create database kaggle;
use kaggle;
CREATE TABLE `org_test_import` (
`PassengerId` int NULL,
`Pclass` int NULL,
`Name` text,
`Sex` text,
`Age` text,
`SibSp` int NULL,
`Parch` int NULL,
`Ticket` text,
`Fare` text,
`Cabin` text,
`Embarked` text
) ENGINE=InnoDB ;
SELECT @@sql_mode;
set @@sql_mode = "";
CREATE TABLE `test` (
`PassengerId` int NULL,
`Pclass` int NULL,
`Name` text,
`Sex` text,
`Age` double,
`SibSp` int NULL,
`Parch` int NULL,
`Ticket` text,
`Fare` double,
`Cabin` text,
`Embarked` text
) ENGINE=InnoDB ;
INSERT INTO `kaggle`.`test` (
`PassengerId`,
`Pclass`,
`Name`,
`Sex`,
`Age`,
`SibSp`,
`Parch`,
`Ticket`,
`Fare`,
`Cabin`,
`Embarked` )
SELECT `org_test_import`.`PassengerId`,
`org_test_import`.`Pclass`,
`org_test_import`.`Name`,
`org_test_import`.`Sex`,
`org_test_import`.`Age`,
`org_test_import`.`SibSp`,
`org_test_import`.`Parch`,
`org_test_import`.`Ticket`,
`org_test_import`.`Fare`,
`org_test_import`.`Cabin`,
`org_test_import`.`Embarked`
FROM `kaggle`.`org_test_import`;
select age from `org_test_import`;
select age from `kaggle`.`test`;
SELECT * FROM `gender_submission`;
ALTER TABLE `test` ADD PRIMARY KEY (`PassengerId`);
ALTER TABLE `gender_submission` ADD PRIMARY KEY (`PassengerId`);
ALTER TABLE `gender_submission` ADD FOREIGN KEY (`PassengerId`) REFERENCES `test` (`PassengerId`);
SELECT COUNT (*) FROM `gender_submission`;
SELECT COUNT (*) FROM `test`;
SELECT COUNT (*) FROM test A JOIN gender_submission B ON A.PassengerId = B.PassengerId;
CREATE TABLE `titanic` (
`PassengerId` int not NULL,
`Pclass` int NULL,
`Name` text,
`Sex` text,
`Age` double,
`SibSp` int NULL,
`Parch` int NULL,
`Ticket` text,
`Fare` double,
`Cabin` text,
`Embarked` text,
`Survived` int ,
primary key (`PassengerId` )
) ENGINE=InnoDB ;
INSERT INTO `kaggle`.`titanic` (
`PassengerId`,
`Pclass`,
`Name`,
`Sex`,
`Age`,
`SibSp`,
`Parch`,
`Ticket`,
`Fare`,
`Cabin`,
`Embarked`,
`Survived`)
SELECT
A.`PassengerId`,
`Pclass`,
`Name`,
`Sex`,
`Age`,
`SibSp`,
`Parch`,
`Ticket`,
`Fare`,
`Cabin`,
`Embarked`,
B.`Survived`
FROM test A JOIN gender_submission B ON A.PassengerId = B.PassengerId ;
SELECT COUNT(*) FROM `kaggle`.`titanic` ;
SELECT * FROM `kaggle`.`titanic` ;
SELECT MAX(`Age`) FROM `kaggle`.`titanic`;
SELECT MIN(`Age`) FROM `kaggle`.`titanic` WHERE `Age` > 0;
SELECT AVG(`Age`), COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0;
SELECT sum(`Fare`) FROM `kaggle`.`titanic`;
SELECT `Name`, `Pclass`, `Sex`, `Age` FROM `kaggle`.`titanic` ORDER BY 1 ; ##첫번째 컬럼 기준으로 오름차순 (Name)
SELECT `Name`, `Pclass`, `Sex`, `Age` FROM `kaggle`.`titanic` ORDER BY 3 ;
SELECT `Name`, `Pclass`, `Sex`, `Age` FROM `kaggle`.`titanic` ORDER BY `Name` DESC ;
#10개 제한된 행 조회
SELECT * FROM `kaggle`.`titaic` WHERE `Name` LIKE 'A%' LIMIT 10; #이름이 A로 시작하는 row 10개
##`PassengerId` 유일한 값만 조회
SELECT DISTINCT `PassengerId` FROM `kaggle`.`titanic`;
SELECT DISTINCT `Sex` FROM `kaggle`.`titanic`;
SELECT `Sex`, COUNT(*) FROM `kaggle`.`titanic` GROUP BY 1; #첫번째 컬럼을 그룹화해서 카운트
SELECT `Sex`, COUNT(*) CNT FROM `kaggle`.`titanic` GROUP BY `Sex` HAVING CNT > 200; #count = cnt, cnt가 200이상인 그룹의 카운트 수
SELECT `Sex`, `survived`, COUNT(*) FROM `kaggle`.`titanic` GROUP BY `Sex`, `Survived` ;
##floor = 반올림
#연령 밴드별 조회
SELECT floor(`Age`/10) * 10 + 10, COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0 group by 1; #~대 미만 승객 수
SELECT floor(`Age`/10) * 10 + 10, COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0 group by 1 order by 1;
SELECT floor(`Age`/10) * 10 + 10, COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0 group by 1 order by 1 desc;
SELECT floor(`Age`/10) * 10 + 10, `survived`, COUNT(*) CNT FROM `kaggle`.`titanic`
WHERE `Age` > 0 group by 1, 1 HAVING CNT > 40 order by 1 desc, 2 desc;
#서브쿼리
SELECT * FROM `kaggle`.`titanic`
WHERE `PassengerId` IN (SELECT `PassengerId` FROM `test` WHERE `Age` = 0); # NULL 값이었던 passengerId(age=0)를 titanic table에서 조회해라
UPDATE `kaggle`.`titanic`
SET `Age` = 30.272590361445783
WHERE `PassengerId` IN (SELECT `PassengerId` FROM `test` WHERE `Age` = 0) ;
이번 예제는 csv 파일을 import하여 타이타닉 데이터를 활용해보는 예제이다.
이번에 사용할 2개의 예제 데이터는 https://www.kaggle.com/c/titanic/ 에서 받을 수 있다.
(gender_submission, test)

kaggle 테이블을 만들고, 스키마에서 Tables -> Table Data Import Wizard를 누르면 csv파일을 import할 수 있다.
첫번째로 'gender_submission.csv' 파일을 import해주었다.
이때, 현재 sql모드가 data타입을 strict하게 설정하도록 되어있기 때문에,
Wizard로 import한 데이터파일에 NULL값이 있으면 그 값은 truncate (삭제) 된다.
두번째로 import할 'test.csv' 파일에 NULL값이 있기 때문에
이걸 고치기 위해 sql 모드를 strict하지 않게 바꿔주고, 데이터타입을 바꿔주는 테이블을 생성할 것이다.
코드를 살펴보겠다.
create database kaggle;
use kaggle;kaggle database를 생성하고, 이용하겠다는 뜻이다.
이후 위에 있는 사진처럼 이 데이터베이스에 'gender_submission.csv'파일을 import 했다.
import할 때에 'gender_submission'이라는 테이블을 함께 형성해서 저장했다.
CREATE TABLE `org_test_import` (
`PassengerId` int NULL,
`Pclass` int NULL,
`Name` text,
`Sex` text,
`Age` text,
`SibSp` int NULL,
`Parch` int NULL,
`Ticket` text,
`Fare` text,
`Cabin` text,
`Embarked` text ) ENGINE=InnoDB ; 이 테이블은 두번째로 import할 'test.csv'파일의 값을 저장할 테이블이다.
현재 sql모드가 데이터를 strict하게 저장하도록 설정되어있기 때문에, 'text.csv' 파일에서 double타입의 'age' 값에 NULL값이 있으면 Wizard로 import 할 때 테이블이 truncate된다. (삭제된다)
따라서, 우선 'age'와 'fare'의 데이터타입을 text로 변경한 테이블 'org_test_import'에 파일을 import하고,
이후 다시 원래대로 데이터 타입을 바꾼 테이블('test')에 값을 저장해주도록 하겠다.
SELECT @@sql_mode; 현재 sql_mode를 알려준다.

set @@sql_mode = "" ;또한, sql_mode를 strict하지 않게 바꿔주었다.
CREATE TABLE `test` (
`PassengerId` int NULL,
`Pclass` int NULL,
`Name` text,
`Sex` text,
`Age` double,
`SibSp` int NULL,
`Parch` int NULL,
`Ticket` text,
`Fare` double,
`Cabin` text,
`Embarked` text
) ENGINE=InnoDB ;
이 테이블이 import한 'test.csv'파일을 옮겨 담을 테이블이다.
'age'와 'fare'의 도메인을 원래처럼 double로 바꿔주었다.
INSERT INTO `kaggle`.`test`
(`PassengerId`,
`Pclass`,
`Name`,
`Sex`,
`Age`,
`SibSp`,
`Parch`,
`Ticket`,
`Fare`,
`Cabin`,
`Embarked`)
SELECT `org_test_import`.`PassengerId`,
`org_test_import`.`Pclass`,
`org_test_import`.`Name`,
`org_test_import`.`Sex`,
`org_test_import`.`Age`,
`org_test_import`.`SibSp`,
`org_test_import`.`Parch`,
`org_test_import`.`Ticket`,
`org_test_import`.`Fare`,
`org_test_import`.`Cabin`,
`org_test_import`.`Embarked`
FROM `kaggle`.`org_test_import`;
'org_test_import'에 저장된 모든 값을 'test'테이블에 삽입하는 코드이다.
이제 NULL값이 있던 'age'값을 각각의 테이블에서 select해보겠다.
select age from `org_test_import` ; #NULL값이 있음 (text이기 때문)

select age from `kaggle`.`test` ; #NULL -> 0 (double이기 때문)

test파일에 저장된 'age' 값에는 NULL값이 없고 그 값들이 모두 0으로 바뀐 것을 볼 수 있다.
NULL값이 있는 데이터 파일을 wizard로 import할 때에는 위와 같이 도메인을 text로 바꾼 테이블을 만들어서 import한 뒤, 다시 옮겨주는 방법을 사용하면 된다.
SELECT * FROM `gender_submission` ;'gender_submission' 테이블의 값을 보여준다.
AlTER TABLE `test` ADD PRIMARY KEY ( `PassengerId` ) ; 'test' 테이블의 기본키를 'PassengerId'로 바꿔주는 코드이다.
AlTER TABLE `gender_submission` ADD PRIMARY KEY ( `PassengerId` ) ; 'gender_submission' 테이블의 기본키를 'PassengerId'로 설정하는 코드이다.
AlTER TABLE `gender_submission` ADD FOREIGN KEY ( `PassengerId` ) REFERENCES `test` ( `PassengerId` ) ; 'gender_submission' 테이블의 외래키를 'PassengerId'로 설정하며, 'test' 테이블의 'PassengerId' 값을 참조하겠다는 코드이다.
SELECT COUNT(*) FROM `gender_submission` ;
SELECT COUNT(*) FROM `test` ;count( ) 는 투플의 개수를 세는 함수이다. FROM - 뒤에 WHERE - 을 붙여 조건을 걸 수 있다.
정확한 표현인지는 모르겠지만..
예제에 나온 SELECT COUNT(*) FROM 'gender_submission'; 은 'gender_submission' 테이블에 있는 전체 투플 수 (rows)를 count해준다.
SELECT COUNT(*) FROM test A JOIN gender_submission B ON A.PassengerId = B.PassengerId ;'test' 테이블의 'PassengerId'와 'gender_submission'테이블의 'PassengerId'가 같을 경우에, 'test'테이블과 'gender_submission'테이블을 결합한다는 의미이다. 그리고, 그 결합한 것의 투플 수 (row 수)를 세는 코드이다.
두 테이블 다 418개의 투플을 갖고 있기 때문에, 이 결과도 418이 나온다.

CREATE TABLE `titanic` (
`PassengerId` int not NULL,
`Pclass` int NULL,
`Name` text,
`Sex` text,
`Age` double,
`SibSp` int NULL,
`Parch` int NULL,
`Ticket` text,
`Fare` double,
`Cabin` text,
`Embarked` text,
`Survived` int ,
primary key (`PassengerId` )
) ENGINE=InnoDB; 'titanic'이라는 테이블을 생성했다. 이 테이블에는 'test'테이블과 'gender_submission'테이블을 결합하여 저장할 것이다.
INSERT INTO `kaggle`.`titanic`
(`PassengerId`,
`Pclass`,
`Name`,
`Sex`,
`Age`,
`SibSp`,
`Parch`,
`Ticket`,
`Fare`,
`Cabin`,
`Embarked`,
`Survived`)
SELECT
A.`PassengerId`,
`Pclass`,
`Name`,
`Sex`,
`Age`,
`SibSp`,
`Parch`,
`Ticket`,
`Fare`,
`Cabin`,
`Embarked`,
B.`Survived`
FROM test A JOIN gender_submission B ON A.PassengerId = B.PassengerId ;
insert into, select, from join on 함수를 이용하여,
'test'테이블의 PassengerId값과 'gender_submission'테이블의 PassengerId값이 같을 경우,
두 테이블을 결합하여 각각의 값들을 'titanic' 테이블에 저장해 하나의 테이블로 만드는 것이다.
SELECT COUNT(*) FROM `kaggle`.`titanic` ; 'titanic' 테이블의 투플 수를 보여준다.
'gender_submission'의 'PassengerId'값은 외래키로, 'test' 테이블의 값을 참조한 것이기 때문에 모든 값이 같다.
따라서 모든 투플이 결합하여 저장되었기 때문에 count 수는 동일하게 418이다.

SELECT * FROM `kaggle`.`titanic` ; 'titanic' 테이블의 모든 값을 보여준다.

SELECT MAX(`Age`) FROM `kaggle`.`titanic`;MAX함수는 이 속성에서 가장 큰 값을 보여준다.

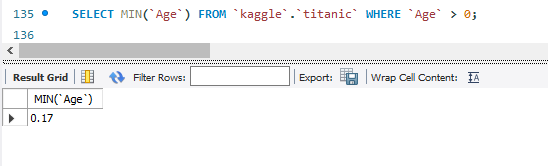
SELECT MIN(`Age`) FROM `kaggle`.`titanic` WHERE `Age` > 0;MIN함수는 반대로 이 속성에서 가장 크기가 작은 값을 보여준다.
WHERE은 조건문 느낌으로, 'Age'값이 0보다 큰 범위에서 가장 작은 값을 보여달라는 의미이다.
NULL값이 0으로 변환되었기 때문에 이 조건을 추가한 것이다.
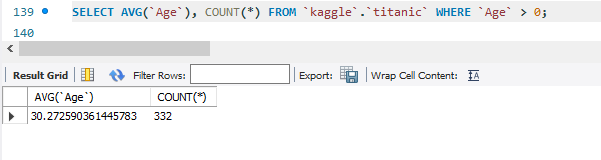
SELECT AVG(`Age`), COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0;AVG는 평균을 보여주는 값이다.
COUNT는 뒤에 WHERE `Age` > 0 의 조건이 붙었기 때문에 'Age' 값이 0보다 큰 투플의 개수를 알려준다.
SELECT sum(`Fare`) FROM `kaggle`.`titanic`;sum은 해당 속성의 투플 값들을 모두 더한 값을 반환한다.

SELECT `Name`, `Pclass`, `Sex`, `Age` FROM `kaggle`.`titanic` ORDER BY 1 ; ORDER BY 1은 SELECT 뒤에 나열된 4개의 속성들 중 첫번째 속성을 기준으로 오름차순 정렬하여 반환하라는 의미이다.

SELECT `Name`, `Pclass`, `Sex`, `Age` FROM `kaggle`.`titanic` ORDER BY 3 ;마찬가지로 3번째 속성인 'Sex'를 기준으로 오름차순 정렬하라는 의미이다.

SELECT `Name`, `Pclass`, `Sex`, `Age` FROM `kaggle`.`titanic` ORDER BY `Name` DESC ;ORDER BY - DESC는 해당 속성 기준으로 내림차순 정렬하라는 의미이다.
그리고 ORDER BY 뒤에 숫자보다는 이와 같이 속성명을 직접 써주는 것이 더욱 직관적이다.

SELECT * FROM `kaggle`.`titanic` WHERE `Name` LIKE 'A%' LIMIT 10; LIKE 'A%' 은 'Name' 값들 중에서 A로 시작하는 값을 반환하라는 조건이다.
LIMIT 10은 그 중에서 상위 10개만 반환하라는 조건이다. 아마 조건에 대한 오름차순 정렬 후 10개인 것 같다.

SELECT DISTINCT `PassengerId` FROM `kaggle`.`titanic`;DISTINCT 는 해당 속성의 값들 중 유일한 값만 조회하는 함수이다.
'PassengerId'의 경우 기본키로, 모든 투플이 유일하게 갖는 값이기 때문에 모든 값이 반환된다.

SELECT DISTINCT `Sex` FROM `kaggle`.`titanic`;마찬가지로 'Sex' 의 값들 중 유일한 값들만 반환한다.
이 경우 투플 값이 male과 female 두 가지로 나뉘기 때문에 두개의 값만 반환된다.


SELECT `Sex`, COUNT(*) FROM `kaggle`.`titanic` GROUP BY 1; GROUP BY는 해당 속성 값들을 그룹화하는 함수이다. 이 경우 'Sex'는 male과 female의 두개의 그룹으로 나뉠 것이다.
여기에 COUNT함수를 적용하면, 각각의 그룹에 속하는 투플 수를 보여준다.

SELECT `Sex`, COUNT(*) CNT FROM `kaggle`.`titanic` GROUP BY `Sex` HAVING CNT > 200; 위의 코드처럼 'Sex' 속성을 그룹화하여 count한 뒤, HAVING (조건) 을 이용해서 count값이 200보다 큰 값만 출력되도록 하는 코드이다.
count값을 CNT로 지정해서 HAVING 조건을 이용한 것이 특징이다.
위의 결과를 보면 male은 count값이 266, female은 152이기 때문에 male의 값만 출력되었다.

SELECT `Sex`, `survived`, COUNT(*) FROM `kaggle`.`titanic` GROUP BY `Sex`, `Survived` ;'Sex' 속성과 'survived' 속성을 각각 그룹화하여 count값을 출력하는 코드이다.
이 값을 보면 남자는 모두 생존하지 못했고, 여자는 모두 생존했음을 알 수 있다.

SELECT floor(`Age`/10) * 10 + 10, COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0 group by 1; floor는 반올림을 해주는 함수이다. 연령대별로 몇 명의 사람이 있는지 알아보기 위해서 'Age'를 10으로 나눈 값을 반올림하고, 10을 곱한 뒤, 0~9의 값이 있기 때문에 10을 더해준다. 그러면 이 값 미만의 사람들이 몇 명있는지 알아볼 수 있다.

SELECT floor(`Age`/10) * 10 + 10, COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0 group by 1 order by 1;위의 값들을 오름차순으로 정렬하는 코드이다.
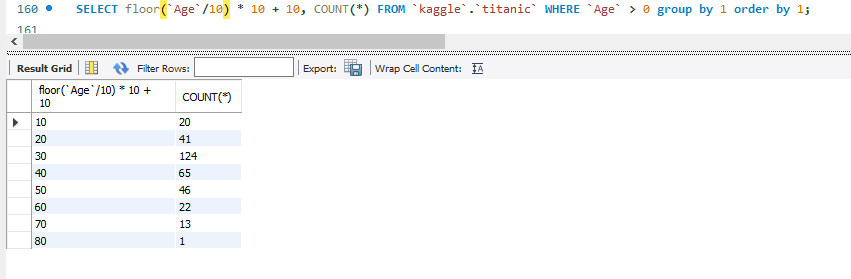
SELECT floor(`Age`/10) * 10 + 10, COUNT(*) FROM `kaggle`.`titanic` WHERE `Age` > 0 group by 1 order by 1 desc;위의 값들을 내림차순으로 정렬하는 코드이다.

SELECT floor(`Age`/10) * 10 + 10, `survived`, COUNT(*) CNT FROM `kaggle`.`titanic`
WHERE `Age` > 0 group by 1, 1 HAVING CNT > 40 order by 1 desc, 2 desc;위의 코드처럼 'Age'를 연령대 별로 나누고, 그 중 count값이 40보다 큰 값에 대해 'Age' 값과 'survived' 값을 각각 내림차순으로 정렬하는 코드이다.

#서브쿼리: 하나의 SQL문 안에 들어있는 또 다른 SQL문(쿼리)! 괄호( )로 나타낸다.
#서브쿼리가 조건절이 됨. 결과에 해당하는 데이터를 조건으로 해서 메인쿼리 실행.
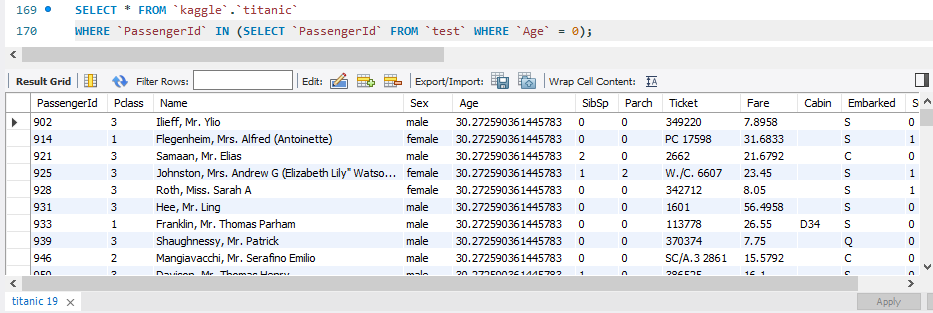
SELECT * FROM `kaggle`.`titanic`
WHERE `PassengerId` IN (SELECT `PassengerId` FROM `test` WHERE `Age` = 0); 서브쿼리// 'test' 테이블에서 'Age'값이 0인 'PassengerId'를 찾는다.
메인쿼리// 그 'PassengerId'를 가진 값의 모든 데이터를 출력한다. ('PassengerId'가 JOIN으로 연결되어있기 때문에 같은 값임)

UPDATE `kaggle`.`titanic`
SET `Age` = 30.272590361445783
WHERE `PassengerId` IN (SELECT `PassengerId` FROM `test` WHERE `Age` = 0) ;위의 코드대로 'Age' 값이 0인 데이터를 찾아서 그 값들의 'Age' 값을 평균인 30.272590361445783로 업데이트하는 코드이다.
업데이트한 후 위의 코드를 다시 실행시켜보면 'Age' 값이 모두 변경된 것을 볼 수 있다.
위의 코드는 'test' 테이블에서 'Age' 값이 0인 투플을 찾은 것이기 때문에 'titanic' 테이블에서 값을 변경한 뒤 다시 확인하기에 좋았다.
'Database > SQL' 카테고리의 다른 글
| [MySQL] SQL 옵티마이저 (0) | 2021.01.18 |
|---|---|
| [MySQL] 데이터 제어어 : DCL (0) | 2021.01.18 |
| [MySQL] University DB 예제 (0) | 2021.01.10 |
| [MySQL] MySQL 설치하기 (0) | 2021.01.10 |
| [MySQL] 데이터베이스 개념 (0) | 2021.01.10 |