0. 단일 모집단의 추론
통계적 추론에서 한 개의 모집단을 추론하는 방법이다.
EX) 통계학 관련학과 취업률의 평균이 얼마나 될까?
평균을 알아보기 위해 표본을 몇 개 추출해야 하는가?
남녀의 출생성비가 얼마나 될까?
안정적으로 제품이 생산되고 있는가?
1. 모평균
- 모집단 가정 : N(μ, σ²) // 정규성에 대한 가정확인 필요
- 확률 표본 : X1, X2, ..., Xn ~ iid N(μ, σ²) // iid: 서로 독립이며 동일한 분포를 가진다. (정규분포)
1.1 점추정
μ <= x̅ ~ N( μ, σ²/n )
(표준화) ( x̅ - μ ) / ( σ / √n ) ~ N( 0, 1 ) => 중심축량 (σ 알 때)
σ 모를 때) ( x̅ - μ ) / ( S / √n ) ~ t(n-1)
1.2 t-분포
X1, X2, ..., Xn ~ iid N(μ, σ²) 이면, T = ( x̅ - μ ) / ( S / √n ) ~ t(n-1)
- 자유도가 n-1 인 t-분포
: 0을 중심으로 대칭
정규분포보다 양쪽 꼬리가 두꺼움
자유도가 커질수록 표준정규분포에 근접
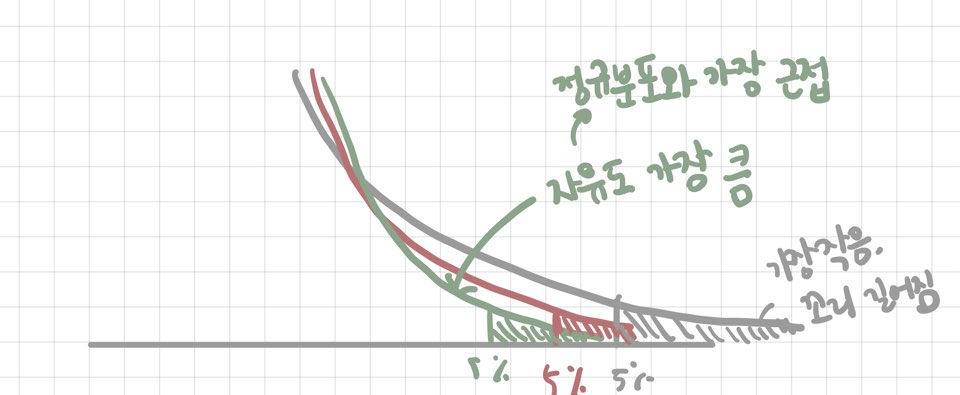

정규분포표와는 다르게 자유도와 확률로 구성된 t-분포표이다.
자유도에 따라 t-분포의 모양이 다르기 때문이다.

이처럼 확률과 자유도를 활용해서 그에 해당하는 tα 값을 찾을 때 이용한다.
tα 값은 구간추정이나 기각역을 설정할 때 임계값으로 활용된다.
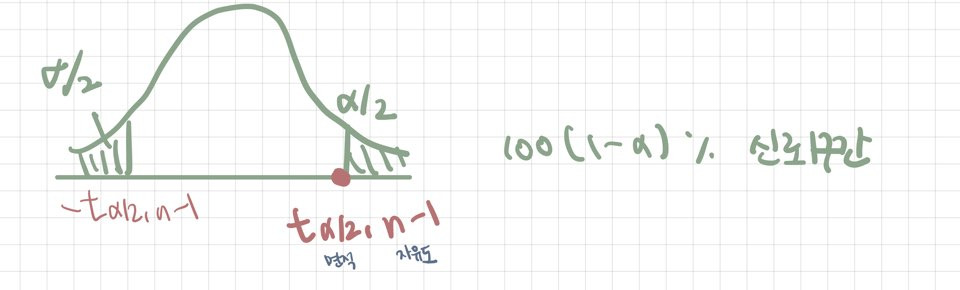
1.3 구간추정
100(1-α)% 신뢰구간을 구할 때
1-α = P( -t(α/2,n-1) ≤ T ≤ t(α/2,n-1) )
= P( -t(α/2,n-1) ≤ ( x̅ - μ ) / ( S / √n ) ≤ t(α/2,n-1) )
= P( x̅ - t(α/2,n-1) S / √n ≤ μ ≤ x̅ + t(α/2,n-1) S / √n )
=> [ x̅ - t(α/2,n-1) S / √n, x̅ + t(α/2,n-1) S / √n]
예제) 통계학 관련학과 취업률 - 42개 과 조사 결과
- ∑ xi = 2468.4, ∑ xi² = 154975.4
=> x̅ = 58.77, S² = 241.56, S = 15.54
- t(0.025, 41) = 2.020
- 신뢰구간 = [58.77 - 2.02 x 15.54/√42, 58.77 + 2.02 x 15.54/√42] = [53.93, 64.05]
1.4 가설검정
-
H0: μ = μ0 vs H1: (a) μ > μ0, (b) μ > μ0, (c) μ ≠ μ0
-
검정통계량 : T0 = ( x̅ - μ0 ) / ( S / √n ) ~ t(n-1)
-
유의수준 α일 때 기각역 : (a) t0 > t(α, n-1), (b) t0 < -t(α, n-1), (c) |t0| > t(α/2, n-1)
예제) 통계학 관련학과 취업률
해당년도 전체 대졸자 취업률이 54.5%일 때 통계학과 취업률 평균이 더 높은가?
-
H0 : μ = 54.5, H1 : μ > 54.5
-
T = (58.77 - 54.5) / (15.54 / √42) = 1.78 > t(0.05, 41) = 1.683
=> 귀무가설이 기각되었기 때문에 5% 유의수준에서 통계학과 취업률 평균이 더 높다고 볼 수 있다.
1.5 정규모집단으로부터 추출된 확률표본 ~ t(n-1)
=> 자료에 대한 정규성 검정 필요
-
히스토그램, Q-Q plot -> 그림으로 판단한다. (이상치 유무 ∵ x̅, S가 이상치에 민감)
-
Jarque-Bera test, Shapiro-Wilk test 등 ...
JB = (n/6) (b1 + 1/4 (b2 - 3)² ) = χ²(2)
- √b1 : 왜도 (기울어짐, 대칭 등의 모양을 나타냄, 대칭일 때 왜도 = 0)
- b2 : 첨도 (꼬리가 얼마나 두꺼운지 나타냄, 정규분포일 때 첨도 = 3)
1.6 정규성을 만족하지 않는 경우
대표본, 비모수적인 방법, 재표집 방법이 있지만, 비모수적인 방법은 '비모수 통계'에서, 재표집 방법은 대학원에서 배운다.
[대표본의 경우]
-
표본 크기가 큰 경우 → 중심극한정리에 의해 x̅ ≅ N( μ, σ²/n)
- Z = ( x̅ - μ ) / ( σ / √n ) ≅ N( 0, 1 )
=> T = ( x̅ - μ ) / ( S / √n ) ≅ N( 0, 1 )
-
100(1-α)% 신뢰구간 ≅ [ x̅ - Z(α/2) S / √n, x̅ + Z(α/2) S / √n ]
- 검정통계량 : Z0 = ( x̅ - μ0 ) / ( S / √n ) ≅ N( 0, 1 )
예제) A 담배에 포함된 평균 니코틴 함유량을 알아보기 위해 100개의 A 담배를 임의추출하여 조사한 결과 평균 함유량이 0.53mg, 표준편차는 0.11mg 으로 나타났다. 실제 평균 니코틴에 대한 95% 신뢰구간은?
[0.53 - 1.96 x 0.11 / √100, 0.53 + 1.96 x 0.11 / √100]
= [0.508, 0.552]
소비자 단체에서 A 담배에 포함된 니코틴 함유량이 표지에 표시된 0.5mg보다 많다고 주장한다. 위의 결과를 토대로 니코틴 함유량 평균이 표기된 것보다 많은지를 5% 유의수준에서 검정해보자.
Z = (0.53 - 0.5) / (0.11 / 10) = 0.03 / 0.011 = 2.727 > 1.645 = Z(0.05)
=> 귀무가설 기각 → 실제 니코틴 함유량은 표기된 0.5mg보다 많다.
1.7 모수 추정을 위한 표본크기 추정
-
표본 수집은 비용, 시간 등의 제약 조건에 영향을 받는다.
-
표본의 크기는 모수 추정의 정확도 및 신뢰도에 영향을 준다.
-
신뢰수준 <= 신뢰도
-
오차범위(δ) (오차: x̅ - μ) <= 정확도
-
100(1-α)% 신뢰수준에서 허용오차범위가 ±δ 일 때
P( |x̅ - μ| < δ) = 1-α

예를 들어, σ (=S) = 5, 95% 신뢰수준, 오차범위 ±1.5 일 때
n = (1.96 / 1.5)² x 25 = 42.68 => 최소 43개의 표본이 필요하다.
2. 분산 (표준편차)
-
모집단 가정 : N(μ, σ²) // 정규성에 대한 가정확인 필요
-
확률 표본 : X1, X2, ..., Xn ~ iid N(μ, σ²)
2.1 점추정
-
모수 σ <= 표본분산 : S² = 1 / (n-1) ∑ (xi - x̅)²
-
모수 σ² <= 표본표준편차 : S = √1 )/ (n-1) ∑ (xi - x̅)²
-
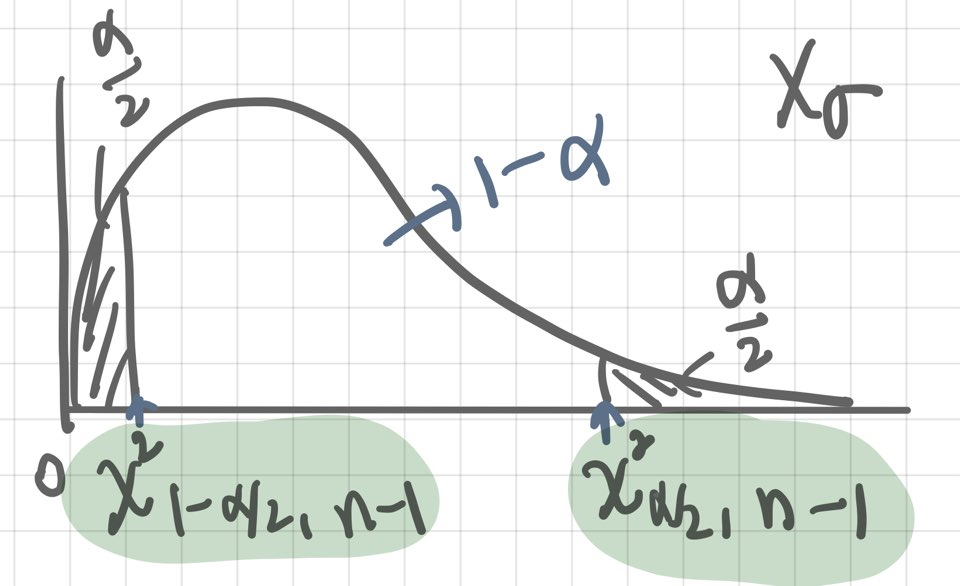
중심축량 = (n - 1) S² / σ² ~ χ²(n-1) // 유도는 '수리통계학'에서

예를 들어, 16개의 표본으로 σ²의 95% 신뢰구간을 구해보자.
정규분포와 t-분포는 0을 중심으로 대칭이기 때문에 0.5를 반으로 나눈 면적을 이용해서 가장 짧은 구간. 구할 수 있었다. 하지만, 카이제곱분포는 비대칭 형태이기 때문에 절반으로 나눈 것보다 더 짧은 구간을 구할 방법이 있다. 그러나 그 값은 구하기 매우 어렵기 때문에 카이제곱분포에서도 절반으로 나눠서 구간을 구한다.
그러면 다음과 같이 식을 세울 수 있다.
X² = (n-1) S² / σ² ~ χ²(n-1)
P( χ²(0.975, 15) ≤ X² ≤ χ²(0.025, 15)) = 0.95
= P( (n-1) S² / χ²(0.025, 15) ≤ σ² ≤ (n-1) S² / χ²(0.975, 15) )
σ²의 100(1-α)% 신뢰구간을 공식으로 나타내면 다음과 같다.
[ (n-1) S² / χ²(α/2, n-1), (n-1) S² / χ²(1-α/2, n-1) ]
예제) 생산된 제품의 평균 강도보다는 안정적으로 생산되고 있는가에 더 관심이 있어 제품 강도의 표준편차 σ를 추정하기 위해 무작위로 8개를 선택하여 제품강도를 측정했다.
S² = 3.65, χ²(0.025, 7) = 1.69, χ²(0.975, 7) = 16.013
- σ²의 95% 신뢰구간
= [7 · 3.65 / 16.013 , 7 · 3.65 / 1.69]
= [1.596, 15.122]
- σ의 95% 신뢰구간
= [√1.596, √15.122]
= [1.263, 3.889]
2.2 가설검정
- H0: σ² = σ²0 vs H1: (a) σ² > σ²0, (b) σ² > σ²0, (c) σ² ≠ σ²0
- 검정통계량 : X² = (n-1) S² / σ²0 ~ χ²(n-1)
- 유의수준 α일 때 기각역 : (a) X²0 > χ²(α, n-1), (b) X²0 < χ²(1-α, n-1), (c) X² > χ²(α/2, n-1) or X² < χ²(1-α/2, n-1)
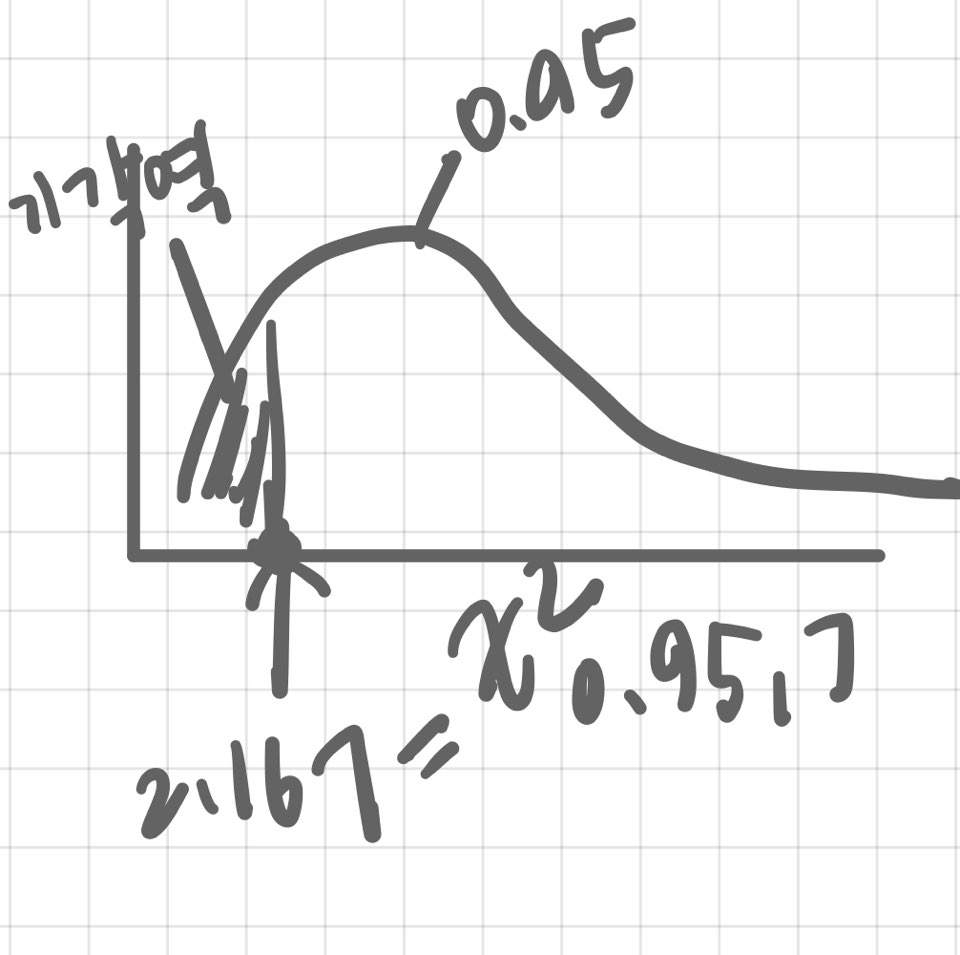
앞의 예제) 표준편차가 2 미만일 때 안정적인 품질관리가 유지된다고 할 때 품질관리가 유지되는지 검정하여라.
- H0 : σ = 2 vs H1 : σ < 2 => H0 : σ² = 4 vs H1 : σ² < 4
- 검정통계량 : X² = (n-1) S² / 4 ~ χ²(n-1)
- 5%의 유의수준에서 X² = 7 · 3.65 / 4 = 6.389 > χ²(0.95, 7) = 2.167
=> 검정통계량이 기각역에 포함되지 않기 때문에 대립가설이 기각된다.
따라서 품질이 안정적으로 유지되고 있다고 볼 수 없다.
3. 모비율 π
- 표본 크기가 큰 경우 (대표본)
- 베르누이 확률표본 X1, X2, ..., Xn ~ iid B(π)
- 성공횟수 X = X1+ ··· + Xn
3.1 점추정량
- 모수 π <= P = X / n : 표본비율
대부분의 교재에서 p와 p^으로 나타내는 것을 여기서는 각각 π와 P로 나타내겠다.
표본비율을 활용하기 위해 모집단을 π와 1-π 두 부분으로 나눠서 표본(X1, ···, Xn)을 구해보자.
π에 속한 표본을 1, 1-π에 속한 표본을 0이라고 했을 때 그 합을 X라고 하면, X는 이항분포 B(n, π)를 따른다.
모비율을 추론하기 위해 표본비율을 이용하려고 한다.
P = X / n ≅ N( π, π(1-π) / n )
n이 충분히 크면 중심극한정리에 의해 P가 정규분포에 근사한다. 따라서 위와 같이 나타낼 수 있다.
정규근사를 하는 조건은 nπ ≥ 5, n(1-π) ≥ 25 정도면 적절하다.
표준화를 하면
Zp = (P - π) / √π(1-π) / n ≅ N(0,1)
이와 같은 식이 나온다.
이때 Zp가 일종의 중심축량이 된다.
3.2 구간추정
1-α = P( -Z(α/2) ≤ (P - π) / √π(1-π) / n ≤ Z(α/2) )
= P( P - Z(α/2) · √π(1-π) / n ≤ π ≤ P + Z(α/2) · √π(1-π) / n )
이때 π의 표준오차범위에 π가 포함되어있기 때 π 대신 P를 사용한다.
=> [ P - Z(α/2) · √P(1-P) / n, P + Z(α/2) · √P(1-P) / n ]
예제) 1889년 한 지역에서 73380명의 신생아 중 아들이 38100명이었다.
이 지역의 아들의 출생비율 π에 대한 95% 신뢰구간을 구해보자.
P = 38100 / 73380 = 0.519
SE = √0.519 · 0.481 / 73380 = 0.00184
신뢰구간 = [0.519 - 1.96 · 0.0018, 0.519 + 1.96 · 0.0018]
= [0.5156, 0.5228]
3.3 가설검정
- H0: π = π0 vs H1: (a) π > π0, (b) π > π0, (c) π ≠ π0
- 검정통계량 : Z0 = ( P - π0 ) / √π0 · (1-π0) / n ~ N(0, 1)
- 유의수준 α일 때 기각역 : (a) Z0 > Zα, (b) Z0 < Zα, (c) |Z0| > Z(α/2)
앞의 예제) 그 당시 아들의 출생비율(π)이 딸의 출생비율보다 큰지 검정해보자.
- 가설 H0 : π = 0.5 vs H1 : π > 0.5
- 검정통계량 Z0 = (0.519 - 0.5) / √0.5 · 0.5 / 73380 ~ N(0, 1)
- 1% 유의수준 -> Z(0.01) = 2.326 < Z0 = 10.41
=> 검정통계량이 기각역에 포함되기 때문에 대립가설이 성립한다.
따라서 아들의 출생비율이 더 높았다고 볼 수 있다.
3.4 표본크기 결정
- 오차 : P - π
- 100(1-α)% 신뢰수준에서 허용오차범위 ±δ
1-α = P( |P - π| < δ )
=> δ = Z(α/2) · √π(1-π) / n
=> n = ( Z(α/2) / δ )² · π(1-π)
예를 들어, 95% 신뢰수준이고 표본오차는 ±3.1%인 설문조사라면 최소 1천명의 표본이 필요하다.
π에 대한 정보가 없는 보통의 경우에는 모든 π에 대해 성립하도록 n을 결정한다.
n = ( Z(α/2) / δ )² · π(1-π) 이 식에서 π(1-π)는 π = 0.5일 때 가장 크기때문에 π를 모르는 경우 0.5로 정한다.
예제) 95% 신뢰수준에서 오차범위 ±5% (δ = 0.05)인 경우
n = 1/4 · (1.69 / 0.05)² = 384.16 => 최소 385개의 표본이 필요하다.
'Statistics > 기초통계학' 카테고리의 다른 글
| [기초통계학] 통계적 추론 (0) | 2021.01.16 |
|---|