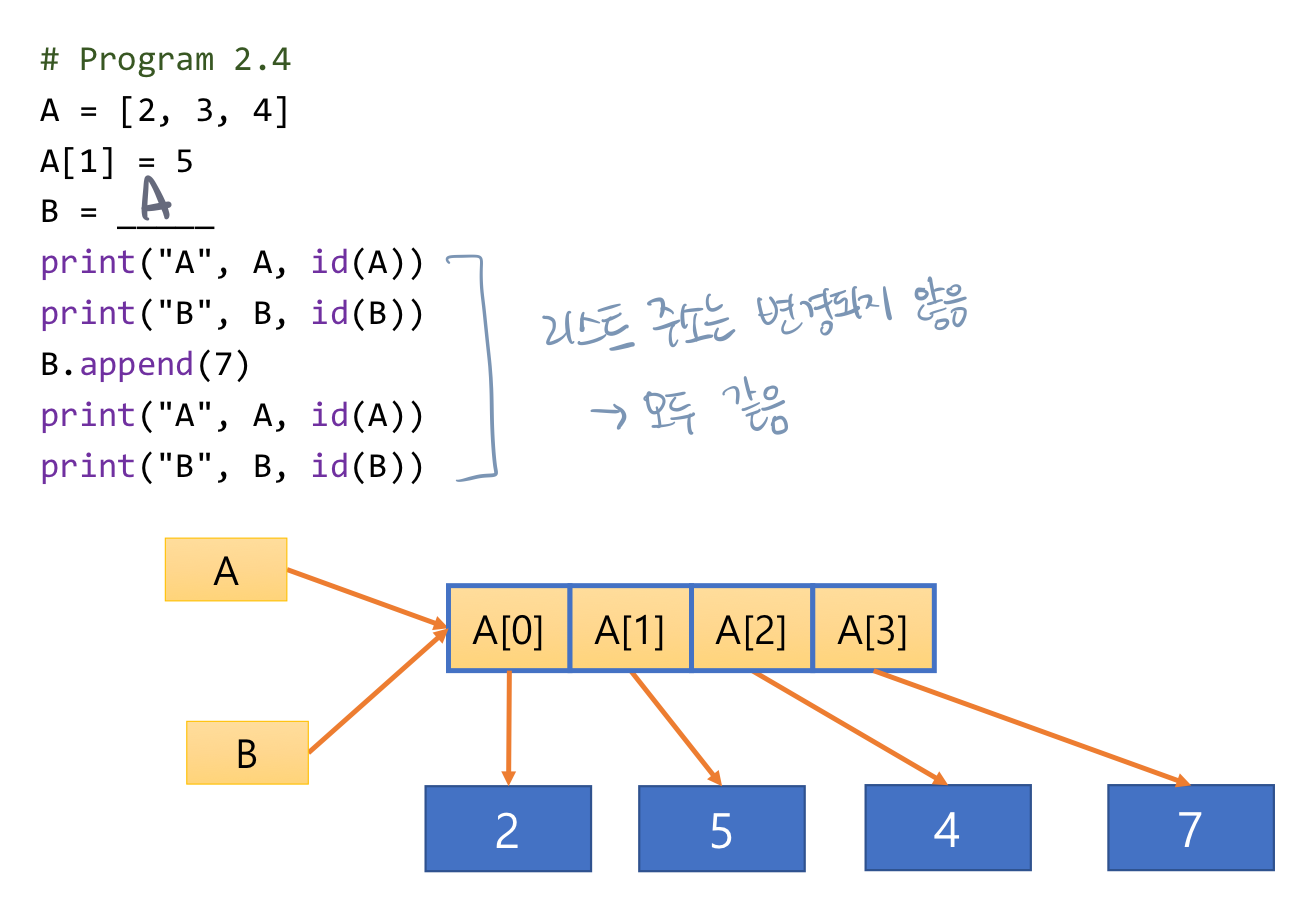
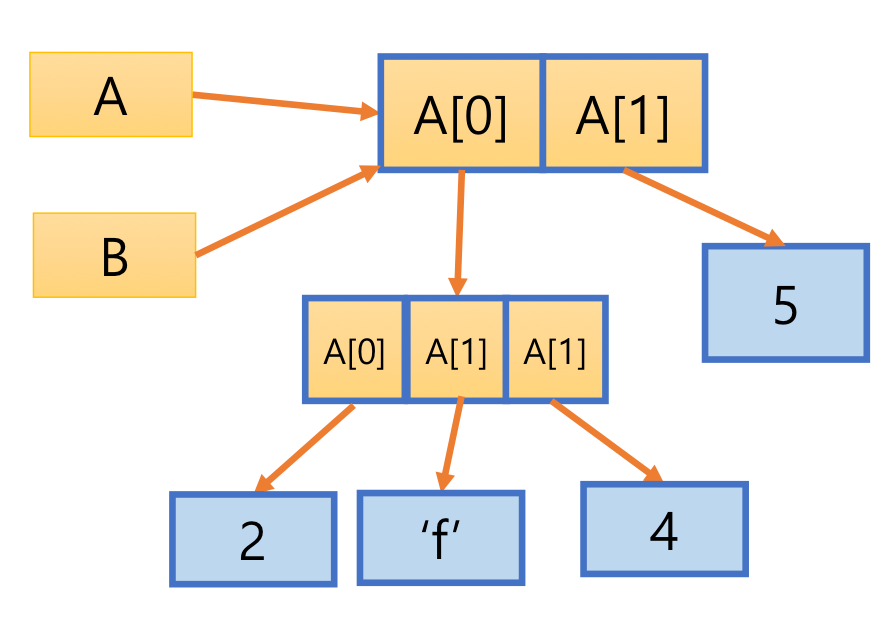
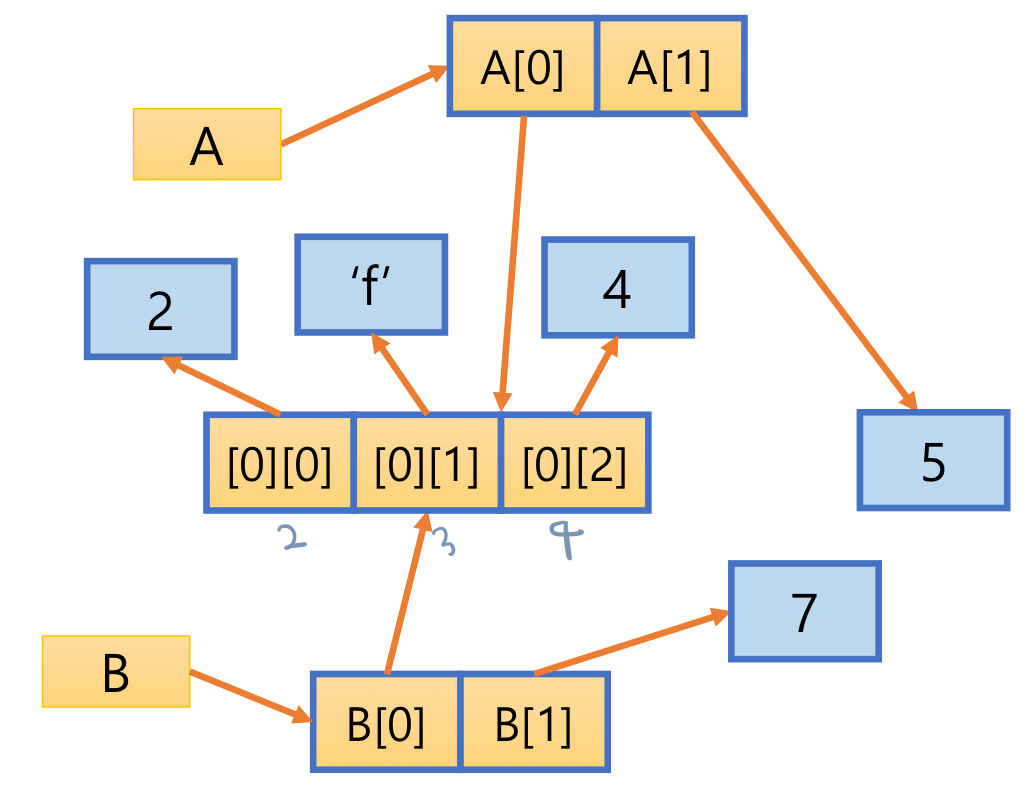
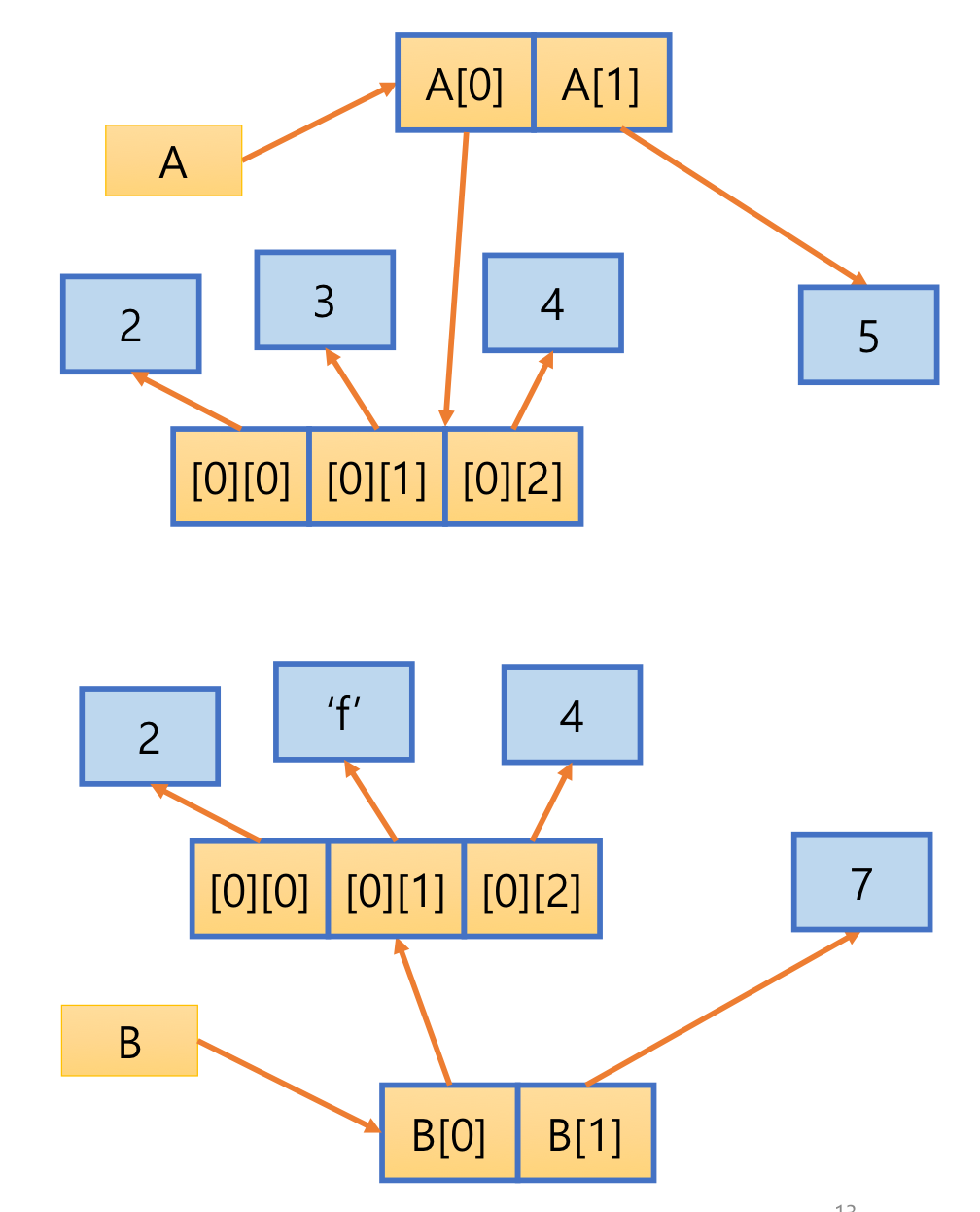
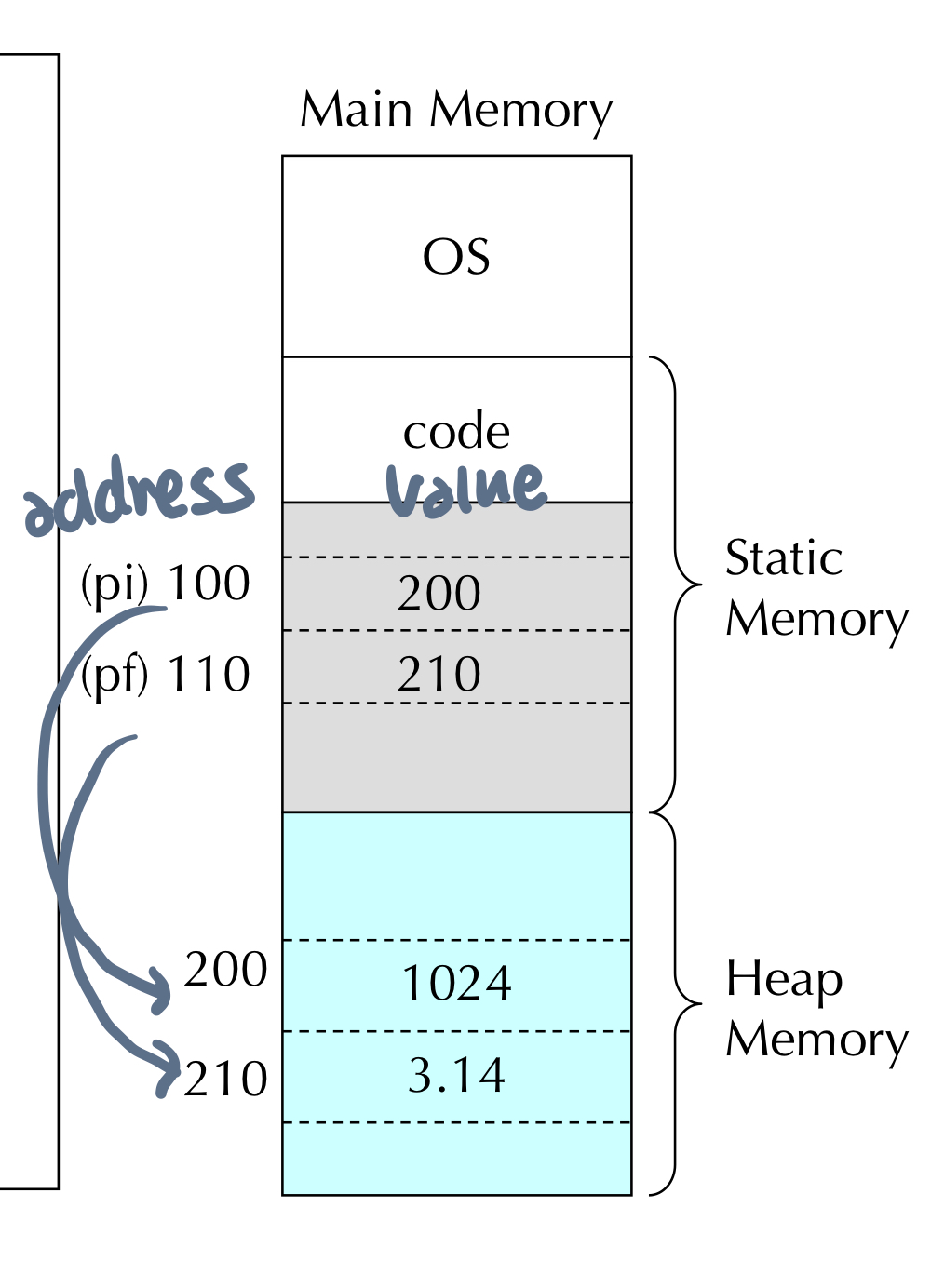
- 리스트 원소가 참조하는 객체도 복제되기 때문에 B의 원소 값을 수정해도 리스트 A가 참조하는 객체에는 변화가 없음
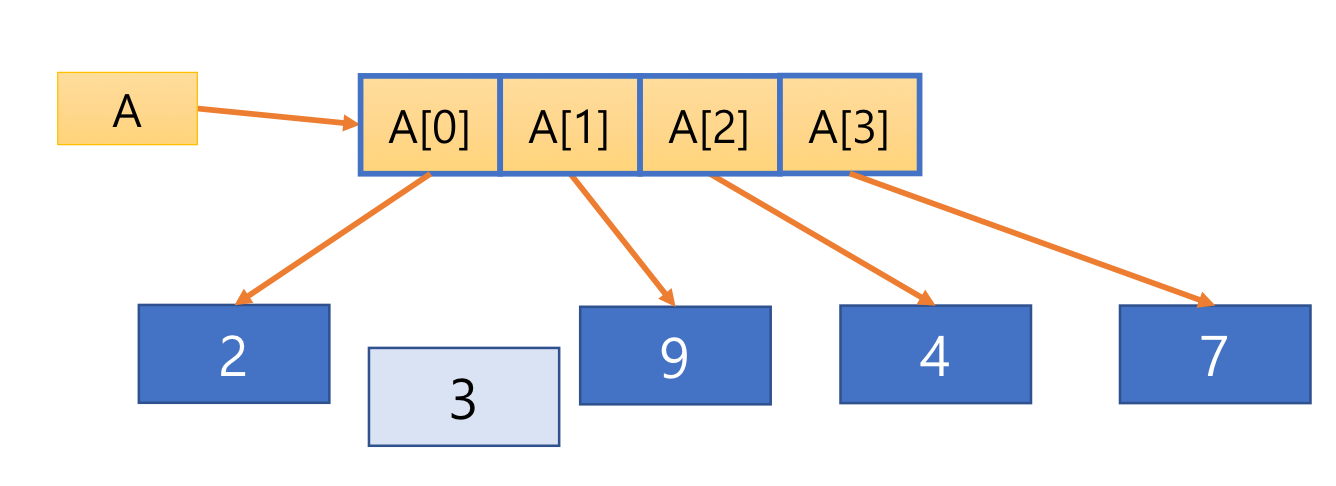
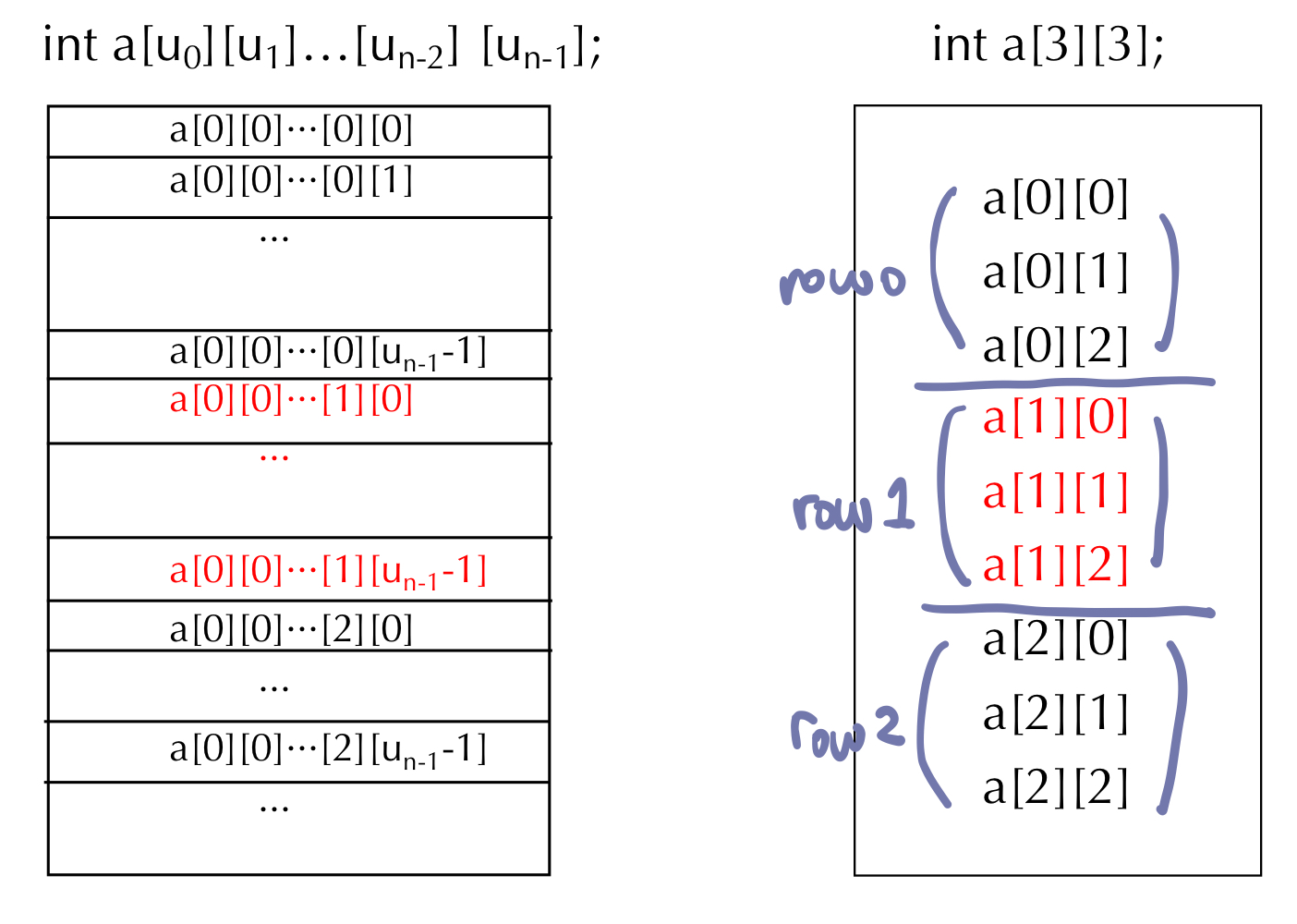
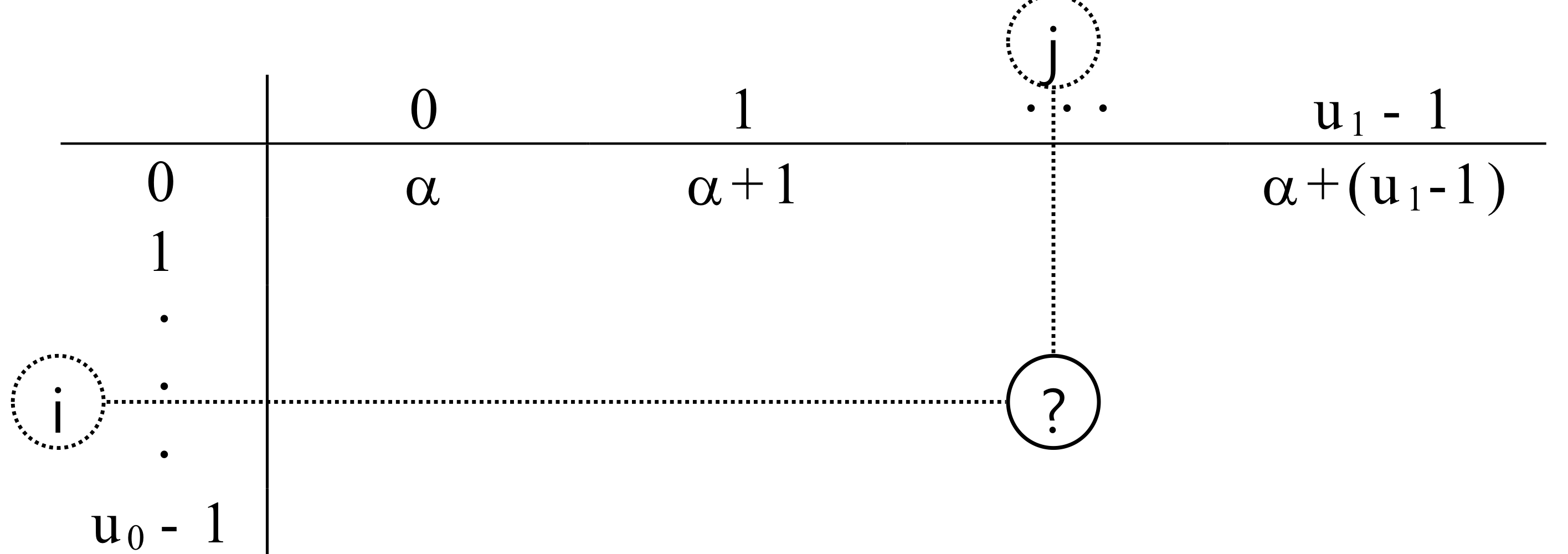
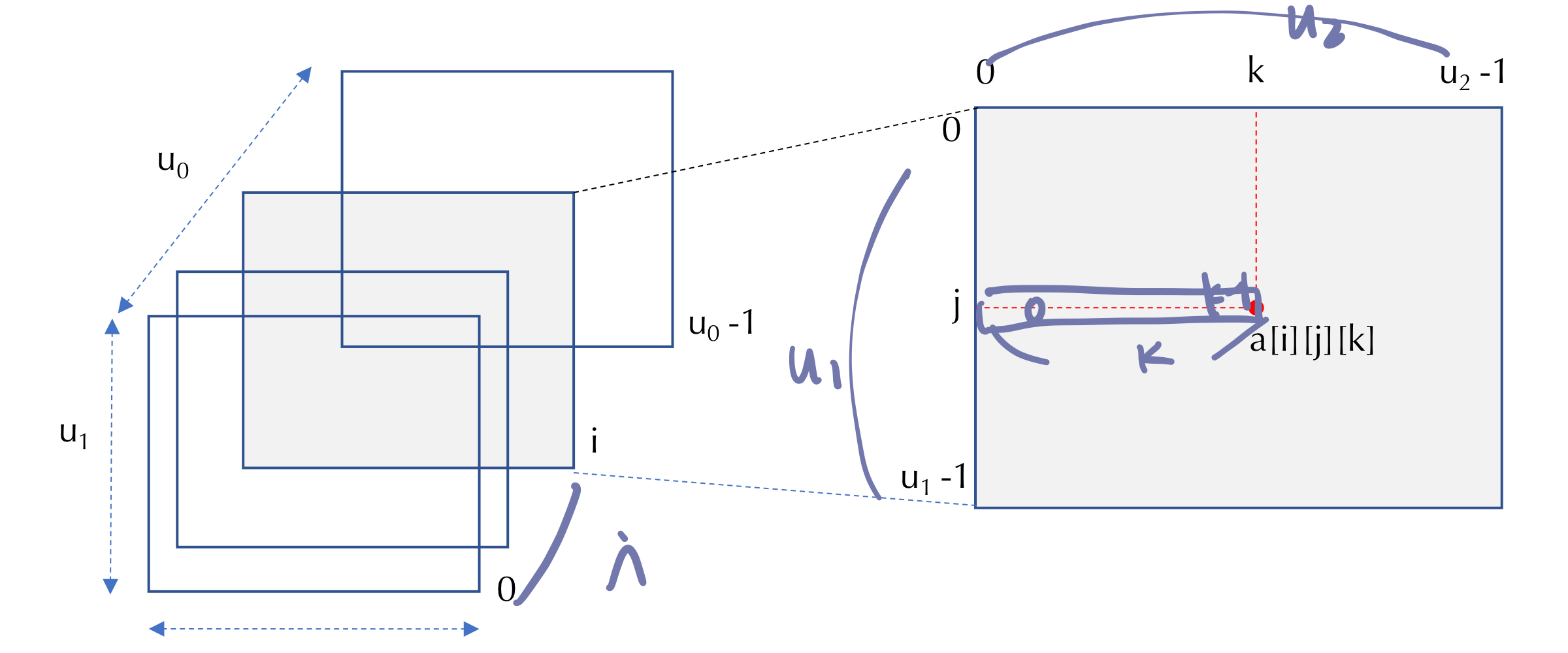
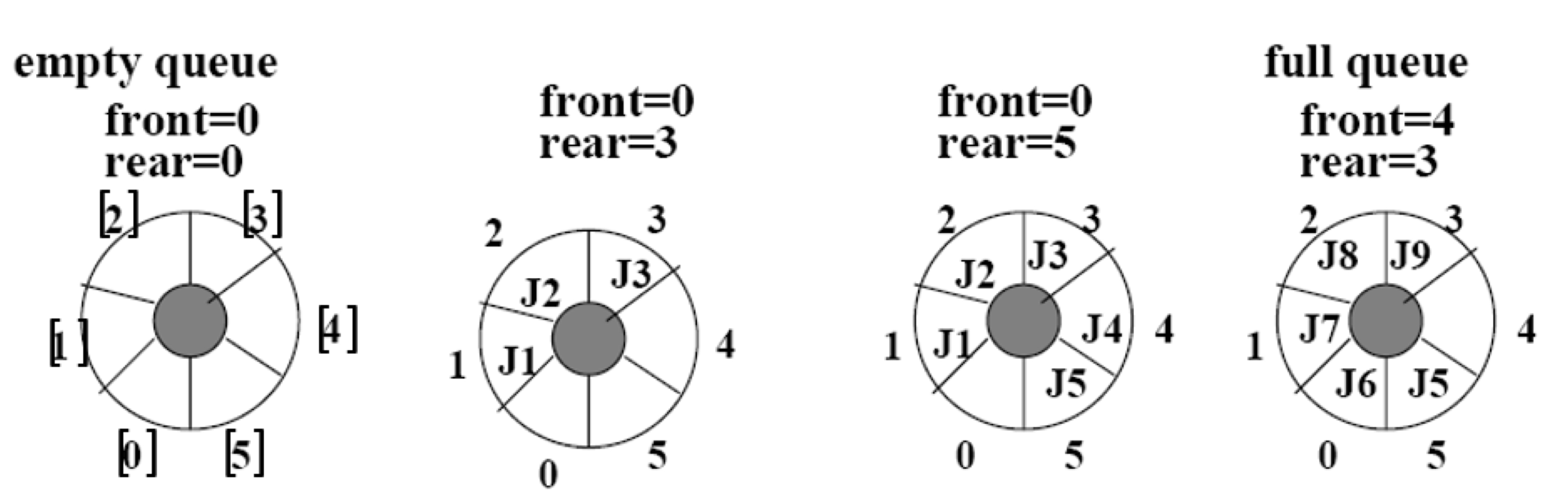
7. List
- 원소의 자료형 같을 필요 없음
- 파이썬은 정적 배열 지원하지 않음
- 사이즈는 고정되어 있지 않음 dynamic
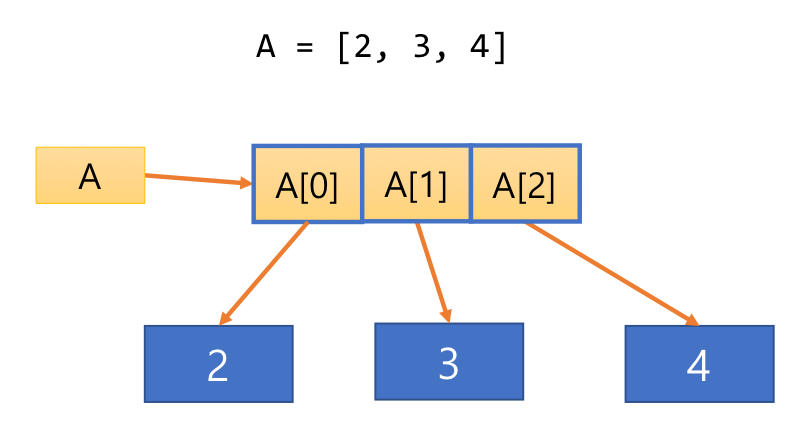
- referential array 리스트 원소는 값에 대한 참조 변수
A = [2, 3, 4]
A.append(7)
A[1] = 9
1) 리스트 생성
- 리스트 복합 표현
- range(), list() 함수 사용
- 빈 리스트 선언 후 원소 추가
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
num1 = [i for i in range(10)]
num2 = list(range(10))
num3 = []
for i in range(10):
num3 = num3 + [i] # num3.append(i)
2) 주사위 던지기 예제
import random
def throw_dice(count, n):
for i in range(n):
eye = random.randint(1, 6)
count[eye-1] += 1
def calc_ratio(count):
ratio = []
total = sum(count)
for i in range(6):
ratio.append(count[i]/total)
return ratio
def print_percent(num):
print('[', end = '')
for i in num:
print('%4.2f %i, end = ' ')
print(']')
dice = [0]*6
for n in [10, 100, 1000]:
print('Times = ', n)
throw_dice(dice, n)
print(dice)
ratio = calc_ratio(dice)
print_percent(ratio)
print()
sentence = sentence.lower() # 소문자로 변환
words = sentence.split() # 단어 단위로 분리
dic = {}
for word in words:
if word not in dic:
dic[word] = 0
dic [word] += 1
print('# of different words =', len(dic))
n = 0
for word, count in dic.items():
print(word, '(%d)' %count, end = ' ')
n += 1
if n % 3 == 0: print()
# sentence = 'Van Rossum was born and raised in the Netherlands, where he received a master's degree in mathematics and computer science from the University of Amsterdam in 1982. In December 1989, Van Rossum had been looking for a hobby programming project that would keep him occupied during the week around Christmas as his office was closed when he decided to write an interpreter for a new scripting language he had been thinking about lately, a descendant of ABC that would appeal to Unix / C hackers. '
# of different words = 66 van (2) rossum (2) was (2) born (1) and (2) raised (1) ...
9. Polynomial ADT 다항식 객체 (추상자료형)
- polynomial A(x) = 3x^20 + 2x^5 + 4
- x: variable, a: 계수 coefficient, e: 지수 exponent
- 튜플로 저장해야할 것: coefficient, exponent
# 다항식 덧셈
def padd(a, b, d):
while a and b:
coef1, exp1 = a[0]
coef2, exp2 = b[0]
if exp1 > exp2:
d.append(a.pop(0))
elif exp1 < exp2:
d.append(b.pop(0))
else:
if coef1 + coef2 == 0:
a.pop(0)
b.pop(0)
else:
d.append((coef1 + coef2, exp1))
a.pop(0)
b.pop(0)
for coef, exp in a:
d.append((coef, exp))
for coef, exp in b:
d.append((coef, exp))
# fb는 리스트
def fibo(fb):
a = 0
b = 1
fb.append(a)
fb.append(b)
while True:
a, b = b, a+b
if b < n: break
fb.append(b)
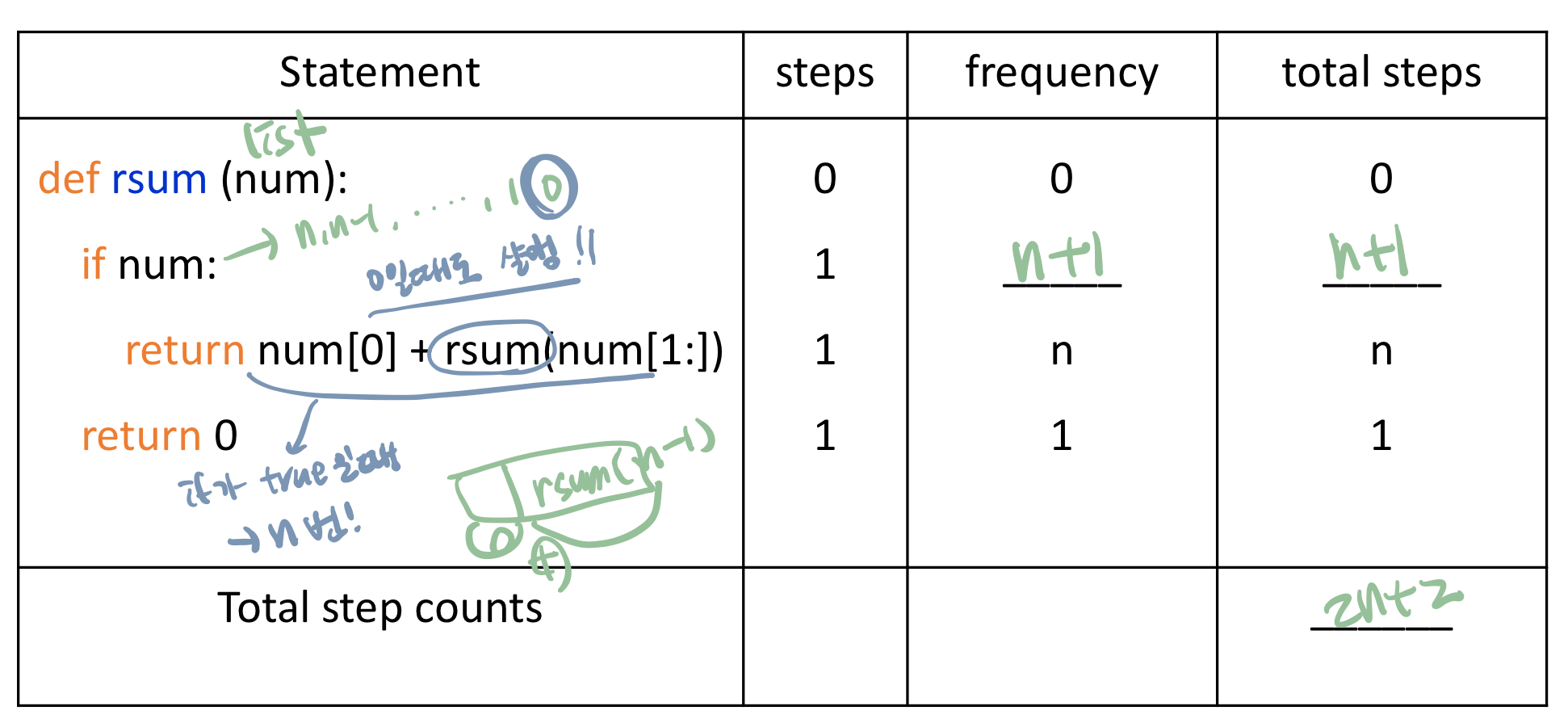
피보나치 수열을 구하는 함수이다.
리스트에 우선 0과 1을 넣고, b가 n이 되기 전까지 a = b, b = a+b로 대입하여 b, 즉 a+b를 리스트에 추가한다.
n = 100000
fb = []
fibo(fb)
print(fb)
print("# of fibos", len(fb))
5. Prime Numbers
- 소수: 1보다 큰 자연수 중 1과 자기자신 이외의 수로 나누어 떨어지지 않는 수
def find_prime(num):
for i in range(2, num+1):
prime = 1
for j in range(2, i):
if i % j == 0:
prime = 0
break
if prime: prime_list.append(i)
2부터 num까지의 수를 각각 i로 둘 때, i를 2부터 i까지의 수로 나누어 본다.
이 때, 나누어 떨어지면 소수가 아니기 때문에 prime = 0으로 둔다.
i까지 전부 나눈 후 prime이 여전히 1이면 소수이기 때문에 prime_list에 추가한다.
이 과정을 num까지 반복한다.
prime_list = []
max_num = 1000
find_prime(max_num)
for i in range(2, max_num):
if i in prime_list: print('%3d' %i, end = '')
else: print('_', end = '')
if i % 50 == 0: print()
print()
print('# of prime numbers = ', len(prime_list))
- 객체의 속성(attributes, properties, member variables)과 행동(methods, operations, member funtions)을 추상화하는 자료형
- 사용자가 필요에 의해 자료형을 직접 정의하는 것
- 객체지향 프로그래밍에서는 공통적인 행위를 하는 Class를 정의한다.
- ex) bank account, student, fraction
8. Fraction 분수
- 분자와 분모로 이루어져 있다.
- 기본적으로 분수는 내장되어있지 않기 때문에 객체로 정의해주어야 한다.
- 약분까지 해야 함 -> gcd(x, y)
class Fraction:
def __init__(self, up, down):
self.num = up
self.den = down
def __str__(self):
return str(self.num) + '/' + str(self.den)
def __add__(self, other):
new num = self.num * other.den + self.den * other.num
new_den = self.den * other.den
common = self.gcd(new_num, new_den)
return Fraction(new_num//common, new_den//common
def multiply(self, other):
new num = self.num * other.num
new_den = self.den * other.den
common = self.gcd(new_num, new_den)
return Fraction(new_num//common, new_den//common)
def gcd(self, a, b):
while a % b != 0:
a, b = b, a % b
return b
def __init__(self, up, down)은 Fraction 클래스를 호출했을 때 두번째 매개변수 up을 self.num에, 세번째 매개변수 down을 self.den에 대입하는 메서드이다. 이때 self.num은 분자, self.den은 분모이다.
def __str__(self)는 print(Fraction(up, down)을 실행했을 때 호출되는 메서드이다. 분수형태로 출력해준다.
def __add__(self, other)는 덧셈 메서드이다. + 로 두 변수를 연결했을 때 자동으로 호출된다.
분자는 self의 분자 x other의 분모 + self의 분모 x other의 분자이고,
분모는 self의 분모 x other의 분모이다.
common은 덧셈 결과의 분자와 분모의 최대공약수로, 이후에 나올 gcd 메서드를 통해 구할 수 있다.
- (양쪽 경계 값들의 차이) : (키 값과 왼쪽 경계 값의 차이) = (양쪽 범위의 거리) : (탐색 위치와 왼쪽 경계의 거리 차이)
#include <stdio.h>
int interpolate_serarch (int list[], int size, int key);
void main()
{
int size = 12;
int key = 39;
int pos;
int list[] = {2, 3, 5, 7, 8, 10, 13, 20, 25, 39, 45, 55};
pos = interpolate_search(list, size, key);
printf("%d is in %d\n", key, pos);
key = 2;
pos = interpolate_search(list, size, key);
printf("%d is in %d\n", key, pos);
key = 55;
pos = interpolate_search(list, size, key);
printf("%d is in %d\n", key, pos);
}
int interpolate_search(int list[], int size, int key)
{
int pos;
int left = 0;
int right = size - 1;
while (left <= right) {
pos = left + (key - list[left]) * (right - left) / (list[right] - list[left]);
if (list[pos] < key)
left = pos + 1;
else if (list[pos] > key)
right = pos - 1;
else return pos;
}
return -1;
}
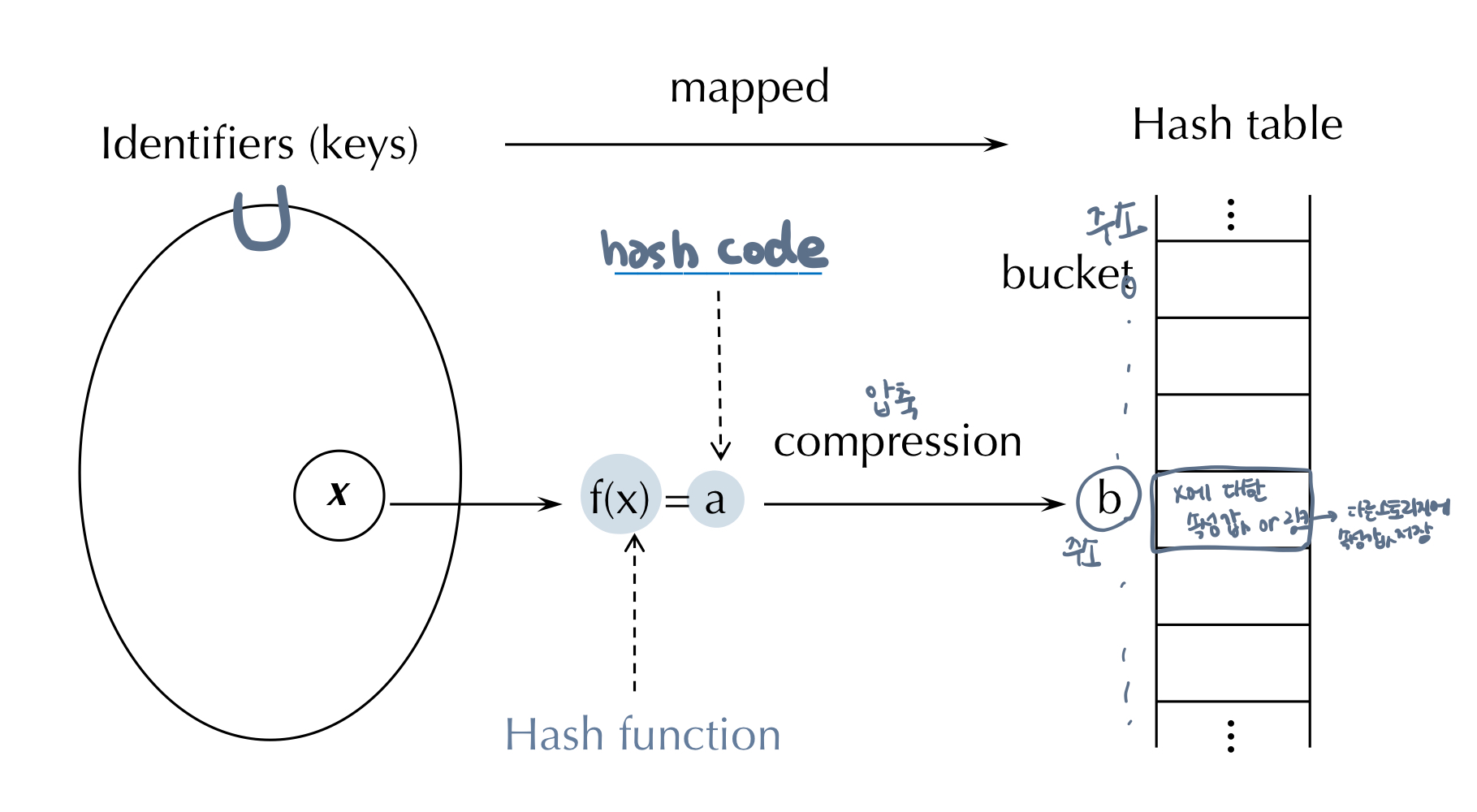
5. 해싱 탐색
- 탐색 키에 직접 산술적인 연산을 적용하여 탐색 키의 정보가 저장되어 있는 테이블 상의 위치를 계산하고 이 주소를 통해서 정보에 접근하는 방식이다.
- 즉, 반복적인 비교를 수행하는 것이 아니라, 키 자체에 있는 해답을 해시 함수를 통해 찾아내는 것이다.
- 시간 복잡도는 이론적으로 O(1)로 입력의 수 n에 상관없이 일정한 상수 시간을 갖는다.
- (ex) Dictionary
- Entry (key, value) // (word, definition)
- Applications
- Word / Thesaurus references
- Spelling checker in word processor or editor
- Electronic signature encoding/decoding
- Operations
- determine if a particular symbol(key) exists in the table (단순조회)
- retrieve the attributes of a key (키의 속성값을 참조하는 연산)
- modify the attributes of a key (키의 속성값 변경)
- insert a new entry with a key and value (새로운 entry 추가)
- delete an entry (entry 삭제)
해싱의 원리
5-1. Terms
- 해시 테이블 : 명칭(identifier)들이 저장된 고정된 크기의 표
- 명칭 밀도(ID) : 전체 명칭의 개수(T) 중 해시 테이블에 적재된 명칭 개수(n)의 비율 = n / T
- 적재 밀도(LD) : 해시 테이블의 크기에 대해 적재된 명칭 개수의 비율 = n / N
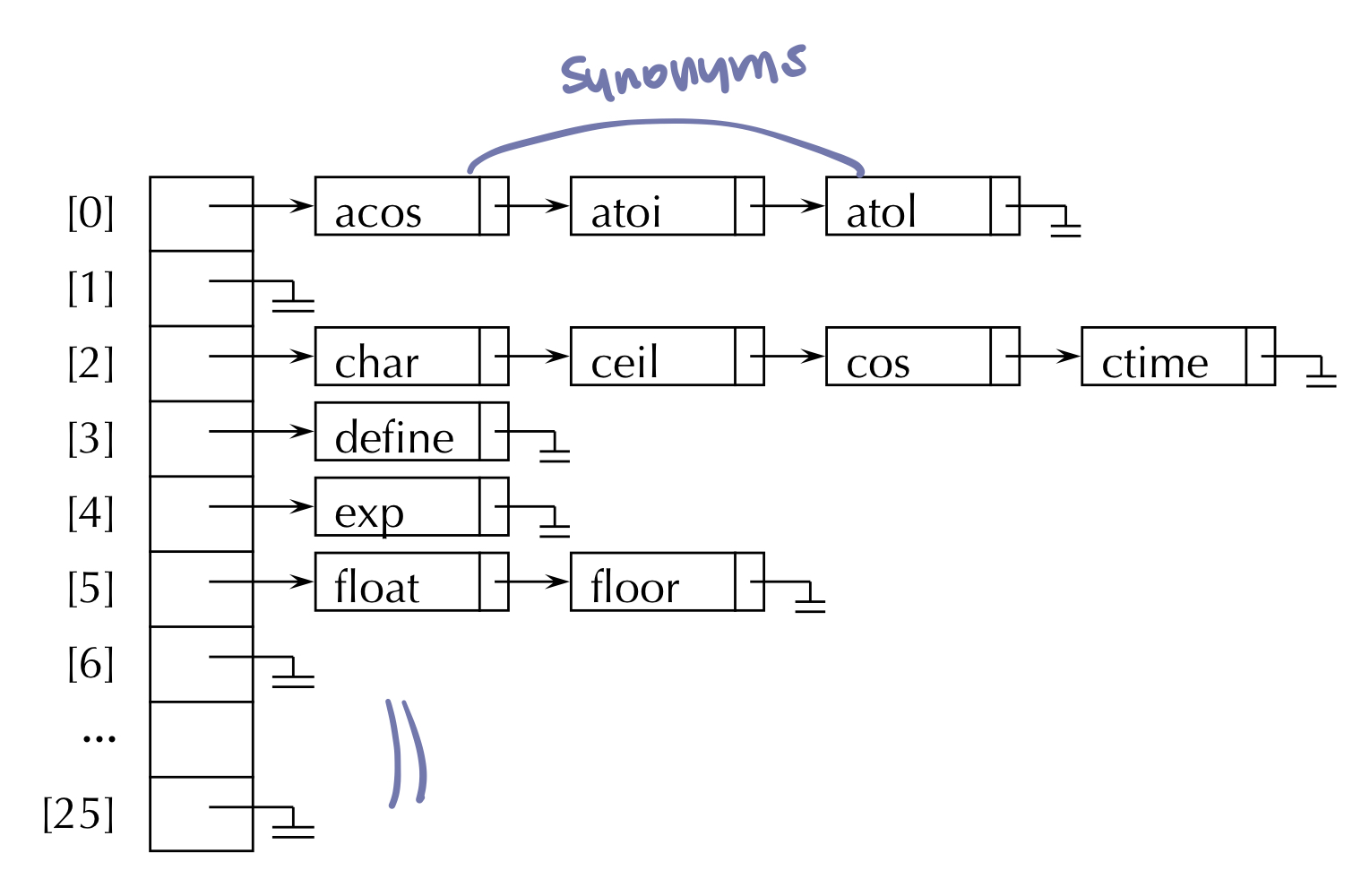
- 동의어(synonym) : 해시 테이블의 동일한 버켓 주소로 매핑된 서로 다른 명칭들, f(i₁) = f(i₂) 이면 i₁와 i₂는 동의어이다.
- 오버플로우 (overflow) : 명칭 i가 이미 꽉 찬 버켓으로 해싱(매핑)되는 경우 오버플로우가 발생한다고 말한다.
- 충돌 (collision) : 두 개의 서로 다른 명칭이 해시 테이블의 같은 버켓 주소로 매핑되면 충돌이 발생한다고 한다. 버켓의 크기가 1이면 충돌과 오버플로우가 동시에 발생한다.
- 해시 함수 : 해시 함수는 계산이 쉬워야 하고 명칭 간의 충돌을 최소화하여야 한다. 또한, 비대칭 편중분포를 막아야 한다.
- 균등 해시 함수 : 각 버켓에 적재될 확률이 1/b 인 해시 함수 (P[f(x) = i] = 1 / b
- 중간 제곱 해시 함수 : 명칭을 2진수로 변환한 후 제곱한 결과값에서 중간의 일부분을 해시 테이블 주소로 활용하는 함수, 테이블에 2ⁿ개의 버켓이 존재한다면 n개의 비트를 추출한다. collision을 최소화하기 위해 사용된다.
- 나눗셈 해시 함수 : 명칭을 특정 수로 나눈 나머지를 해시 테이블 주소로 사용하는 방법,예를 들어 해시 테이블 크기가 D라면 명칭 x를 D로 나눈 나머지 (0 ~ D-1)을 주소 값으로 사용한다. 이때 D는 분포에 영향을 주기 때문에 "소수"를 사용하는 것이 가장 좋고, 짝수는 사용하지 않는다. 나누는 수로 짝수를 사용하면 편중분포가 나타나기 때문이다.
- 폴딩 해시 함수 : 명칭에 해당하는 비트 열을 해시 테이블 크기만큼 여러번 접어서 주소값으로 사용하는 것이다.
- 이동 폴딩 : 명칭을 k 자리수로 분할한 뒤 순서대로 더한 결과값을 오른쪽에서 k자리 만큼 추출하여 주소 값으로 사용
- 경계 폴딩 : 분할한 문자열에서 짝수 번째 문자열을 뒤집어서 덧셈을 수행한 후 k 자리의 문자열을 추출하여 사용
- 키 분석 해시 함수 : 명칭의 구성과 내용을 미리 예측할 수 있는 경우에는 명칭을 분석하여 해시 테이블 주소로 사용할 키 값을 추출하는 방법을 사용할 수 있다. 예를 들어서 명칭이 학번일 경우, 앞의 두 자리는 입학년도임을 알고 그 부분은 배제하고 생각할 수 있다.
5-2. Static Hashing
- 해시 테이블의 크기가 고정되어있어 프로그램을 변경하지 않는 한 크기가 변경되지 않는 해싱 탐색 방법이다.
cf) Dynamic Hashing - 키 충돌 빈도에 따라 유연하게 해시 테이블 크기를 재구성하는 방법이다.
1) 탐색된 버켓에 삽입하려는 명칭이 이미 저장되어 있는 경우 : 중복된 명칭으로 보고하고 오류 처리 or 특정 필드 값 갱신
2) 탐색된 버켓이 비어 있는 경우 : 해당 버켓에 명칭 저장
3) 탐색된 버켓이 x가 아닌 다른 명칭을 포함하고 있는 경우 : 다음 버켓 탐색 지속
4) 탐색 결과 홈 버켓ㅇ로 다시 돌아온 경우 : 전체 버켓이 모두 꽉 찬 상태 → 오류 보고 후 종료
- 문제점 : 명칭들이 서로 모여서 클러스터를 형성한다. 충돌 횟수가 증가할수록 탐색 속도도 느려진다.
- 해시 함수 정의
- 키 (명칭)들을 ASCII 숫자값으로 변환한 뒤 해시 주소를 계산하는 방법이다.
// sum of ASCII codes of string chars
int transform (char *key)
{
int number = 0;
while (*key) // NULL 값이 아니면
number += *(key++); // 정수 + 문자 -> 문자가 ASCII 코드로 변환됨
return number;
}
int hash (char *key)
{
return (transform(key) % TABLE_SIZE);
}
- (ex)
F
O
R
\0
이 경우 number는 F, O, R 의 ASCII 코드의 합이 된다. 그리고 그 합을 table size로 나눈 나머지가 주소가 된다.
- 따라서 함수를 호출할 때마다 함수의 지역 변수, 복귀 주소 등 컨텍스트 정보를 활성 레코드에 저장해야 한다.
- 장점 : 알고리즘을 깔끔하게 표현할 수 있다.
- 단점 : 함수를 실행할 때마다 메모리에 환경 변수를 저장하기 때문에 메모리의 소모가 일어난다.
2. 팩토리얼 예제
- n! = 1 x 2 x ... x (n-1) x n = (n-1)! x n
- 같은 일 (곱셈) 을 반복하면서 n = 0이면 n! = 1 이라는 종결 조건이 포함되어있기 때문에 재귀 호출을 사용할 수 있다.
long factorial (int n)
{
if (n == 0)
return 1;
else
return n * factorial (n-1);
}
이와 같이 n = 0 이면 1을, n > 0 이면 n * (n-1)! 을 반환하는 형식으로 표현할 수 있다.
3. 최대공약수 (GCD) 예제
- 공통으로 나누는 수 중 가장 큰 수
- 조건 (by 유클리드 호제법)
- gcd (x, y) = gcd (y, x % y) (if (y > 0))
- gcd (x, 0) = x
ind gcd (x, y)
{
if (y == 0)
return x;
else return gcd (y, x % y);
}
4. Binary Search 이진 탐색
- 정렬된 항목 리스트에 대해서 중간값과 크기를 비교하고 그 결과에 따라 가능성이 있는 절반의 리스트에 대해서만 과정을 반복하는 탐색 알고리즘이다.
- 한 번 비교할 때마다 탐색 대상 원소의 수가 절반으로 감소한다.
- 원소의 수가 n개일 때 이진탐색은 총 log₂ⁿ 번의 비교 횟수를 요구한다. 따라서 순차 탐색보다 속도가 빠르다.
- 조건은 리스트 안에 겹치는 숫자가 없어야 한다는 것이다.
-while문과 if문을 이용한 이진탐색
#include <stdio.h>
int binsearch (int mylist[], int item, int left, int right);
void main()
{
int pos, maxnum = 12, item = 60;
int mylist[] = {5, 8, 9, 11, 13, 17, 23, 42, 45, 52, 60, 72};
pos = binsearch(mylist, item, 0, maxnum - 1);
printf("position = %d", pos);
}
int binsearch (int list[], int item, int left, int right)
{
int mid;
while (left <= right) {
mid = (left + right) / 2;
if (list[mid] == item)
return mid;
else {
if (item < list[mid]
right = mid - 1;
else
left = mid + 1;
}
}
return -1;
}
- 재귀호출 형식의 이진탐색
#include <stdio.h>
int rbinsearch (int mylist[], int item, int left, int right);
void main()
{
int pos, maxnum = 12, item = 60;
int mylist[] = {5, 8, 9, 11, 13, 17, 23, 42, 45, 52, 60, 72};
pos = binsearch(mylist, item, 0, maxnum - 1);
printf("position = %d", pos);
}
int rbinsearch (int list[], int item, int left, int right)
{
int mid;
if (left <= right)
{
mid = (left + right) / 2;
if (item == list[mid]
return mid;
else if (list[mid] < item)
return rbinsearch(list, item, mid + 1, right);
else
return rbinsearch (list, item, left, mid - 1);
}
return -1;
}
5. 하노이 타워 예제
- 세 개의 기둥과 크기가 다양한 원판이 존재한다.
- 해결할 문제는 한 기둥에 꽂힌 원판들을 그 순서 그대로 다른 기둥으로 옮기는 것이다.
- 조건
- 한 번에 하나의 원판만 옮길 수 있다.
- 큰 원판이 작은 원판 위에 놓일 수 없다.
- 알고리즘
- 세 개의 기둥 A, B, C 가 있고, A에서 B로 n개의 원판을 옮긴다.
1) A에서 (n-1)개의 원판을 C로 옮긴다.
2) A에 남은 1개의 원판을 B로 옮긴다.
3) C에 있는 (n-1)개를 B로 옮긴다.
- 기둥 a = 1, b = 2, c = 6 - a - b // a, b 제외한 빈 기둥이 c
- 총 이동횟수 : 2ⁿ - 1
#include <stdio.h>
void htower(int n, int a, int b);
int count = 0;
void main()
{
int n;
count = 0;
printf("Enter disc number = ");
scanf("%d", &n);
htower(n, 1, 2);
printf("# move for %d discs : %d\n", n, count);
}
void htower (int n, int a, int b)
{
int c;
count ++;
if (n == 1)
printf("Disc %d, moved from Pole (%d) to (%d)\n", n, a, b);
else {
c = 6 - a - b;
htower(n-1, a, c);
printf("Disc %d, moved from Pole (%d) to (%d)\n", n, a, c);
htower(n-1, c, b);
}
}
// i : start index of range
// n : end index of range
void perm(char list[], itn i, int n)
{
int j;
if (i == n) // list print
{
for (j = 0; j <= n; j++)
printf("%c", list[j]);
printf(" ");
}
else {
for (j = i; j <= n; j++) {
Swap(list[i], list[j]); // 두 수 교환
perm(list, i + 1; n);
Swap(list[i], list[j]);
}
}
}
// ex1
struct student
{
int age;
int grade;
char major[20];
} kim, lee;
// ex2
struct
{
int age;
int grade;
char major[20];
} kim, lee;
// ex3
struct student
{
int age;
int grade;
char major[20];
};
struct student kim, lee;
세 가지 모두 kim과 lee라는 구조체 변수를 선언하는 문장이다.
첫 번째 방식과 같이 구조체의 이름을 줄 수 있고, 두 번째 방식과 같이 구조체 변수를 생성할 수 있다. 세 번째 방식은 구조체 변수를 struct 키워드를 이용해서 선언하는 방식이다.
int prime (int n)
{
if (n < 2) return 0;
for (i = 2; i < n; i++)
if (n % i == 0) return 0;
return 1;
}
2) 2와 n 사이의 모든 소수
int prime2 (int n)
{
if (n < 2) return 0;
for (i = 2; i < n; i++) {
prime = 1;
for (j = 2; j < i; j++) {
if (i % j == 0) {
prime = 0;
break;
}
}
if (prime) printf("%d", i);
}
}
3. Huffman Coding Tree
- 빈도수에 따른 문자 압축 (요약) 방법
- (ex) "time and tide wait for no man"
- 방법
빈도수 순서로 문자들을 나열하고 빈도수의 합이 증가되는 방향으로 계속 더한다.
더할 땐 값이 같거나 작은 것과 더한다.
각각의 연결 선에 0과 1의 label을 붙여준다. 왼쪽이 0, 오른쪽이 1이다.
가장 위에서부터 각각의 문자까지 내려오면서 label을 읽는다.
예를 들어 e는 29 - 17 - 7- 4- 2 순서대로 내려오기 때문에 0011 의 값을 갖는다.
10101010110 을 읽으면 101 / 0101 / 0110 → not 이 된다.
각 문자가 갖는 이진수 값을 '허프만 코드' 라고 부른다.
허프만 코딩 방법으로 저장한 문자의 저장 공간은 Sum(Freq * bits) 비트가 필요하다.
원래 문자를 저장할 때 필요한 공간은 '문자 수 x 비트(8)' 인데, 허프만 코드를 이용하면 데이터의 비트 수가 줄어들기 때문에 공간 복잡도를 57%나 낮출 수 있다.