수업 출처) 숙명여자대학교 소프트웨어학부 수업 "데이터사이언스개론", 박동철 교수님
1. Intro
데이터 사이언스는 다양한 형태로부터 얻은 데이터로 지식이나 인사이트를 도출하는 융합적인 학문이다.
크게 컴퓨터 사이언스, 수학과 통계학, 경영학적 지식이 요구된다.
데이터 엔지니어는 데이터를 다루기 위한 소프트웨어와 시스템을 디자인하고 개발한다. 프로그래밍과 데이터베이스 지식을 필요로 한다. 가장 중요한 것은 데이터를 분석하기 전 전처리하는 과정을 맡는다는 것이다.
통계학자는 통계학적 이론과 방법을 실생활에 적용하여 문제를 해결한다. 통계학과 수학적 지식을 필요로 한다.
데이터 사이언티스트는 쉽게 말해서 둘 다 하는 사람이다. 분석적이고 기술적인 능력을 통해서 데이터로부터 인사이트를 도출한다. 위에서 말했듯이 프로그래밍, 통계, 경영학적 이해를 바탕으로 한다.
데이터 사이언티스트가 주로 필요로 하는 기술은 데이터 분석, 통계 분석 패키지 (R), 파이썬, 데이터 모델링, 머신러닝 등이다.
주로 IT & 서비스 직군에서 근무하며, 교육이나 금융 분야에서도 데이터 과학자를 필요로 한다.
2. Data Science
최근 경영 산업은 전반적으로 데이터를 수집하는 능력을 가지고 있다.
전략, 제조, 마케팅, 공급망 관리 등 모든 경영학적 측면에서 데이터 수집을 필요로 하고 있다.
이제 거대한 양의 데이터가 생산되면서 대부분의 기업들은 경쟁우위로써 데이터 수집에 집중하고 있다.
과거에는 통계학자와 분석가가 데이터셋을 수작업으로 탐색했다면, 이제는 데이터의 양이 커지면서 수작업으로는 분석을 하기 어려워졌다.
컴퓨터와 네트워크가 중요해진 것이다.
이를 통해 데이터 과학의 원리와 기술을 더 넓은 분야에 적용하게 되었다.
3. Data Mining
데이터 마이닝은 큰 데이터셋에서 패턴을 찾는 과정이다.
경영학적 측면에서는 주로 고객의 행동을 분석하는 데 활용한다.
고객의 패턴을 분석하여 타겟 마케팅, 온라인 광고, 추천, 신용 분석, 사기 탐색 등에 적용할 수 있다.
4. Data Science vs. Data Mining
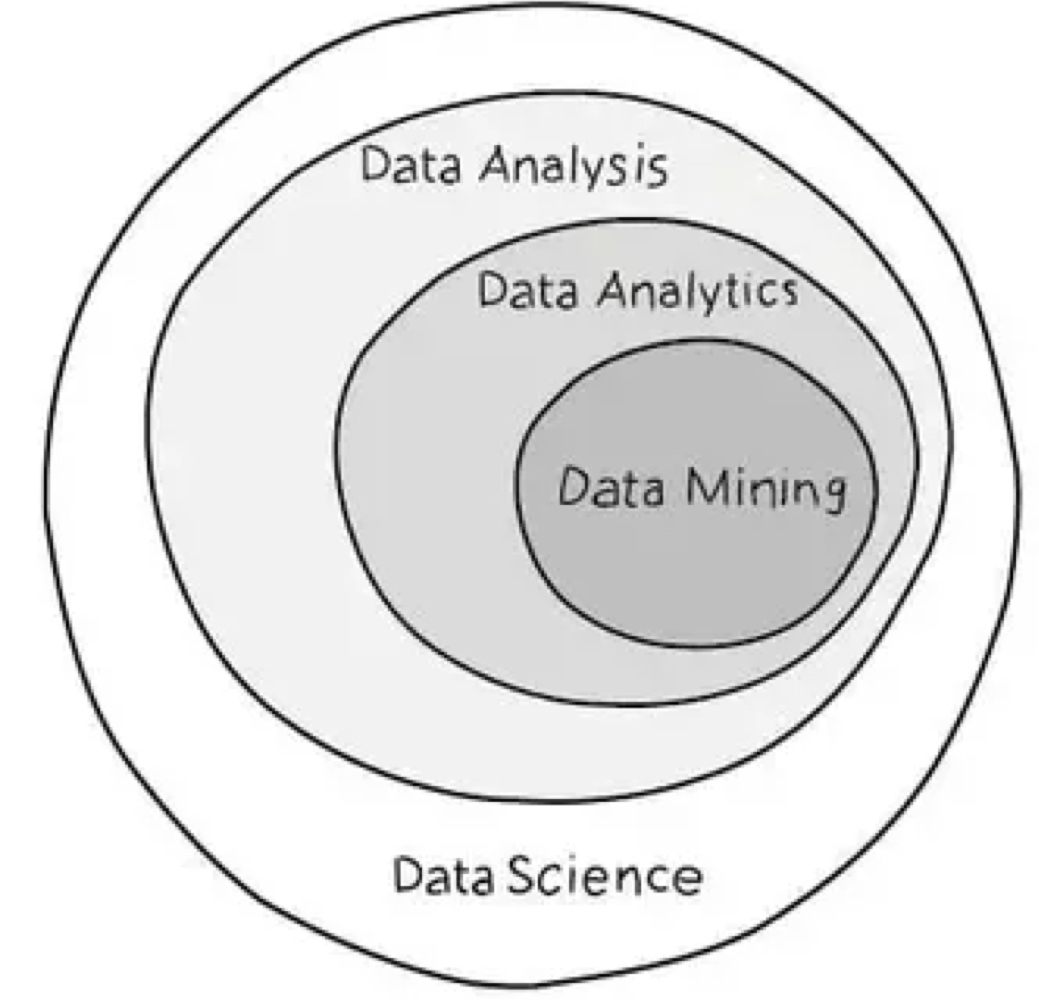
데이터 사이언스는 데이터에서 지식을 도출하도록 하는 일련의 근본적인 원칙이다.
데이터 마이닝보다 좀 더 넓은 의미로 사용된다.
데이터 마이닝은 데이터로부터 숨겨진 패턴을 찾는 과정으로, 보통 데이터 수집 및 가공 이후 첫번째로 수행되는 과정이다.
즉, 데이터 마이닝 기술은 데이터 사이언스의 근본 원리를 실체화한 것이라고 볼 수 있다.
데이터로부터 지식을 도출할 때에는 자명하지 않으면서 수치적으로 도출되어야 한다.
예를 들면 허리케인이 지나간 후 생수의 판매율이 20% 증가했다던가, 어떠한 과자가 기존보다 7배 많이 팔렸다던가 하는 형식으로 말이다.
또 한 가지 유명한 예시는 미국의 통신사 예시이다.
제한된 예산으로 고객이 다른 통신사로 넘어가는 것을 막을 방법을 찾아야 한다.
미국의 통신사 MegaTelco는 일반적으로 휴대폰 고객의 20%는 계약이 만료되면 다른 통신사로 떠나간다.
이제 휴대폰 시장이 포화되었기 때문에 통신사들은 고객을 유지하려고 노력하고 있다.
회사는 몇몇 고객들의 계약 만료 전에 특별 상품을 제공하려고 한다.
이때 어떻게 최대한 고객이탈을 막을 수 있도록 상품을 제공할 고객을 고를 수 있을까.
이럴때 데이터 사이언스가 활용되는 것이다.
5. Data-Driven Decision Making (DDD)
데이터기반 의사 결정은 단순한 직관보다는 데이터 분석에 기초한 의사 결정이다.
예를 들어, 광고를 할 때 한 사람의 경험과 직관에 기반하기보다는 소비자가 다른 광고에 어떻게 반응하는지에 대한 데이터 분석에 기초한다.
이 DDD에 데이터 사이언스가 필요하다.
자동화된 데이터 분석을 통해 현상을 이해하기 위한 방법, 과정, 기술 등을 제공한다.
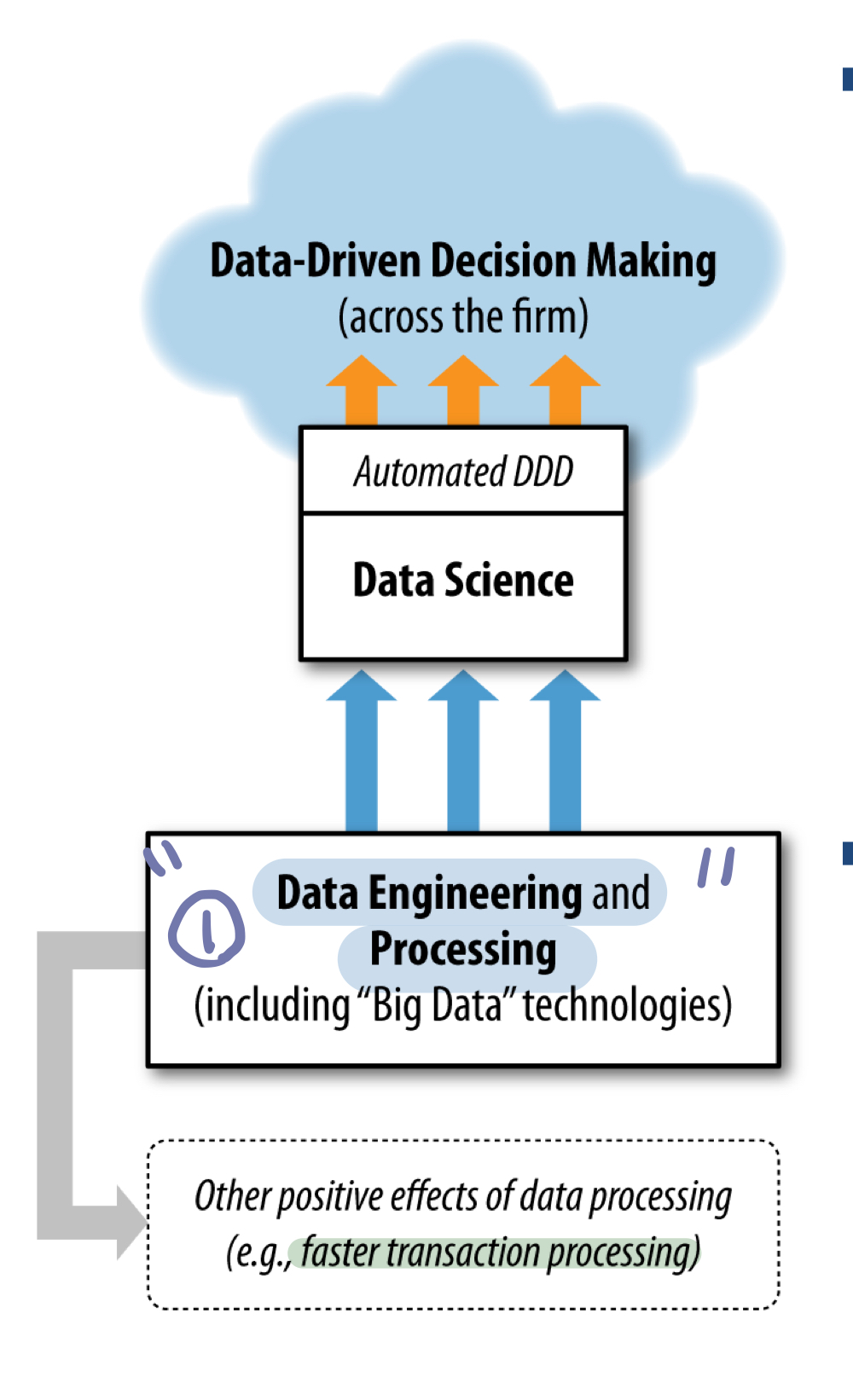
통계적으로 기업이 데이터기반 의사결정을 활용할수록 생산력이 4-6% 증가한다.
예를 들어, 마트의 고객은 주로 본인이 가던 곳만 가기 때문에 변화를 찾기 어렵지만, 아기가 태어남을 기점으로 한 번의 변화가 일어날 수 있다. 따라서 많은 상업자들은 아기가 태어난 것을 알고 새로운 고객에게 특별 상품(할인권 등)을 제공한다.
하지만 미국의 마트 '타겟'은 이것을 넘어서서 아기가 태어나기 전, 임신 전부터 그것을 예측하여 마케팅을 했다. 그 결과 그들의 경쟁자보다 더 높은 이익을 얻을 수 있었다.
점점 더 많은 비즈니스 결정이 컴퓨터 시스템에 의해 자동화되고 있다.
미리 설계된 알고리즘을 통해 거의 실시간으로 데이터를 분석하고 의사 결정을 하고 있다.
예를 들면, 은행과 통신사에서는 사기 범죄를 제어하고, 소매 업체에서는 상품화 결정 시스템을 자동화한다. 아마존과 넷플릭스는 추천 시스템을, 광고 회사는 실시간 광고 결정 시스템을 자동화한다.
6. Data Engineering vs. Data Science
데이터 엔지니어링과 데이터 사이언스는 다르다.
데이터 엔지니어링은 데이터를 처리하는 기술로, 시스템, 소프트웨어 디자인, 개발, 유지 및 보수 등을 포함한다.
오라클과 같은 데이터 베이스 시스템과 하둡, 스파크와 같은 빅데이터 플랫폼 등의 소프트웨어를 개발하고 유지한다.
이들을 통해서 데이터 사이언스를 support한다.
데이터 사이언스는 앞에서도 말했지만, 데이터를 모으고 탐색하고 분석한다.
데이터 엔지니어링 기술을 활용해서 데이터에 접근할 수 있다.

7. Data Science and Big Data
빅데이터는 네트워크와 컴퓨팅 기술의 발달로 전통적인 데이터 처리 시스템으로 관리하기에는 너무 큰, 따라서 새로운 처리 기술이 필요한 데이터셋을 말한다.
빅데이터의 4가지 특징으로는 크기, 다양성, 속도, 정확성이 있다.
빅데이터 기술은 위의 4가지 특징 (4V)을 다룬다.
이를 위해 데이터 사이언스를 활용한다.
예시로는 Hadoop, HBase, MongoDB, Spark 등이 있다.
데이터와 데이터로부터 유용한 지식을 도출하는 능력은 핵심 전략 자산으로 간주되어야 한다.
이는 최상의 결과를 내기 위해 적절한 데이터와 데이터 사이언스 기술 두가지 모두에 투자해야한다는 것이다.
8. Data-Analytic Thinking
실생활 문제에 직면했을 때, 우리는 그 문제를 "분석적으로" 바라보아야 한다. 데이터가 성능을 향상시킬 수 있는지 여부와 그 방법을 정량적으로 평가해야 한다.
데이터 분석적 사고는 일련의 근본적인 개념과 원칙에 의해 가능해진다. 시스템적인 틀(framework) 을 구조화해야 한다.
데이터 분석적 사고를 통해서 다른 사람들과 능숙하게 교류할 수 있고, 데이터기반 의사 결정을 향상시킬 수 있으며 데이터 중심의 경쟁 위협을 바라보는 사고를 기를 수 있다.
최근 산업, 기업에서는 수익을 높이고 비용을 절감하기 위해 데이터 사이언스 팀을 만들고 있고, 주요 전략 요소에 데이터 마이닝을 사용하고 있다.
데이터 사이언티스트가 아니더라도 매니저, 마케터, 경영 전략가 등의 직업에서도 데이터 사이언스를 활용한다.
9. Example of Fundamental Concepts
1) 자료에서 유용한 지식을 추출하기 위해 체계적인 절차를 밟는다.
체계적인 절차란 명확히 정의된 단계를 말한다. (ex) 문제 분석 -> 모델링 -> 면밀한 평가
이러한 과정은 데이터에 대한 우리의 생각을 구조화하기 위한 틀을 제공한다.
2) 대량의 데이터에서 관심있는 개체에 대한 정보 속성을 찾는다.
즉, 우리에게 필요한 정보를 제공하는 변수를 찾는 것이다.
3) overfitting을 피한다.
모델링을 하는 이유는 새로운 데이터를 "예측"하기 위함이다.
overfitting된 모델은 특정 training data에만 적합할 뿐, 새로운 데이터에 대해서는 좋은 성능을 낼 수 없다.
4) 마이닝 결과를 신중하고 객관적으로 평가한다.
우리가 도출한 결과가 얼마나 더 나은지 공식화 해야 한다.
단순히 더 낫다가 아니라 얼마나 더 나은지 보여주어야 한다.
10. Engineering side of Data Science
데이터 사이언티스트는 두가지 종류의 능력을 갖춰야 한다.
1) Science
- 이론적인 개념과 원칙을 실제 상황에 적용하는 능력
- ex) logistic regression, support vector machines
2) Technology
- 트렌드에 맞는 (상황에 맞는, 인기있는) 프로그래밍 언어와 툴을 사용하는 능력
- ex) Hadoop, MongoDB, Spark, TensorFlow
최근에는 특정 종류의 소프트웨어 툴에 익숙하지 않은 데이터 과학자를 상상하기 힘들다.
그럼에도 우리는 기술보다 과학에 조금 더 집중해야 한다. 우세한 기술들은 빠르게 바뀌기 때문이다.
'Software > Data Science Introduction' 카테고리의 다른 글
| [데이터사이언스개론] Similarity, Neighbors, Clusters (0) | 2021.06.04 |
|---|---|
| [데이터사이언스개론] Overfitting and Avoidance (0) | 2021.04.22 |
| [데이터사이언스개론] Fitting Model to data (0) | 2021.04.22 |
| [데이터사이언스개론] Predictive Modeling (0) | 2021.04.21 |
| [데이터사이언스개론] 비즈니스 문제와 데이터 사이언스 솔루션 (0) | 2021.04.15 |