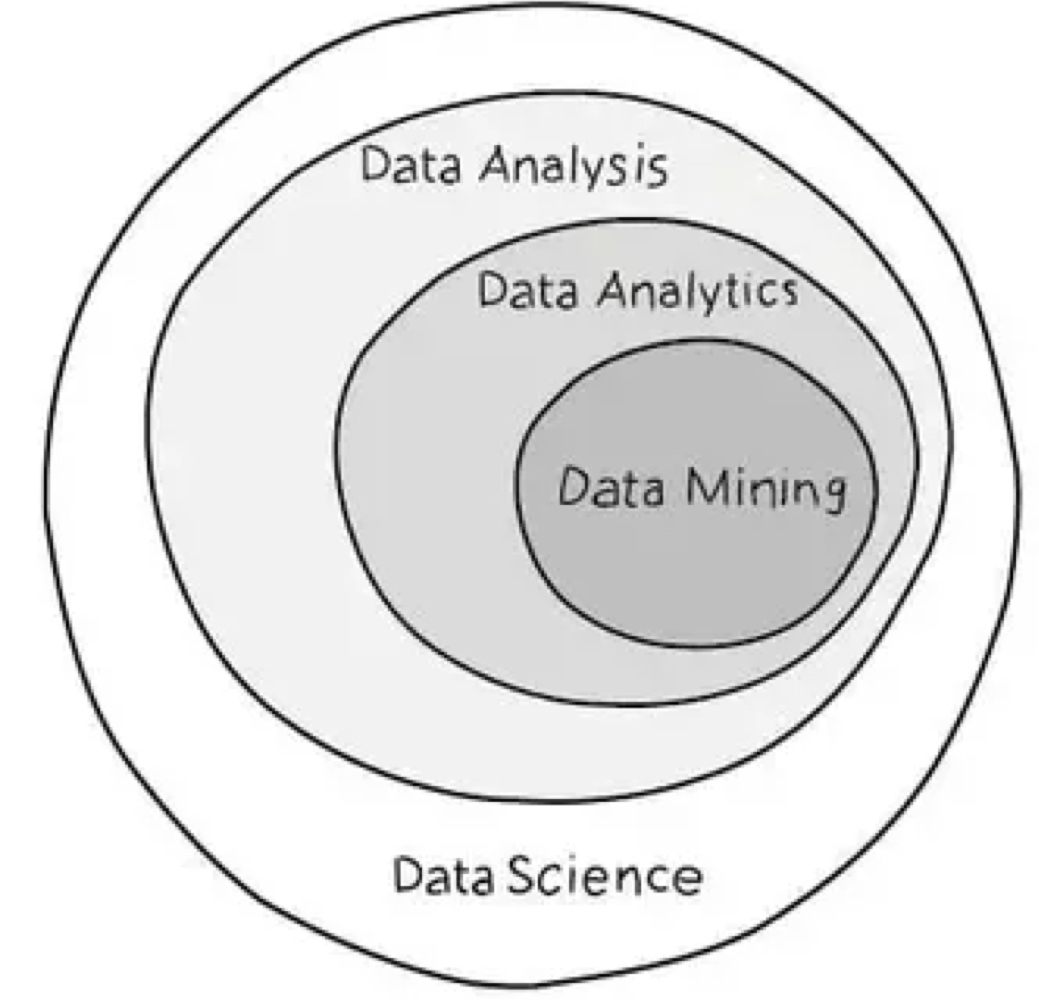
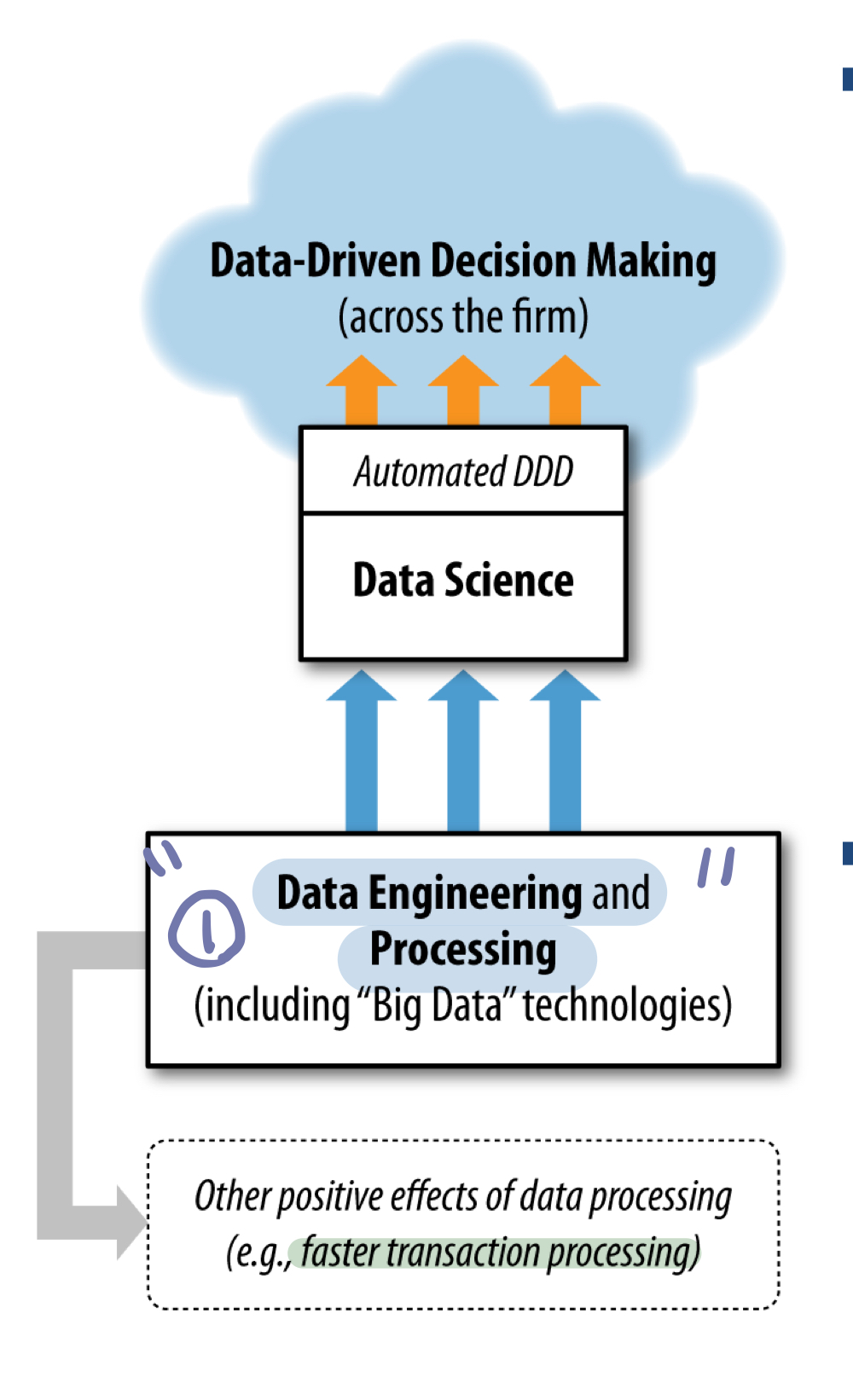
수업 출처) 숙명여자대학교 소프트웨어학부 수업 "데이터사이언스개론", 박동철 교수님
1. Data Science Process
데이터 사이언스의 기본 원리는 데이터 마이닝이다. 데이터 마이닝은 상당히 잘 이해된 단계를 가진 process이다.
데이터 사이언티스트는 실생활의 문제를 하위 작업으로 분리한다.
하위 작업들의 솔루션들이 모여서 전체적인 문제를 해결할 수 있다.
문제의 기저가 되는 공통적인 데이터 마이닝 작업이 존재한다.
(ex) classification, regression, clustering, association rule discovery
좋은 데이터 과학자가 되기 위해서는 다양한 공통적인 데이터 마이닝 작업을 해결하는 방법을 알아야 하고, 문제를 이렇게 공통적인 작업들로 나눌 수 있어야 한다.
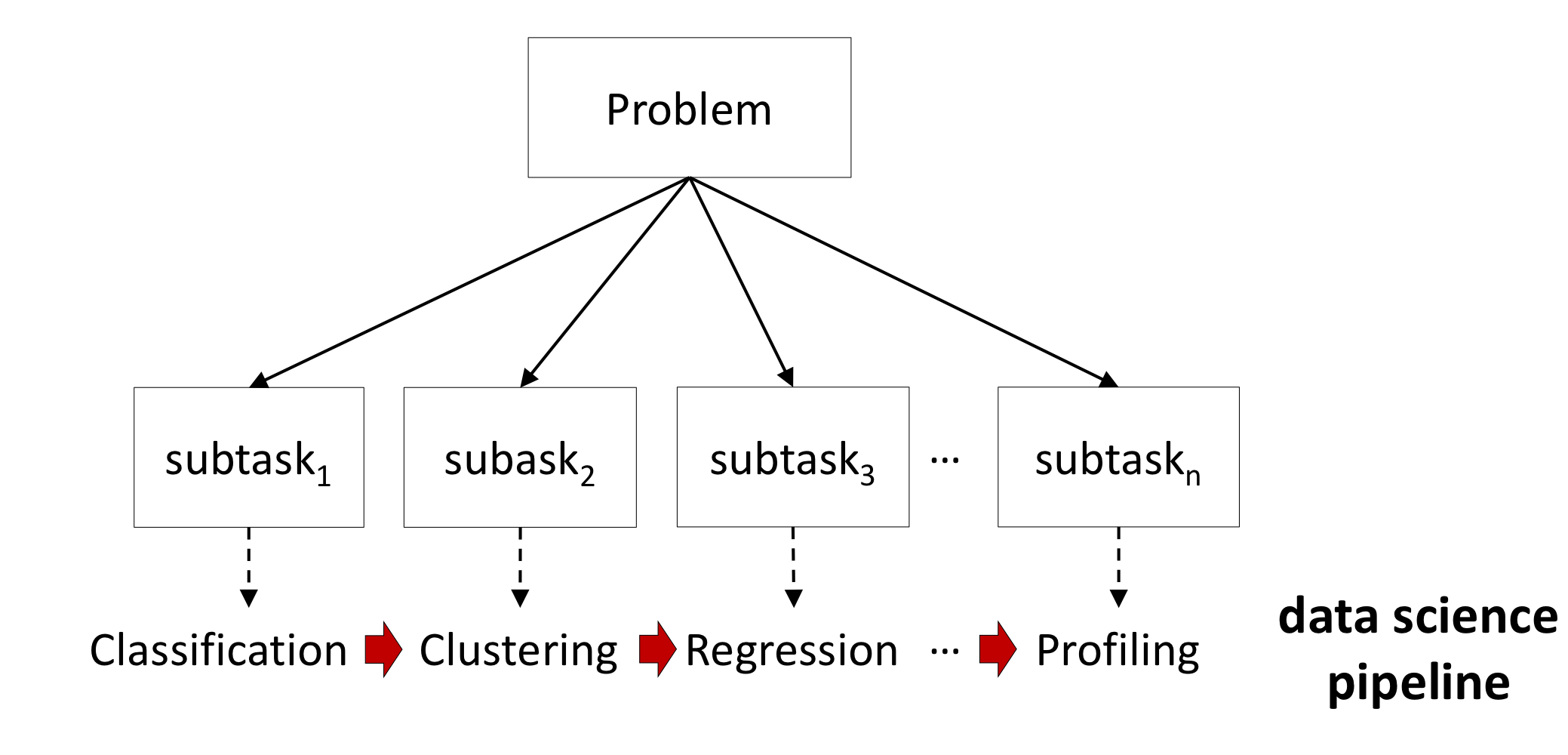
각각의 하위 작업들은 그에 맞는 데이터 마이닝 기법으로 병렬처리 된다. 작업을 나눌 때 마이닝 방법을 생각해놓는 것이 좋다.
2. Common Data Mining Tasks
- classification : 분류
- regression (a.k.a. value estimation) : 회귀 (value 추정)
- similarity matching : 유사도 매칭
- clustering : 군집화
- co-occurrence grouping (a.k.a. association rule discovery) : 동시발생 (관계 규칙 발견)
- profiling (a.k.a. behavior description) : 프로파일링 (행동 묘사)
- link prediction : 연관성 예측 (ex. recommendation)
- data reduction : 데이터 사이즈 줄이기 (불필요한 데이터 제거, 형태 변환 등)
- causal modeling : 인과관계 모델링
2-1. Classification 분류
모집단의 각 개체가 어떠한 클래스의 집합에 속할지 예측하는 방법이다.
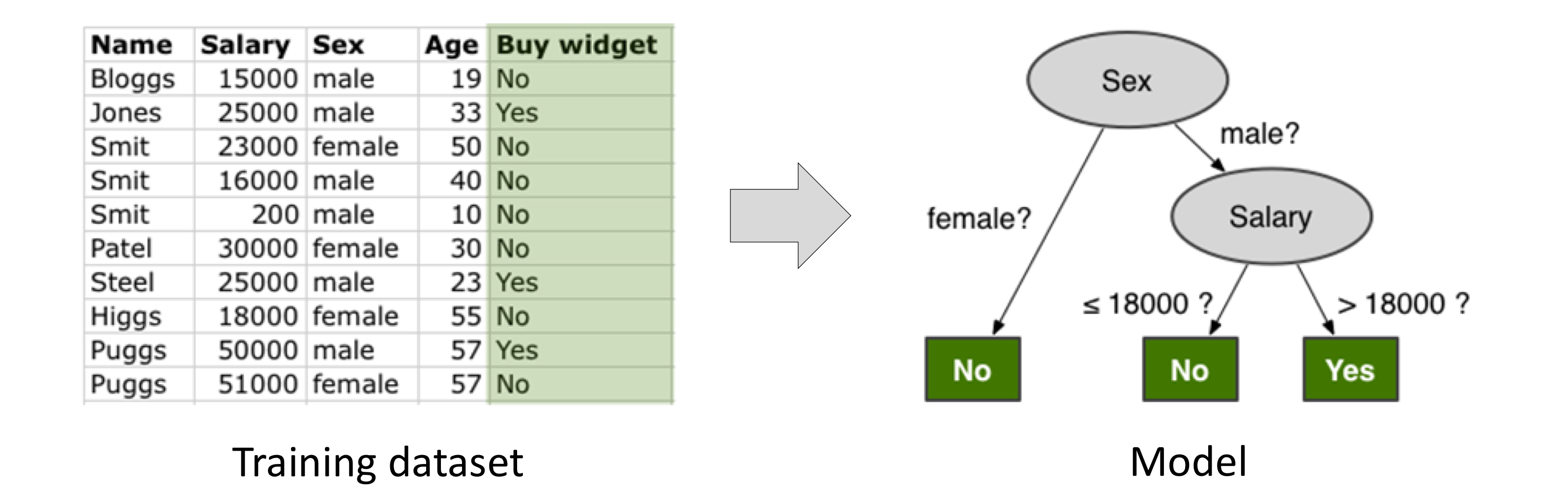
주로 상호배타적인 클래스로 분류할 때 사용한다.
분류에서 끝나는 것이 아니고, 분류를 학습하여 "예측" 하는 데 활용한다. → 지도학습에 활용
각각의 개체를 instance라고 하고, 속성을 attribute라고 한다.
예측의 대상이 되는 속성(클래스)를 classificaiton target 이라고 한다.
그리고 그 타겟들은 이미 상호배타적으로 설정되어 있다.
예를 들면, 연봉, 성별, 나이 등의 데이터로 이 사람이 어떠한 물건을 살지 안살지 예측하는 것이다.
이때 타겟은 "물건을 산다" 라는 속성이고, 클래스는 Yes 또는 No 이다.
일반적인 과정 : 훈련 데이터셋 → 데이터의 클래스를 묘사하는 모델 설정 (모델링) → 새로운 인스턴스가 주어질 때, 해당 모델을 적용하여 추측된 클래스 생성
비슷한 작업으로 scoring이나 class probability estimation 이 있다.
이는 각 개체가 각 클래스에 속할 확률을 도출하는 것이다.
예를 들어, 위의 예시에서 (Lee, 42000, male, 44) → (YES : 80%, NO : 20%) 이렇게 각 개체에 대해 클래스를 가질 확률을 계산한다.
2-2. Regression 회귀
각 개체가 특정 변수에 대해 어떠한 숫자 값을 가질 것을 예측하는 모델이다.
value estimation 이라고도 불린다.

예를 들어, 특정한 키의 사람은 어떤 값의 몸무게를 가질지 예측하는 것이다.
일반적인 과정 : 훈련 데이터셋이 주어질 때, 각 개인에 대해 특정 변수 값을 묘사하는 모델 설정 → 새로운 개체에 모델을 적용하여 측정된 값 생성
classification과의 차이점
- classification은 인스턴스의 "클래스"를 예측하는 것이다. (ex. YES / NO)
- regression은 인스턴스와 관련된 "숫자 값"을 예측하는 것이다. (ex. 178)
2-3. Similarity Matching 유사도 매칭
알고있는 데이터를 기반으로 유사한 데이터를 찾는 모델이다.

일반적인 과정 : 두 개체 사이의 거리 측정 → 한 개체에 대해서 가장 작은 거리를 갖는 개체 탐색
데이터의 종류가 다양하기 때문에 거리 측정에서는 유클리드 거리, 코사인 거리 등 다양한 종류의 거리를 사용한다.
(유클리드 거리) 예를 들어서, User 3 = (5, 4, 7, 4, 7), User 4 = (7, 1, 7, 3, 8) → distance ≅ 3.87
2-4. Clustering 군집화
비슷한 개체를 하나의 군집으로 묶는 모델이다.
유사도를 측정하기 위해 "거리"를 사용한다.
산점도에서 자연스럽게 형성되는 그룹을 분석할 때 유용하다. → 비지도학습에 활용

예를 들면, 주로 어떤 종류의 고객을 보유하고 있는지 파악할 때 사용된다.
2-5. Co-occurrence grouping 동시발생
개체들 사이의 동시 발생을 통해 관계를 찾는 모델이다.
예를 들어서, 마트 판매 상품을 분석해보니 기저귀를 살 때 맥주도 같이 사는 손님의 비율이 높았다.
이와 같이 분석을 통해 특별 프로모션, 상품 진열, 세트 판매, 추천 등 마케팅에 활용할 수 있다.
2-6. Profiling 행동 특성 묘사
개인이나 집단의 전형적인 행동을 특징짓는 모델이다.
normal한 행동특성에서 벗어난 행동을 탐지할 때 매우 유용하다.
프로필은 normal한 행동을 묘사하기 때문에, 갑자기 그것에 벗어난 행동을 할 때 알림을 주는 것이다.
한 예시로는 사기 탐지에 사용된다.
2-7. Link Prediction 연관성 예측
데이터 아이템들 사이의 연관성을 예측하는 모델이다.
일반적으로 연결고리가 존재한다고 제안하고, 그 강도를 추정함으로써 사용된다.
"추천" 알고리즘에 매우 유용하다. SNS에서 친구를 추천해주거나, 넷플릭스 등에서 영화를 추천할 때 주로 사용된다.
2-8. Data Reduction 데이터 사이즈 감소
큰 데이터셋을 중요한 정보를 많이 포함하는 작은 데이터셋으로 사이즈를 줄이는 것이다.
작은 데이터셋은 다루기 쉽고, 정보나 향상된 인사이트를 보다 더 잘 드러낸다.
하지만, 정보의 손실 또한 일어나기 쉽다는 단점이 있다.
2-9. Causal Modeling 인과관계 모델링
다른 사건에 실질적으로 영향을 주는 사건을 찾는 모델이다.
예를 들어 담배피는 사람들 중에 이가 누런 사람과 폐암에 걸린 사람들이 있다고 할 때,
이 누래짐과 폐암이 담배때문에 발생한건지, 아니면 그냥 그런 사람들이 담배를 피는건지 인과관계를 파악하는 것이다.
3. Supervised 지도학습 vs. Unsupervised 비지도학습 Methods
3-1. Supervised
- 지도학습은 training data를 통해 이미 정답을 알고 학습을 시키는 것이다.
- 명시되어 있는 특정한 타겟이 존재한다.
- (ex) classification

Supervised data mining
- 알고싶은 특정한 타겟이 존재한다 → 답이 존재한다.
- training dataset이 반드시 존재한다 → 각각의 target value가 존재하는
- target value는 label 이라고도 부른다.
- (ex) classification, regression, causal modeling
3-2. Unsupervised
- 비지도학습은 정답을 모르고 학습을 시키는 것이다.
- 정의해야 할 명시되어 있는 특정한 타겟이 없다.
- (ex) clustering
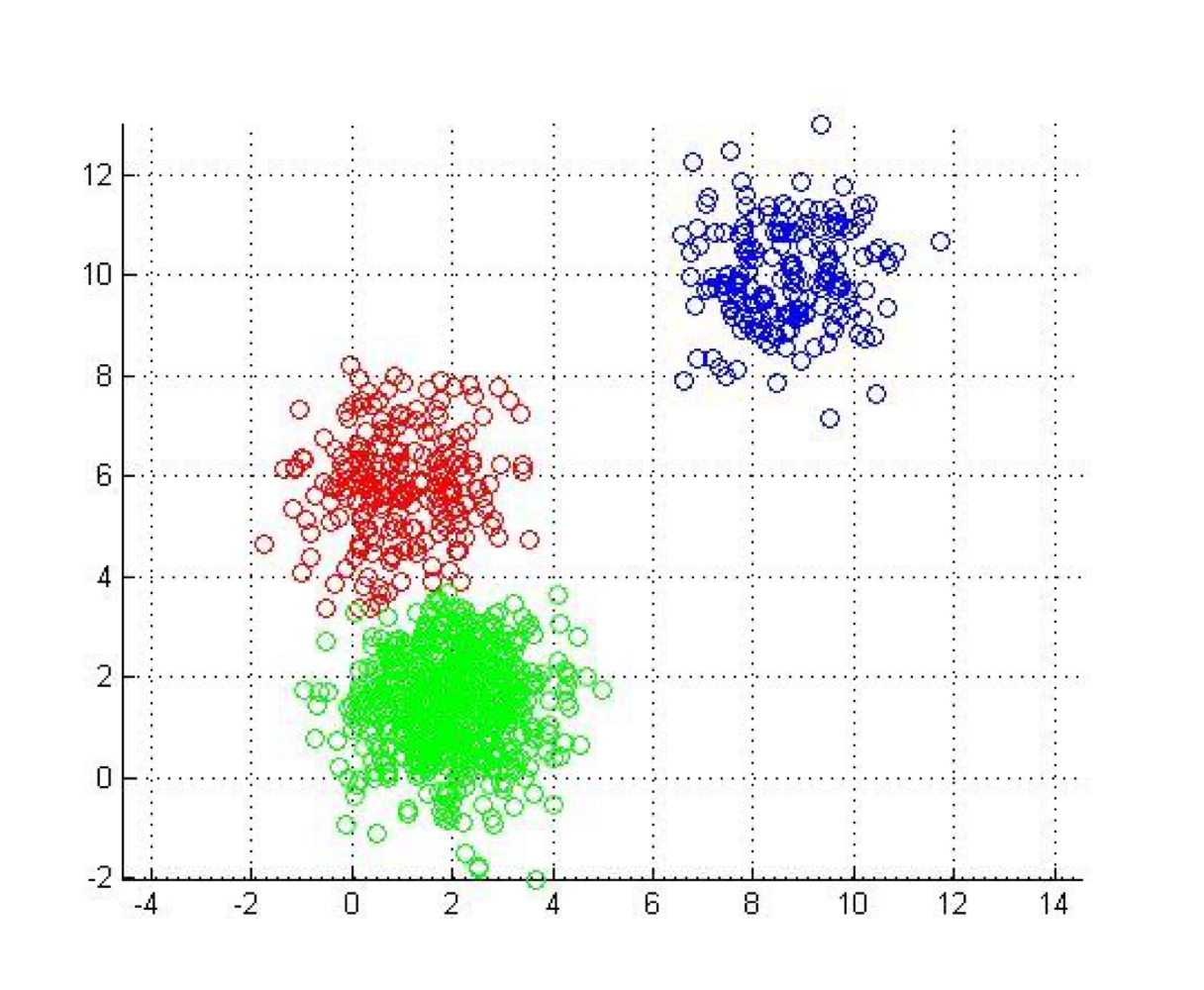
Unsupervised data mining
- 특정한 타겟이 아닌, 어떠한 패턴을 찾는 것이 목적이다.
- training dataset이 필요하지 않다.
- (ex) clustering, co-occurrence grouping, profiling
4. Classification vs. Regression
둘 다 supervised data mining task이다.
4-1. Classification
- 타겟이 카테고리 값이다. (ex. YES / NO, HIGH / MID / LOW)
- (ex) 이 고객이 인센티브를 받으면 이 상품을 구매할까? → YES / NO
고객이 인센티브를 받으면 (S1, S2, S3) 중에서 어떤걸 구매할 가능성이 높을까? → S1 / S2 / S3
4-2. Regression
- 타겟이 숫자 값이다. (ex. 2.5, 68)
- (ex) 이 고객이 이 서비스에 얼마를 쓸까? → $2,500
5. Data Mining and its Results
데이터 마이닝에는 두가지 단계가 있다.
5-1. Mining phase
: Historical Data (Training Data) → Data mining → Model
- training data를 통해 패턴 찾기 or 모델링
- training data는 모든 값이 명시되어 있어야 한다.
5-2. Use phase
: New data item → Model → Result
- 새로운 데이터에 패턴이나 모델 적용 → 예측
- 새로운 데이터는 알려지지 않은 class value가 존재한다.
6. Data Mining Process
: CRISP - DM (Cross Industry Standard Process for Data Mining)
산업을 통틀어서 데이터 마이닝을 위한 표준화된 Process이다.
: Business Understanding → Data Understanding → Data Preparation → Modeling → Evaluation → Deployment
기본적인 틀은 저 순서이고, 계속적인 평가를 통해 이전 과정으로 돌아가기도 하고 수정을 거듭하면서 점차 성능이 향상된다.
6-1. Business Understanding
- 해결해야 할 비즈니스 문제를 이해한다.
-대부분 모호하거나 폭넓거나 이해하기 어려운 문제이다.
- 해결해야 할 비즈니스 문제를 하나 이상의 데이터 사이언스 문제로 간주한다.
- 데이터 과학자들에 의해 공식화된 창의적인 문제가 성공의 열쇠가 된다.
- 문제를 여러 개의 하위 작업으로 나누고, 각각의 데이터 사이언스 문제를 해결할 방법을 디자인한다.
- classification, regression, clustering 등
- 각 문제에 맞는 효과적인 툴을 사용할 수 있다.
- 문제를 재구성하고 해결책을 설계하는 것은 반복적인 발견의 과정이다.
6-2. Data Understanding
- Data
- 세운 해결책들에 이용가능한 원상태의 데이터셋이 존재한다.
- (ex) a customer database, a transaction database, a marketing response database
- 각 데이터의 강점과 한계점을 이해한다.
- 문제와 완벽하게 알맞는 데이터는 거의 존재하지 않는다.
- 각 데이터로 할 수 있는 것과 없는 것을 찾고, 해당 데이터로 문제를 해결할 수 있을지 생각한다.
- (ex) classification 을 하기 위해서는 라벨이 존재하는 데이터가 필요하다.
- 데이터에 더 투자가 필요한지 결정한다.
- 몇몇 데이터는 무료이지만, 몇몇 데이터는 얻기 위해 노력이 필요하거나 돈을 지불해야 한다.
6-3. Data Preparation
- 데이터를 정리해서 보다 유용한 형태로 변환한다.
- 몇몇 데이터 분석 툴들은 특정한 형태의 데이터만 요구하기 때문이다.
- 일반적인 예시들
- converting data to tabular format : 테이블 형식의 데이터로 변환
- removing or inferring missing values : 결측치 제거하거나 유추
- converting data to different types : (ex) 'male', 'female' → 0, 1 타입 변경
- normalizing or scaling numerical values : (ex) [-100, 100] → [0, 1] 범위 조절
- cleaning data : (ex) Age : 999 → ? 데이터 정리
- 데이터 마이닝 결과의 질은 이 단계에 달려있다.
- (ex) 결측치, 비정상 값, 정규화되지 않은 값
6-4. Modeling
- 가장 주요한 단계이다.
- output
- 데이터의 규칙을 나타내는 모델이나 패턴의 일종을 생성한다.
- 데이터 마이닝의 근본적인 아이디어를 이해하는 것이 매우 중요하다.
- 존재하는 데이터 마이닝 기술과 알고리즘을 이해하자.
6-5. Evaluation
- 데이터 마이닝 결과를 엄격하게 평가한다.
- 다음 단계로 넘어가기 전에 그 결과가 유효하고 신뢰할 수 있다는 확신을 얻어야 한다.
- Examples
- 모델의 예측 정확도 추정 (ex. 90%?)
- training data를 넘어서는 모델의 보편성 확인 (overfitting 되지 않았는지)
- 허위 경보의 비율 추정
- 결과를 즉각적으로 적용하는 대신, 일반적으로 통제된 상황에서 모델을 먼저 테스트하는 것이 바람직하다.
- 그것이 더 쉽고 저렴하고 빠르고 안전하다.
- 데이터 사이언티스트는 그 모델과 평과 결과를 다른 데이터 사이언티스트들 외에 이해관계자들에게 쉽게 설명해야 한다.
- 매니저, 고위 관계자, 프로그래머 등

6-6. Deployment
- 실제 상황에 데이터 마이닝 결과 (시스템)을 적용한다.
- 일반적인 시나리오
- 새로운 예측 모델이 구현된다.
- 그 모델은 기존의 정보 시스템과 통합된다.
- 많은 경우
- Data Science Team : 프로토타입을 제작하고 평가한다.
- Data Engineering Team : 모델을 생산 시스템에 적용한다.
- 적용 이후, 과정은 첫번째 단계로 되돌아간다.
- 이 과정을 통해 얻은 통찰력과 경험을 통해 더욱 개선된 해결책을 제시할 수 있다.
7. Other Analytics Techniques & Technologies
- 데이터 마이닝 외에도 데이터 분석을 위한 다양한 기술들이 있다.
- 통계학, 데이터베이스 시스템, 머신러닝 등
- 이러한 기술들을 익혀두는 것이 중요하다.
- 그것들의 목표가 무엇인지, 어떠한 역할을 하는지, 그것들의 차별점이 무엇인지
- 데이터 과학자에게 중요한 기술은 어떤 종류의 분석 기술이 특정한 문제를 해결하는데 적합한지 인지할 수 있는 것이다.
7-1. Statistics 통계학
- 분석의 바탕이 되는 많은 지식들을 제공한다.
- Examples
- Data Summary (means, median, variance 등)
- Understanding different data distributions
- Testing hypotheses : 가설 테스트
- Quantifying uncertainty : 불확실성 증명
- Measuring correlation : 연관관계 측정
- 많은 기술들이 데이터에서 도출하는 모델이나 패턴들은 통계학에 근본을 두고 있다.
7-2. Database Querying
- Database system
- 데이터 삽입, 질의 (쿼리), 업데이트 및 관리 할 수 있는 소프트웨어 응용 프로그램
- Database query
- 데이터나 데이터의 통계에 대한 특정한 요청
- 데이터를 통해서 얻고자 하는 질문
- (ex) 지정된 데이터 검색, 정렬, 요약 통계량 계산
- 기술적 언어로 공식화되고 데이터베이스 시스템에 질문을 제기함
- (ex) SQL (Structured Query Language)
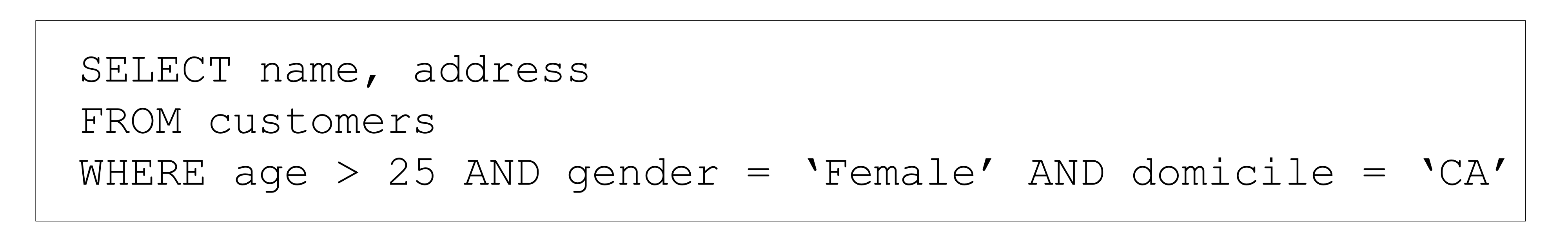
- Data science vs. databases technologies
- 데이터 사이언스에서 데이터베이스 시스템에 저장된 관심있는 데이터를 찾거나 조사하기 위해 데이터베이스 기술을 사용할 수 있다.
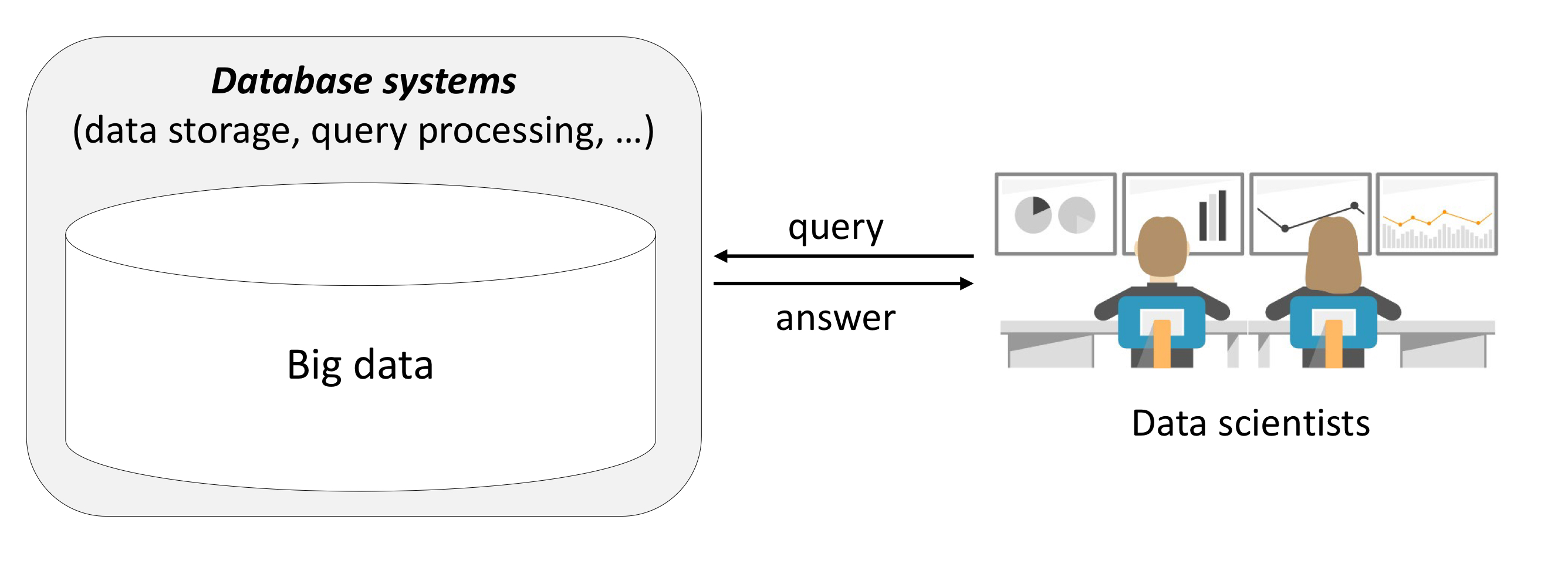
7-3. Machine Learning
- 컴퓨터 시스템이 명시적인 프로그래밍 없이, 데이터를 가지고 학습할 수 있는 능력을 제공하는 것이다.
- 인공지능의 한 분야이다.
- 모델을 개발하고 모델 성능을 향상시키는 데에 데이터를 활용한다.
- (ex) decision tree, artificial neural networks (deep learning), support vector machines, clustering, bayesian networks,...
- 하지만,이들 사이의 경계가 모호해졌다.

- 데이터 마이닝과 머신러닝은 긴밀히 연결되어있다.
- 데이터 마이닝의 한 분야가 머신러닝으로 파생되기 시작하였다.
- 데이터 마이닝은 머신러닝의 한 가지이다.
- KDD (Knowledge Discovery and Data mining)
- 둘 사이에 기술과 알고리즘은 공유된다.
- 데이터로부터 유용하고 유익한 패턴을 찾아낸다.
- 그럼에도 불구하고 머신러닝은 성능향상, 인지능력 향상에 더욱 집중되어 있다.
- (ex) robotics and computer vision
- (ex) agent가 이 환경에서 학습된 지식을 어떻게 활용하는가
- 데이터 마이닝은 데이터로부터 패턴, 규칙을 찾는 것에 더욱 집중되어 있다.
- 상업적 응용 프로그램 및 비즈니스 문제에 특히 활용된다.
8. Examples of Applying These Techniques
- "어떤 고객이 가장 수익성이 있는가?" : Database systems (profiable can be calculated from existing data., not predict)
- "수익성이 있는 고객과 평균의 고객들 간에 정말 차이가 있는가?" : Statistics (hypothesis testing)
- "하지만 이 고객들은 정말 누구인가? 특징화 할 수 있는가?" : Data mining (profiling)
- "어떤 특정한 새로운 고객이 수익성이 있을까? 얼마나?" : Data mining (classification, regression)
'Software > Data Science Introduction' 카테고리의 다른 글
| [데이터사이언스개론] Similarity, Neighbors, Clusters (0) | 2021.06.04 |
|---|---|
| [데이터사이언스개론] Overfitting and Avoidance (0) | 2021.04.22 |
| [데이터사이언스개론] Fitting Model to data (0) | 2021.04.22 |
| [데이터사이언스개론] Predictive Modeling (0) | 2021.04.21 |
| [데이터사이언스개론] Data Science (0) | 2021.04.15 |