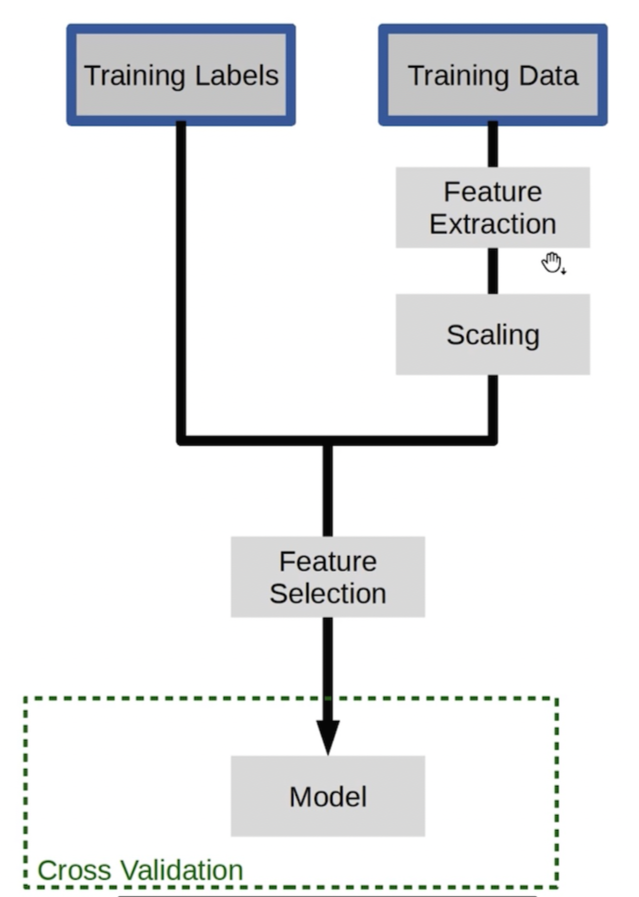
출처 https://www.boostcourse.org/ds214/lecture/102086?isDesc=false
프로젝트로 배우는 데이터사이언스
부스트코스 무료 강의
www.boostcourse.org
1. 당뇨병 데이터셋
https://www.kaggle.com/uciml/pima-indians-diabetes-database
https://www.scikit-learn.org/stable/modules/generated/sklearn.datasets.load_diabetes.html#sklearn.datasets.load_diabetes
* pregnancies : 임신횟수
* glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
* bloodPressure : 이완기 혈압 (mm Hg)
* skinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값
* insulin : 2시간 혈청 인슐린 (mu U / ml)
* BMI : 체질량 지수 (체중kg / 키 (m)^2)
* diabetesPedigreeFunction : 당뇨병 혈통 기능
* age : 나이
* outcome : 당뇨병인지 아닌지, 768개 중에 268개의 결과 클래스 변수 (0 / 1)는 1이고 나머지는 0이다.
2. 라이브러리 import
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
3. 데이터셋 로드
df = pd.read_csv("diabetes.csv") #주피터노트북에서 실행 -> 경로 간단
df.shape
9개의 feature가 존재하고, 768개의 데이터가 있다.
df.head()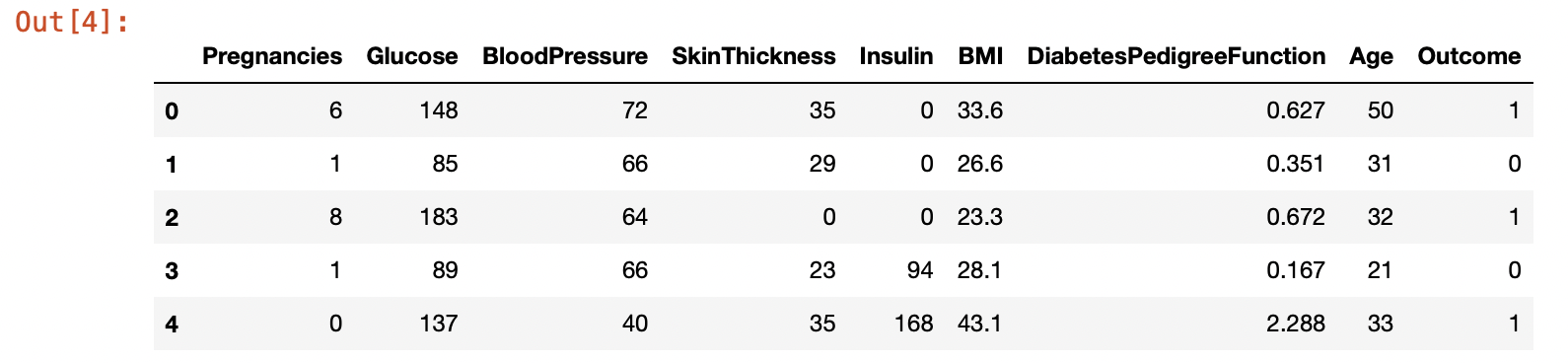
결측치가 없고 다 숫자로 되어있기 때문에 이 데이터셋은 전처리를 하지 않아도 괜찮다.
4. 학습, 예측 데이터셋 나누기
# 8:2 비율로 구하기 위해 전체 데이터 행에서 80% 위치에 해당되는 값을 구해서 split_count 변수에 담기
split_count = int(df.shape[0] * 0.8)
split_count
# train, test로 슬라이싱을 통해 데이터 나눔
train = df[:split_count].copy()
train.shape
test = df[split_count:].copy()
test.shape데이터셋 자체로 학습을 하고, 예측 후 정확도까지 알아보기 위해서 위에서부터 80%는 학습데이터, 나머지 20%는 예측데이터로 분리했다.
80% 지점이 614번째 데이터이기 때문에

학습데이터는 614개,

예측데이터는 154개이다.
5. 학습, 예측에 사용할 컬럼
# feature_names 라는 변수에 학습과 예측에 사용할 컬럼명을 가져옴
# 여러개를 가져왔기 때문에 list 형태로 가져옴
feature_names = train.columns[:-1].tolist()
feature_names
# label_name 에 예측할 컬럼의 이름 담음
label_name = train.columns[-1]
label_name
feature는 이렇게 9개가 있는데, 우리가 예측할 것은 마지막 컬럼인 outcome (당뇨병인지 아닌지) 이기 때문에 뒤에서 두번째 컬럼인 Age까지를 feature_names에 저장하고, 마지막 outcome을 label_name에 저장했다.
6. 학습, 예측 데이터셋 만들기
# 학습 세트 만들기
# 행렬
X_train = train[feature_names]
print(X_train.shape)
X_train.head()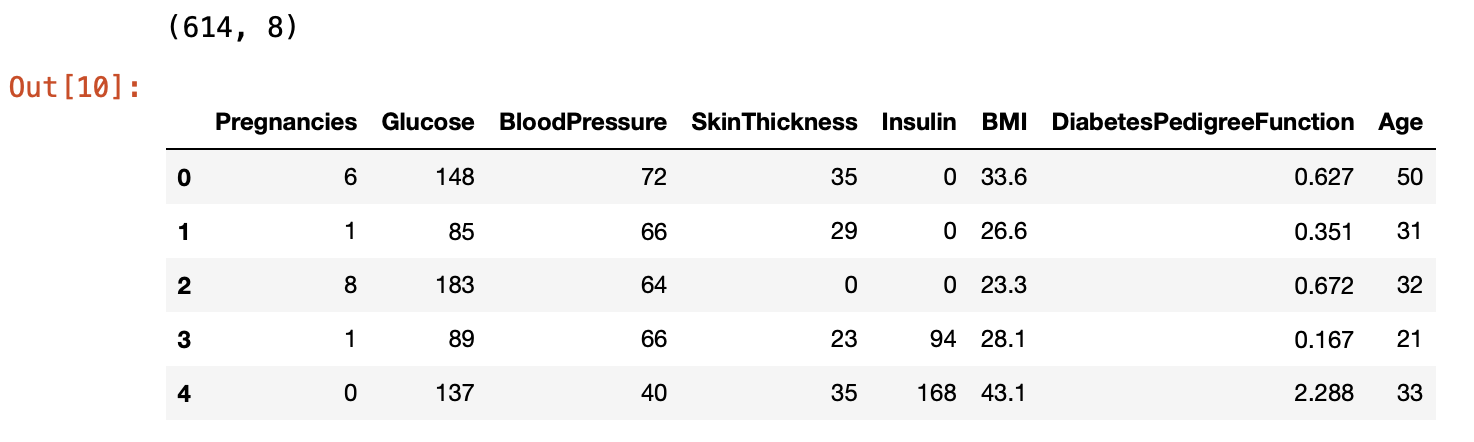
앞에서 나눈 80%의 학습데이터셋 train에 feature_names 컬럼을 적용하여 학습데이터셋 X_train 을 만들었다.
# 정답 값
# 벡터
y_train = train[label_name]
print(y_train.shape)
y_train.head()
마찬가지로 앞에서 나눈 80%의 학습데이터셋에 label_name 컬럼을 적용하여 학습할 때 정답을 맞추는 데이터셋 y_train을 만들었다.
# 예측에 사용할 데이터셋
X_test = test[feature_names]
print(X_test.shape)
X_test.head()
다음은 앞에서 나눈 20%의 예측데이터셋에 feature_names를 적용하여 학습한 알고리즘에 적용할 예측데이터셋 X_test를 만들었다.
# 예측의 정답값
# 실전에는 없지만, 실전 적용 전 정답을 알고있기 때문에 내가 만든 모델의 성능을 측정해봐야 함
y_test = test[label_name]
print(y_test.shape)
y_test.head()
마지막으로, 예측 모델의 성능을 측정하기 위한 예측 정답 데이터셋을 만들었다.
20% 예측 데이터셋에 label_name을 적용한 데이터셋으로, 실전 예측 문제에는 없지만 이 예제에서는 알고있는 값이기 때문에 모델의 성능을 측정할 때 사용할 것이다.
7. 머신러닝 알고리즘 가져오기
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model
decision tree classifier 알고리즘을 사용할 것이기 때문에 이 알고리즘을 model 변수에 저장해준다.
8. 학습 (훈련)
model.fit(X_train, y_train)아주 간단하다.
머신러닝 알고리즘.fit(훈련데이터, 정답데이터) 형식이다.
9. 예측
y_predict = model.predict(X_test)
y_predict[:5]학습이 기출문제와 정답으로 공부를 하는 과정이었다면, 예측은 실전 문제를 푸는 과정이라고 볼 수 있다.

위에서 5개 데이터의 예측 결과를 보자면 이와 같다. 1은 당뇨병, 0은 당뇨병이 아니라는 것이다.
10. 트리 알고리즘 분석
from sklearn.tree import plot_tree
#plot_tree(model,
# feature_names = feature_names)
# 글자로 나옴
# 시각화
plt.figure(figsize = (20, 20))
tree = plot_tree(model,
feature_names = feature_names,
filled = True,
fontsize = 10)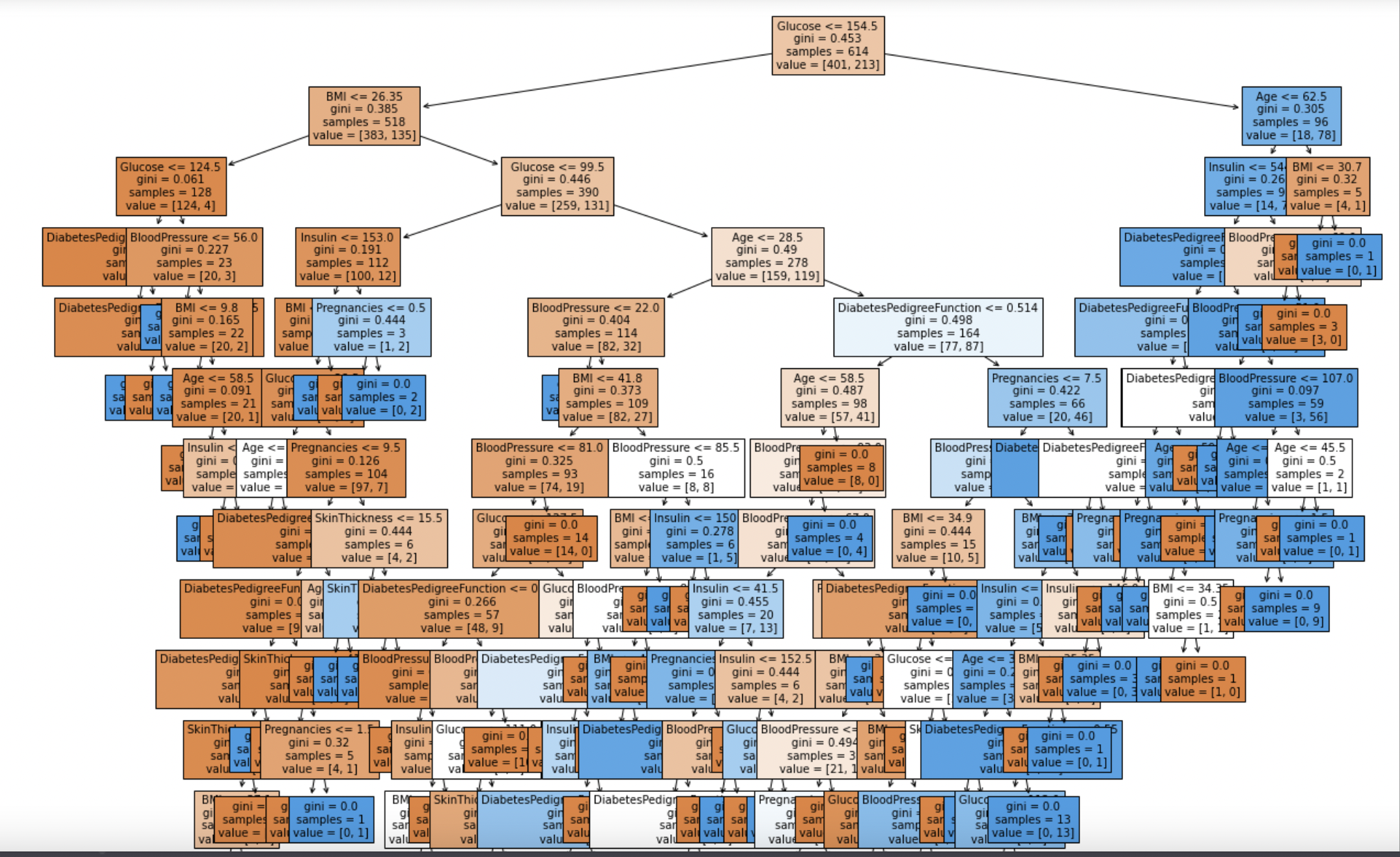
# 피처의 중요도 표시
model.feature_importances_
각 피처의 중요도를 알려준다.
# 피처의 중요도 시각화
sns.barplot(x = model.feature_importances_, y = feature_names)
seaborn을 활용해서 각 피처의 중요도를 시각화했다.
11. 정확도(Accuracy) 측정하기
# 실제값 - 예측값 -> 같은 값은 0으로 나옴
# 여기서 절대값을 씌운 값 = 1 인 값이 다르게 예측한 값임
diff_count = abs(y_test - y_predict).sum()
diff_count
# decision tree 예측할 때마다 다르게 예측할 수 있기 때문에 이 값은 다르게 나올 수 있음
# 항상 같게 하려면 model = DecisionTreeClassifier(random_state = 42)처럼 random_state 지정
우리는 예측 데이터셋의 정답도 알고있기 때문에 모델의 정확도를 측정할 수 있다.
outcome 값은 0 또는 1이기 때문에 실제값에서 예측값을 뺀 값의 절대값이 1인 값이 틀린 것이라고 볼 수 있다.
실제값에서 예측값을 뺀 값들의 합을 (틀린 예측의 수) diff_count 변수에 저장했다.
# 예측의 정확도 구하기 -> 100점 만점에 몇 점인지
(len(y_test) - diff_count) / len(y_test) * 100
예측데이터셋에서 틀린 예측의 수를 뺀 비율로 정확도를 구했더니 약 69%가 나왔다.
decision tree는 예측할 때마다 가지의 수 등의 원인으로 다르게 예측할 수 있다.
이를 고정하려면 알고리즘을 불러올 때 속성에서 random_state 값을 지정해주어야 한다.
# 위처럼 직접 구할 수도 있지만, 미리 구현된 알고리즘을 가져와 사용한다
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict) * 100

이건 사이킷런에 미리 구현된 알고리즘으로 정확도를 계산한 것이다. 위와 같은 값이다.
# model 의 score로 점수 계산 (정답값 y_test 알고있을 때)
model.score(X_test, y_test)
이건 model 의 score로 점수를 계산한 것이다. 정답값을 알고있을 때 사용하며, 위에서의 정확도와 같다.
'Software > Python' 카테고리의 다른 글
| [부스트코스] 프로젝트로 배우는 데이터사이언스 Ch 1 (0) | 2021.08.06 |
|---|