1. K-NN
- 주변의 가장 가까운 K개의 데이터를 보고 새로운 데이터를 판단하는 알고리즘
- N개의 특성을 가진 데이터는 n차원의 공간에 점으로 표현됨
- 유사한 특성의 데이터는 거리가 가깝고, 다양한 거리 함수를 통해 데이터 간 거리를 구할 수 있음
- KNN 분류
- 종속변수 Y : 범주형 데이터 -> 어떤 범주에 속하는지, K개 중 과반수 의결에 의해 분류
- KNN 회귀
- 종속변수 Y : 연속형 데이터 -> K개의 최근접 이웃이 가진 평균
2. 최적의 K 값 찾는 방법
- 최적의 K값은 데이터에 의존적이며, 현실적으로 만족할만한 수준의 값을 찾음
- Trial & Error → Python 반복문 사용
- 매우 작은 K는 overfitting 초래: 데이터의 지역적 특성을 지나치게 반영함
- 매우 큰 K는 underfitting 초래: 모델이 과하게 정규화됨
1) 방법
- K 후보군 결정 : 1부터 학습데이터 개수 -1까지, 데이터 개수가 많다면 1부터 √n까지
- Train & Test 도는 Validation 데이터에 대해 knn 에러율 구함
- 에러율이 가장 낮은 K 선택
2) 종속변수가 범주형일 경우
- Tie 문제를 막기 위해 K는 홀수 권장
- 짝수일 경우 2:2, 3:3 등으로 동일하게 나뉠 수 있기 때문
3) 종속변수가 연속형일 경우
- Inverse distance weighted average 고려 가능
- 거리가 가까운 관측치들에게 가중치를 부과해 가중평균으로 구하는 것
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
cancer = load_breast_cancer()
x_train, x_test, y_train, y_test = train_test_split(cancer.data, cancer.target,
test_size = 0.3, stratify = cancer.target, random_state = 100)
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1, 101)
for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors = n_neighbors)
clf.fit(x_train, y_train)
training_accuracy.append(clf.score(x_train, y_train))
test_accuracy.append(clf.score(x_test, y_test))
plt.plot(neighbors_settings, training_accuracy, label = 'train_accuracy')
plt.plot(neighbors_settings, test_accuracy, label = 'test_accuracy')
plt.ylabel('accuracy')
plt.xlabel('n_neighbors')
plt.legend()
plt.show()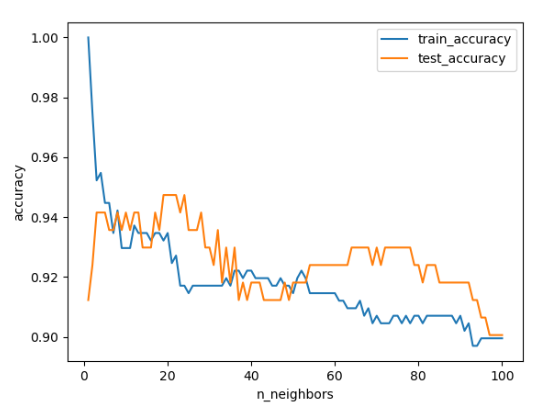
3. K-NN 회귀
- K개의 최근접 다변량 이웃 샘플로부터 연속 변수를 예측하기 위해 사용
- 이웃 샘플의 타겟값을 평균하여 예측하고자 하는 데이터의 예측값으로 사용
- 다양한 회귀 모델의 평가지표를 통해 모델 성능 측정
- 결정계수(R²), MSE, RMSE, MAE, MAPE, MPE
- 훈련 세트, 테스트 세트에 대한 평가 점수를 통해 과대/과소 적합 / 적정 판단
1) 장점
- 학습 데이터의 노이즈에 크게 영향 받지 않음
- 학습 데이터의 수가 충분하다면 상당히 좋은 성능을 보임
- 훈련 단계가 빠름
- 데이터의 분산까지 고려하면 상당히 robust 해짐
2) 단점
- 모델을 따로 생성하지 않아 특징과 클래스 간의 관계를 이해하는 부분에 제약이 있음
- 최적 이웃 수와 사용할 거리 척도를 데이터 각각의 특성에 맞게 연구자가 임의로 설정해야 함
- 새 관측치와 각 학습 데이터 간의 거리를 전부 측정해야하므로 '분류, 예측' 단계가 느림
3) 사용시 유의점
- combining rule : KNN은 주변 이웃의 분포에 따라 예측 결과가 달라짐
- 다수결
- 가중합 : 거리(유사도)가 가까울수록 더 큰 가중치 부여
- 정규화
- 데이터 간 분포가 크게 다를 경우 각 변수의 차이를 해석하기 어려움
- 알고리즘의 적절한 적용을 위해 정규화 과정 필요
4. 거리 함수
1) 유클리드 거리(Euclidean Distance) = L2 Distance
- 연속 변수에서 가장 일반적으로 사용하는 거리 척도
- 관측치 사이의 최단거리
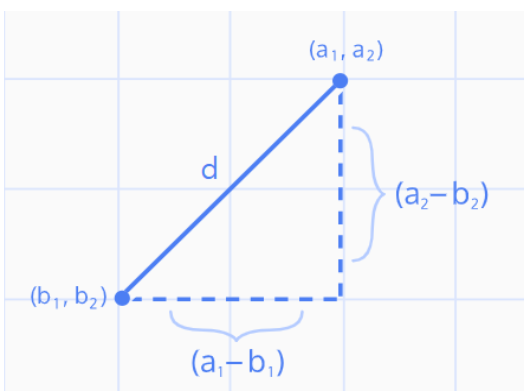

- 유클리드 함수를 채택할 경우 K를 정하기 위해 반드시 '정규화'가 선행되어야 함
2) 맨해튼 거리(Manhattan Distance) = L1 Distance
- 각 좌표축 방향으로만 이동할 경우에 계산되는 거리
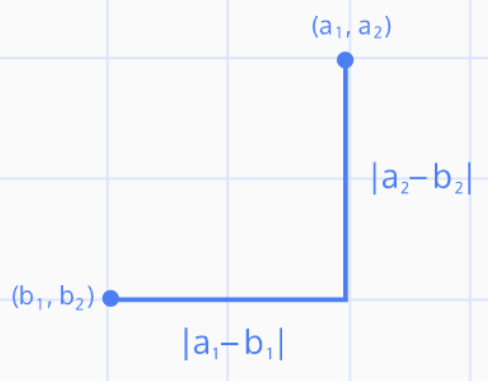
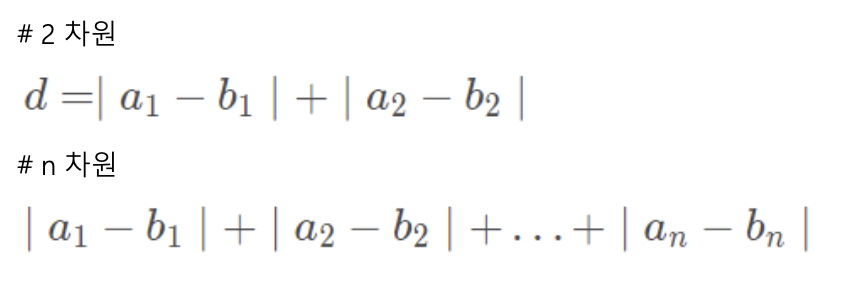
3) 해밍 거리(Hamming Distance)
- 두 개의 이진 데이터 문자열을 비교하기 위한 지표
- 두 문자열의 각 위치의 문자 비교 → 동일하지 않은 문자 수 = '해밍 거리'
- 길이가 같은 두 개의 이진 문자열 비교 시 해밍 거리는 두 비트가 다른 비트 위치의 개수
- 해밍 거리 d가 d >= 2a + 1이면 a개의 오류를 정정할 수 있음
- Feature를 벡터화할 때
- Clustering에서 독립변수가 범주형일 경우
- 네트워크를 통해 전송될 때 오류 감지 / 수정에 사용
- 자연어 처리에서 데이터 간 형태적 유사성(단어 간 거리)을 계산해 유사도 평가할 때
5. 회귀 모델 평가 지표
1) 결정계수 (R² Score)
- 모델이 데이터를 얼마나 잘 예측하는지에 대한 지표
- 실제 값의 분산 대비 예측 값의 분산 비율
- 평균으로 예측했을 때의 오차(총오차)보다 모델을 사용했을 대 얼마나 더 좋은 성능을 내는지 비율로 나타낸 값
- R : 표본 상관계수

- SST : 총 제곱합 SST = Σ(yᵢ - y̅)²
- SSE : 설명된 제곱합 SSE = Σ(^yᵢ - y̅)²
- SSR : 잔차 제곱합 SSR = Σ(^uᵢ)² # ^uᵢ 잔차 = 표본집단 회귀식에서 예측된 값 - 실제 관측값
- R² = 0 : x, y는 선형 관계 없음
- R² = 1 : x, y는 완벽한 선형 관계
- R²가 1에 가까울수록 회귀 모형이 적합함
# sklearn
r2_score(y_true, y_pred, sample_weight = None, multioutput = 'uniform_average')
'''
y_true : 올바른 목표값
y_pred : 예상 목표값
sample_weight : 가중치
'uniform_average' : 모든 출력의 오차를 평균 무게로 평균화
'''
2) 오차 제곱 평균 MSE (Mean Squared Error)
- 예측 값과 실제 값의 차이의 제곱에 대해 평균을 낸 값
- 이상치에 민감
- MSE 값이 작을수록 좋지만, 과대적합이 될 수 있음
- MSE의 범위는 0~무한대
- MSE가 100일 때 이 모형이 좋은지 기준이 없어 판단이 어려움 → MAPE의 퍼센트 값을 이용해 성능 평가하기도 함
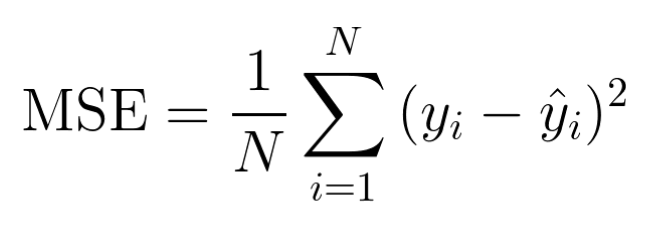
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_true, y_pred)
print("mse = {:.3f}".format(mse_))
# mse = 11.264
3) 평균 제곱근 오차 RMSE (Root Mean Squared Error)
- MSE에 루트를 씌운 값
- MSE의 장단점을 거의 그대로 따라감
- 제곱 오차에 대한 왜곡 줄여줌 + robust함에서 강점을 보임
- 오류 지표를 루트를 통해 실제값과 유사한 단위로 변환하기 때문에 해석이 쉬움
- 실생활에서 쓰는 계산법을 벗어났기 때문에 'RMSE로 구한 에러값만큼 모델이 틀리다'고 말할 수는 없음
- 그럼에도 큰 오류값 차이에 대해 큰 패널티를 주는 이점
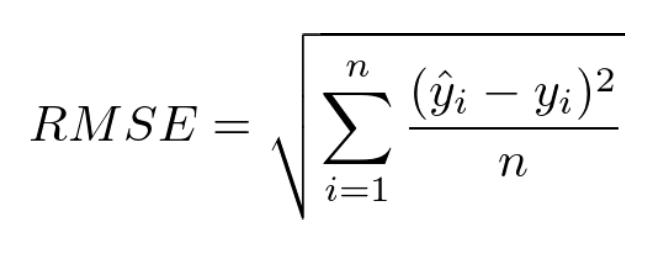
rmse = np.sqrt(mse)
4) 평균 절대 오차 MAE (Mean Absolute Error)
- 절대값을 취하기 때문에 가장 직관적으로 알 수 있는 지표
- MSE보다 특이치에 robust (제곱하지 않아 이상치에 덜 민감)
- 절대값을 취하기 때문에 모델이 underperformance인지 overperformance인지 알 수 없음
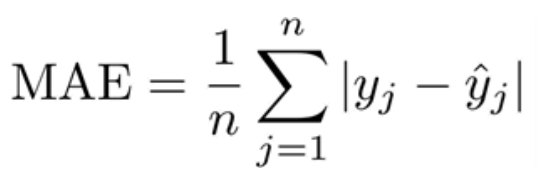
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y_true, y_pred)
5) 평균 절대비 오차 MSPE (Mean Absolute Percentage Error)
- MAE와 마찬가지로 MSE보다 이상치에 robust
- MAPE는 퍼센트값을 가지며 0에 가까울수록 회귀 모형의 성능이 좋다고 볼 수 있음
- 0~100% 의 값을 가지므로 성능 비교 해석 가능
- 추가적으로 모델에 대한 편향 존재 → MPE를 통해 대응 & 0 근처의 값에 대해서는 사용하기 어려움
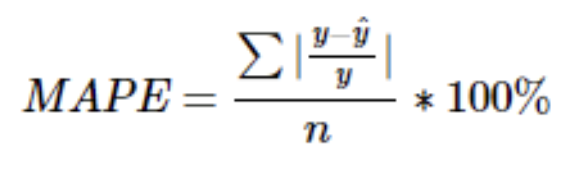
mean_absolute_percentage_error(y_true, y_pred)
6) MPE (Mean Percentage Error)
- MAPE에서 절대값을 제외한 지표
- 과대평가인지 과소평가인지 알 수 있어 유용함
- MAE, MSE는 절대 오차 측정 / MAPE, MPE는 상대 오차 측정
- sklearn에서 구현된 것이 보이지 않음
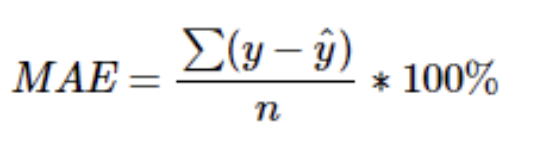
def MPE(y_true, y_pred):
return np.mean((y_true - y_pred) / y_true) * 100
MPE(y_true, y_pred)
6. KNN 회귀 구현
class sklearn.neighbors.KNeighborsRegressor(n_neighbhors=5, *, weights='uniform', algorithm='auto',
leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None):
'''
n_neighbors: 이웃의 수 K (defualt = 5)
weights: 예측에 사용되는 가중 방법 결정 (default = 'uniform') or callable
"uniform" : 각각의 이웃이 모두 동일한 가중치
"distance" : 거리가 가까울수록 높은 가중치
callable : 사용자가 직접 정의한 함수 사용
algorithm('auto', 'ball_tree', 'kd_tree', 'brute') : 가장 가까운 이웃을 계산할 때 사용할 알고리즘
"auto" : 입력된 훈련 데이터에 기반해 가장 적절한 알고리즘 사용
"ball_tree" : Ball-Tree 구조
"kd_tree" : KD-Tree 구조
"brute" : Brute-Force 탐색 사용
leaf_size : Ball-Tree나 KD-Tree의 leaf size 결정 (default = 30)
- 트리를 저장하기 위한 메모리, 트리의 구성과 쿼리 처리 속도에 영향
p : 민코프스키 미터법의 차수 결정 (1이면 맨해튼 거리, 2이면 유클리드 거리)
'''
from sklearn.neighbors import KNeighborRegressor
knr = KNeighborsRegressor()
knr.fit(train_input, train_target)
knr.score(test_input, test_target) # 테스트 모델에 대한 평가
# 0.9928094061
test_prediction = knr.predict(test_input) # 테스트 세트에 대한 예측
knr.score(train_input, train_target) # 훈련 모델에 대한 평가
# 0.9698823289 이 경우는 과소적합 (훈련 < 테스트 점수)
knr.n_neighbors = 3 # 모델을 훈련세트에 잘 맞게 하기 위해 k 줄임 (5→3)
knr.fit(train_input, train_target) # 재훈련
knr.score(train_input, train_target)
# 0.9804899950
knr.score(test_input, test_target)
# 0.9746459963 # 훈련 > 테스트 점수이고, 차이가 크지 않으므로 적합!
knr.KNeighborRegressor()
x = np.arange(5, 45).reshape(-1, 1)
knr.n_neighbors = 3
knr = KNeighborsRegressor()
x =np.arange(5, 45).reshape(-1, 1) # 5에서 45까지 x 좌표 생성
for n in [1, 5, 10]:
knr.n_neighbors = n
knr.fit(train_input, train_target) # 모델 훈련
prediction = knr.predict(x) # 지정한 범위 x에 대한 예측
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.title('n_neighbors = {}'.format(n))
plt.xlabel('length')
plt.ylabel('weight')
plt.show()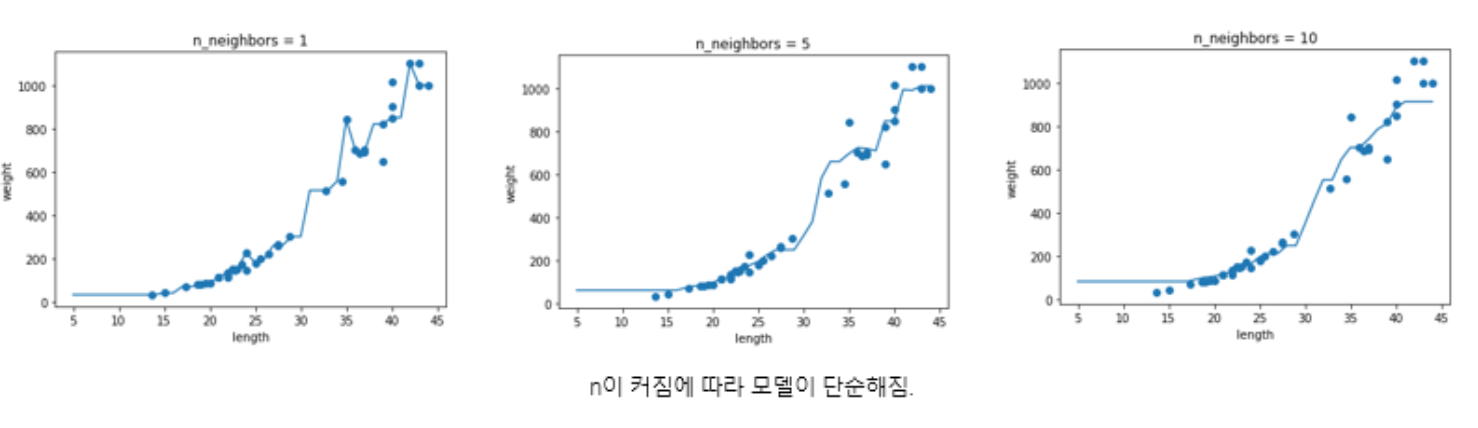
7. 과대 적합 / 과소 적합
1) 과대 적합 overfitting
- 모델이 훈련 세트에는 좋은 성능을 내지만, 테스트 세트에서는 낮은 성능을 내는 경우
- 훈련 세트와 테스트 세트에서 측정한 성능 간격이 큼 = 분산이 큼
- 주요 원인: 훈련 세트에 충분히 다양한 샘플이 포함되지 않음
- 해결 방법
- 훈련 세트에 충분히 다양한 샘플 포함시키기
- 모델이 훈련 세트에 집착하지 않도록 가중치 제한하기 (모델의 복잡도 낮춤)
- 훈련 데이터의 잡음 줄이기 (outlier, error 제거)
2) 과소 적합 underfitting
- 훈련 세트와 테스트 세트의 성능에는 차이가 크지 않지만 모두 낮은 성능을 내는 경우
- 훈련 세트와 테스트 세트의 성능이 서로 가까워지면 성능 자체가 낮음
- 편향이 큼
- 해결 방법
- 복잡도가 더 높은 모델 사용
- 가중치 규제 완화
'ML & DL' 카테고리의 다른 글
| [BITAmin] 선형 회귀 (0) | 2023.01.23 |
|---|---|
| [BITAmin] 데이터 전처리 (0) | 2023.01.23 |