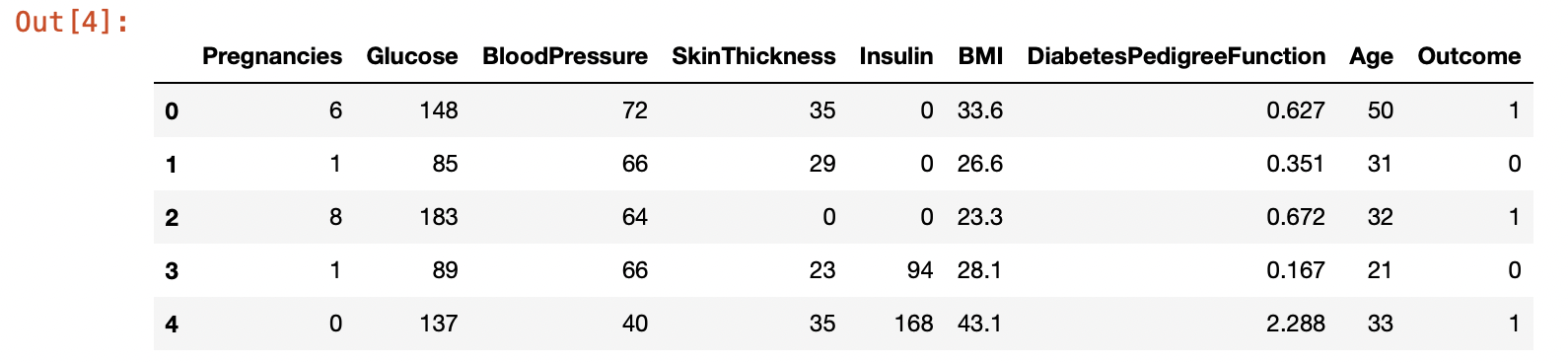
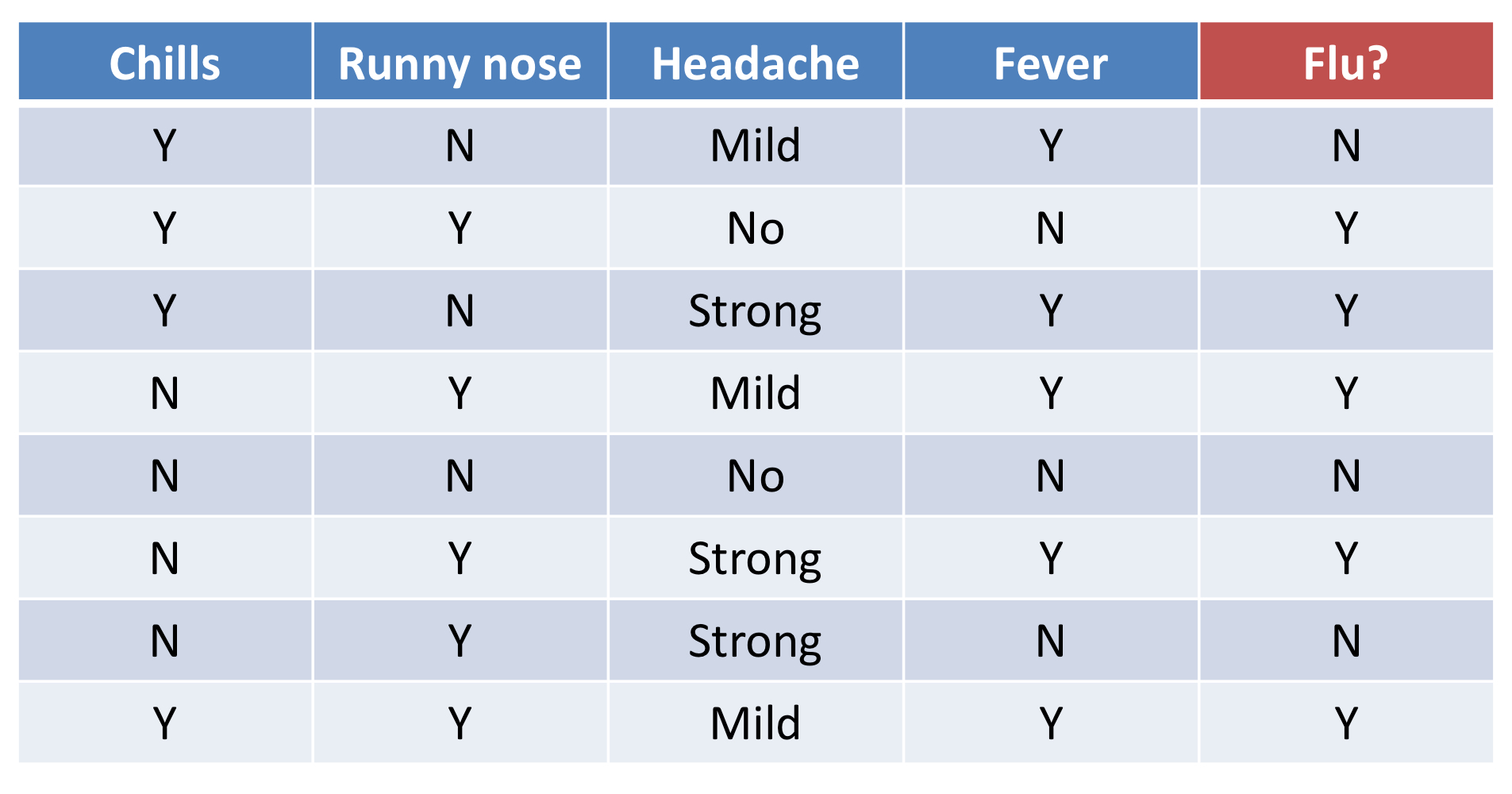
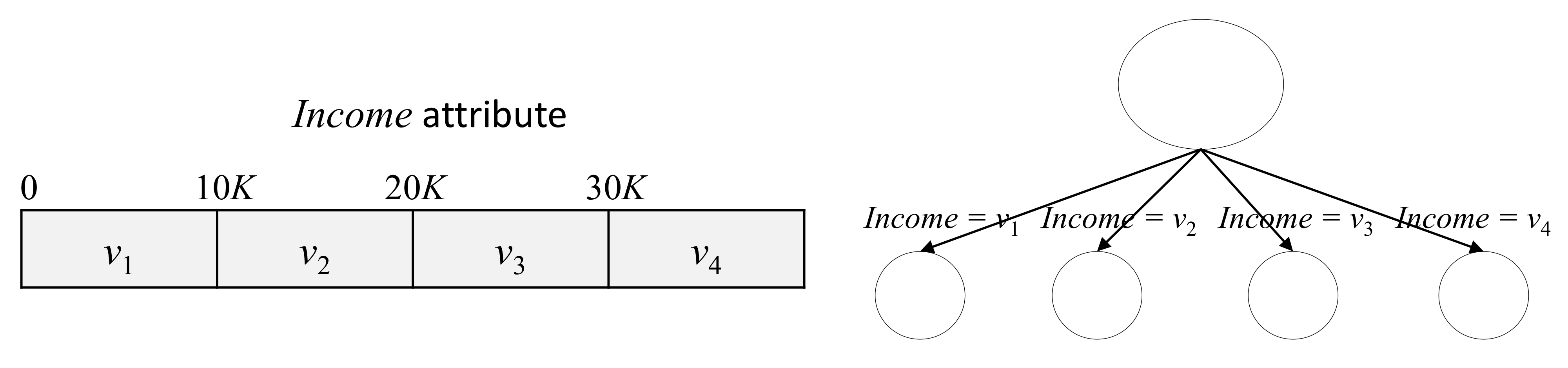
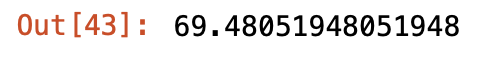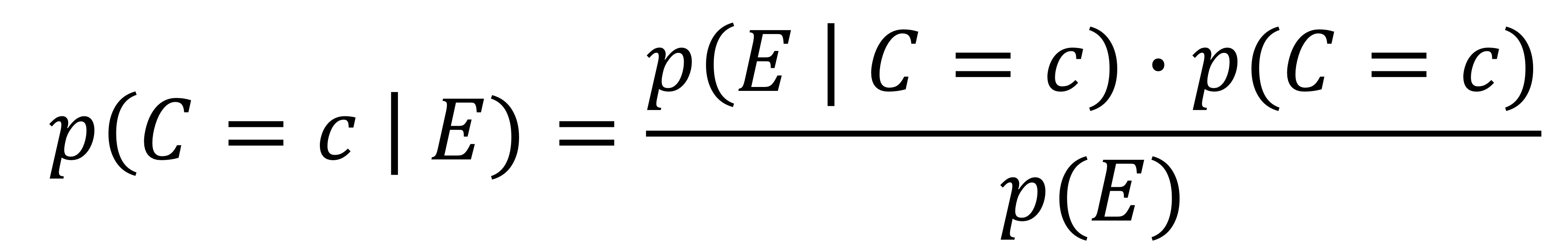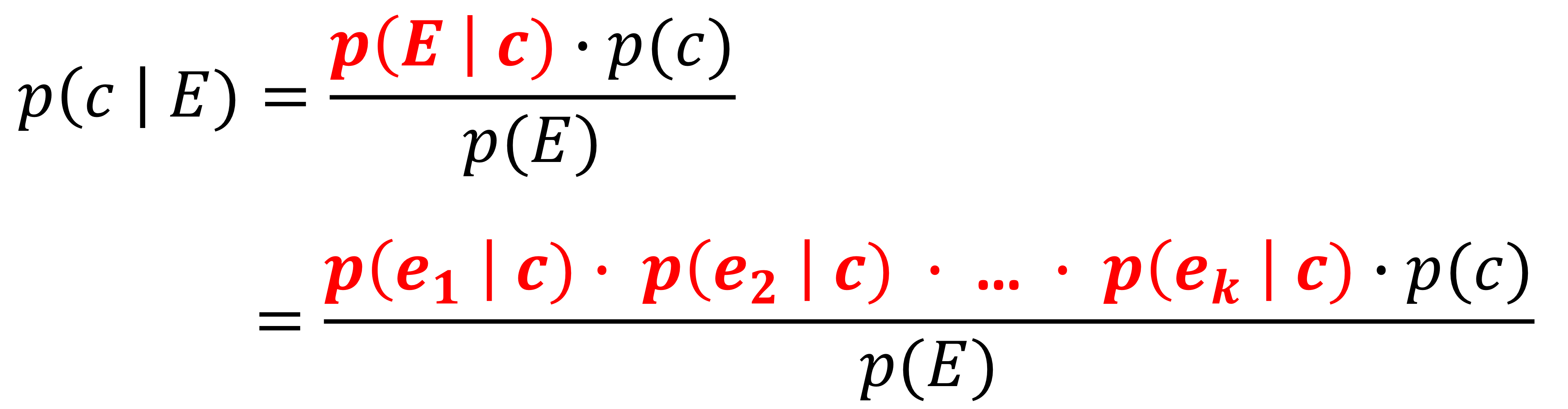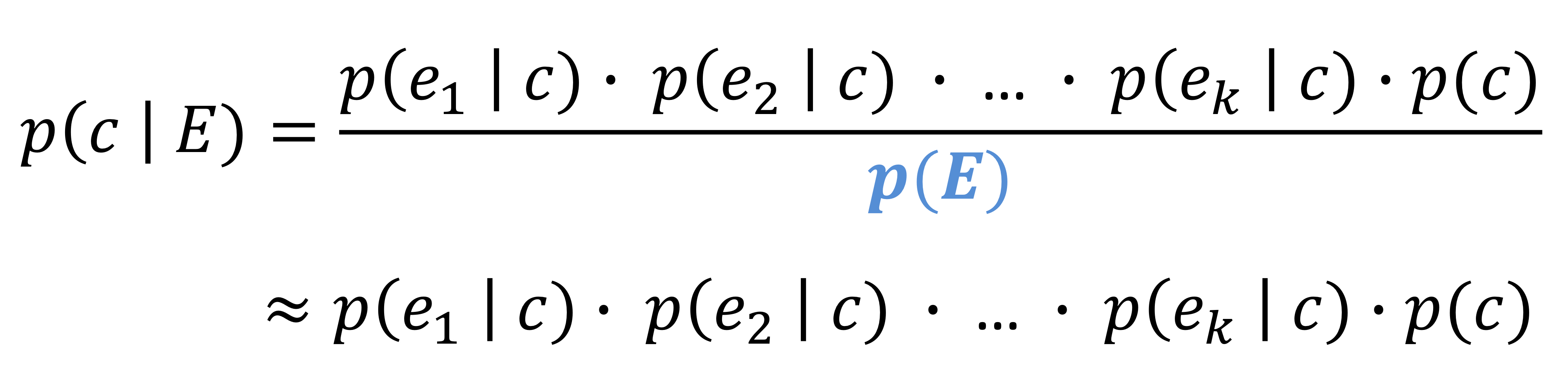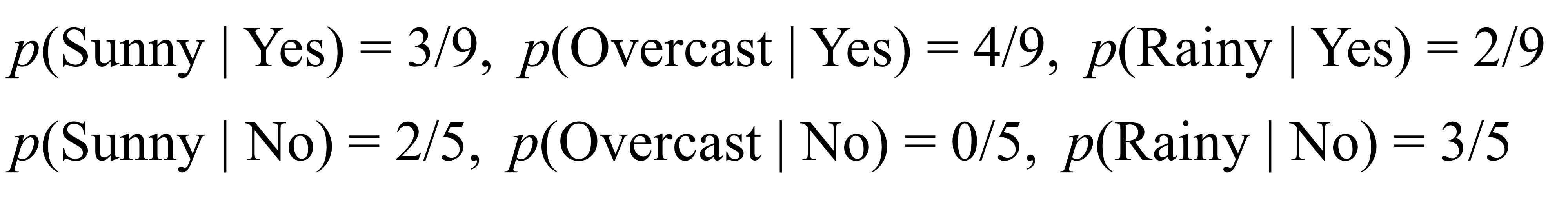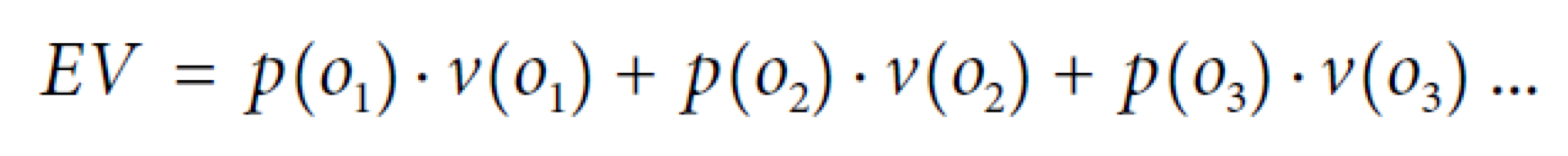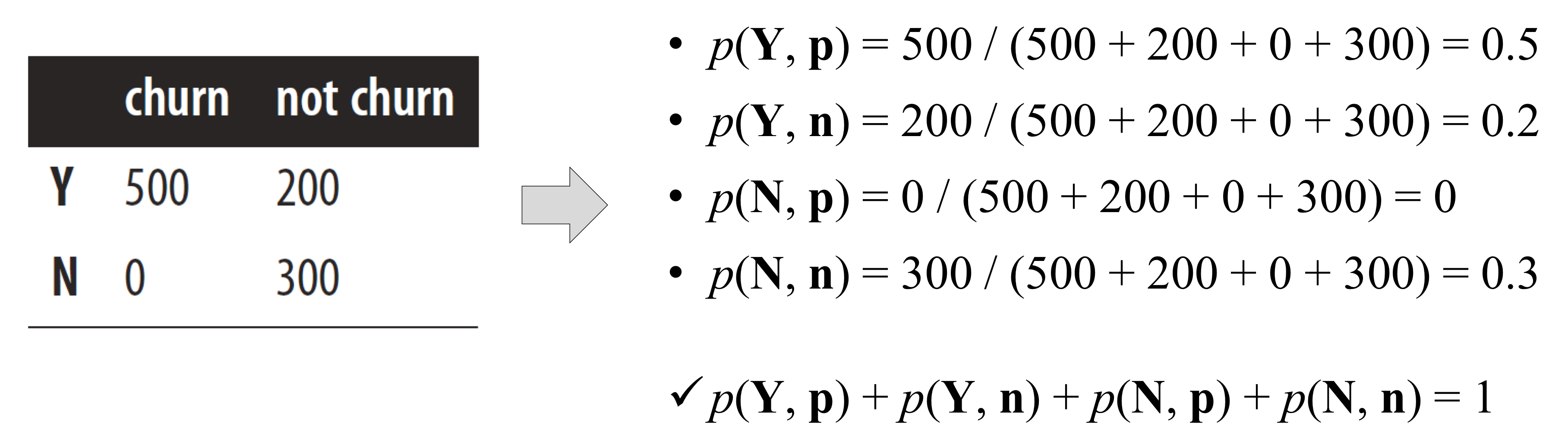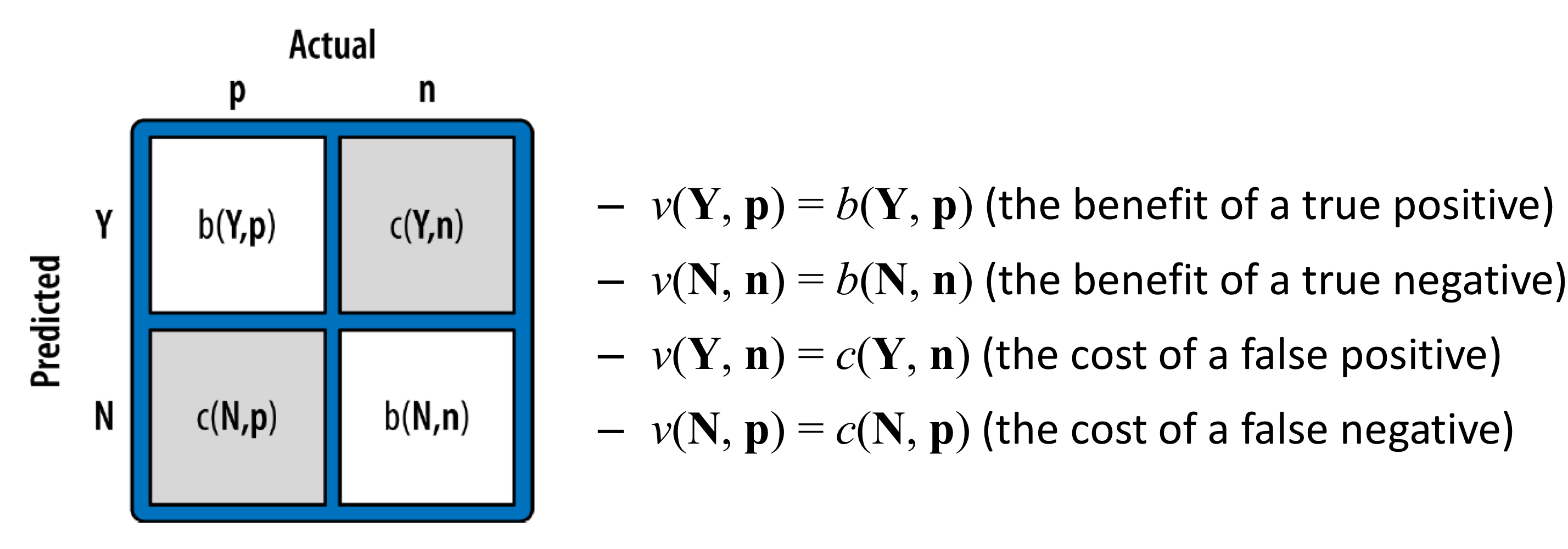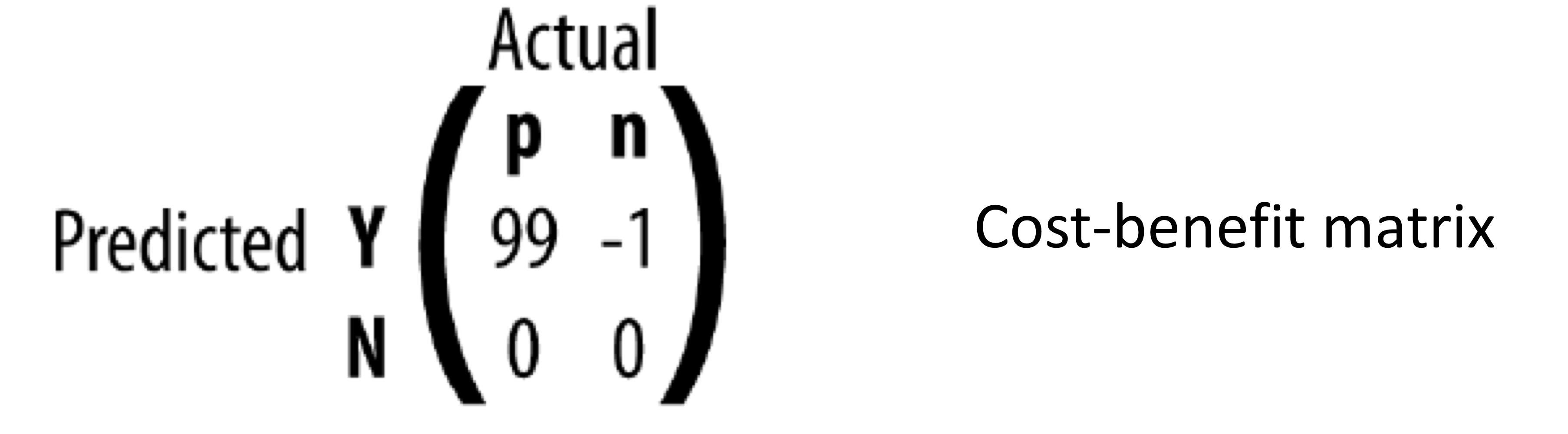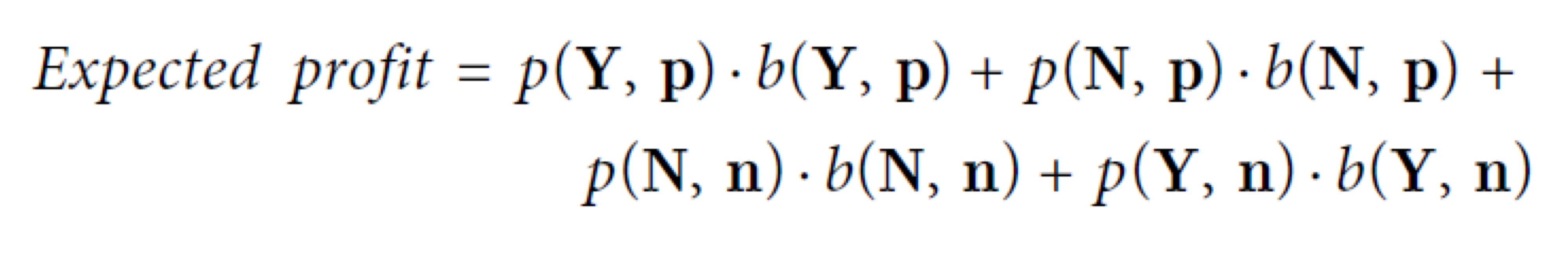* pregnancies : 임신횟수 * glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도 * bloodPressure : 이완기 혈압 (mm Hg) * skinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값 * insulin : 2시간 혈청 인슐린 (mu U / ml) * BMI : 체질량 지수 (체중kg / 키 (m)^2) * diabetesPedigreeFunction : 당뇨병 혈통 기능 * age : 나이 * outcome : 당뇨병인지 아닌지, 768개 중에 268개의 결과 클래스 변수 (0 / 1)는 1이고 나머지는 0이다.
2. 라이브러리 import
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
3. 데이터셋 로드
df = pd.read_csv("diabetes.csv") #주피터노트북에서 실행 -> 경로 간단
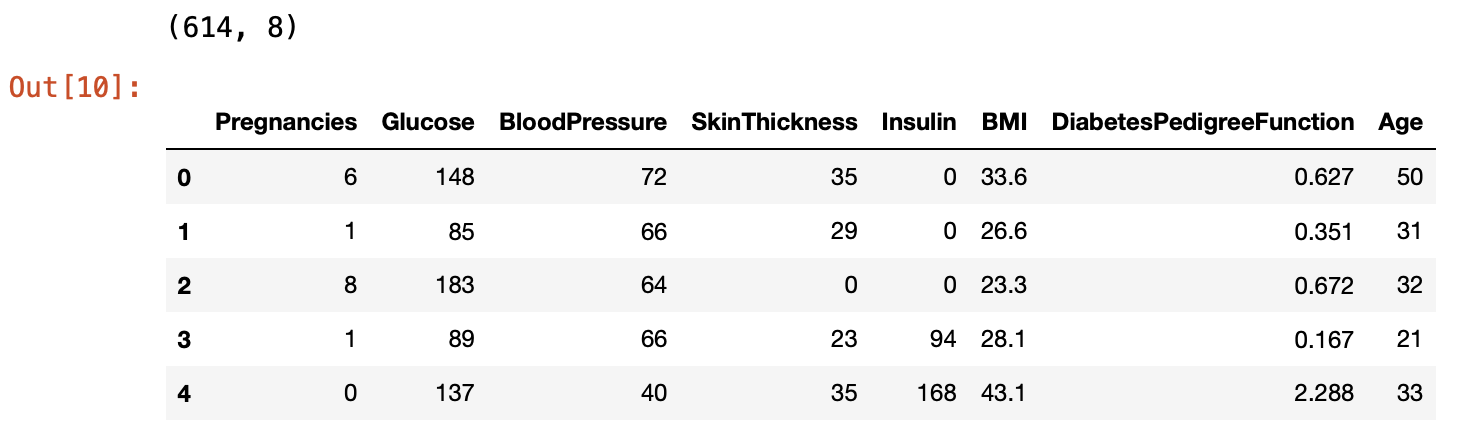
df.shape
9개의 feature가 존재하고, 768개의 데이터가 있다.
df.head()
결측치가 없고 다 숫자로 되어있기 때문에 이 데이터셋은 전처리를 하지 않아도 괜찮다.
4. 학습, 예측 데이터셋 나누기
# 8:2 비율로 구하기 위해 전체 데이터 행에서 80% 위치에 해당되는 값을 구해서 split_count 변수에 담기
split_count = int(df.shape[0] * 0.8)
split_count
# train, test로 슬라이싱을 통해 데이터 나눔
train = df[:split_count].copy()
train.shape
test = df[split_count:].copy()
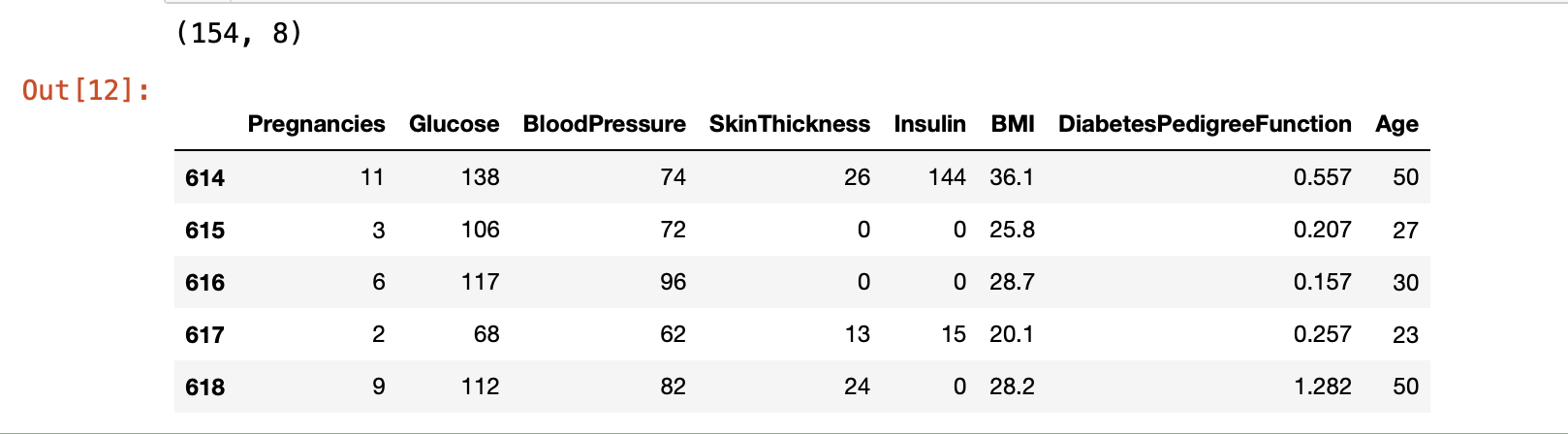
test.shape
데이터셋 자체로 학습을 하고, 예측 후 정확도까지 알아보기 위해서 위에서부터 80%는 학습데이터, 나머지 20%는 예측데이터로 분리했다.
80% 지점이 614번째 데이터이기 때문에
학습데이터는 614개,
예측데이터는 154개이다.
5. 학습, 예측에 사용할 컬럼
# feature_names 라는 변수에 학습과 예측에 사용할 컬럼명을 가져옴
# 여러개를 가져왔기 때문에 list 형태로 가져옴
feature_names = train.columns[:-1].tolist()
feature_names
# label_name 에 예측할 컬럼의 이름 담음
label_name = train.columns[-1]
label_name
feature는 이렇게 9개가 있는데, 우리가 예측할 것은 마지막 컬럼인 outcome (당뇨병인지 아닌지) 이기 때문에 뒤에서 두번째 컬럼인 Age까지를 feature_names에 저장하고, 마지막 outcome을 label_name에 저장했다.
6. 학습, 예측 데이터셋 만들기
# 학습 세트 만들기
# 행렬
X_train = train[feature_names]
print(X_train.shape)
X_train.head()
앞에서 나눈 80%의 학습데이터셋 train에 feature_names 컬럼을 적용하여 학습데이터셋 X_train 을 만들었다.
# 정답 값
# 벡터
y_train = train[label_name]
print(y_train.shape)
y_train.head()
마찬가지로 앞에서 나눈 80%의 학습데이터셋에 label_name 컬럼을 적용하여 학습할 때 정답을 맞추는 데이터셋 y_train을 만들었다.
# 예측에 사용할 데이터셋
X_test = test[feature_names]
print(X_test.shape)
X_test.head()
다음은 앞에서 나눈 20%의 예측데이터셋에 feature_names를 적용하여 학습한 알고리즘에 적용할 예측데이터셋 X_test를 만들었다.
# 예측의 정답값
# 실전에는 없지만, 실전 적용 전 정답을 알고있기 때문에 내가 만든 모델의 성능을 측정해봐야 함
y_test = test[label_name]
print(y_test.shape)
y_test.head()
마지막으로, 예측 모델의 성능을 측정하기 위한 예측 정답 데이터셋을 만들었다.
20% 예측 데이터셋에 label_name을 적용한 데이터셋으로, 실전 예측 문제에는 없지만 이 예제에서는 알고있는 값이기 때문에 모델의 성능을 측정할 때 사용할 것이다.
7. 머신러닝 알고리즘 가져오기
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model
decision tree classifier 알고리즘을 사용할 것이기 때문에 이 알고리즘을 model 변수에 저장해준다.
8. 학습 (훈련)
model.fit(X_train, y_train)
아주 간단하다.
머신러닝 알고리즘.fit(훈련데이터, 정답데이터) 형식이다.
9. 예측
y_predict = model.predict(X_test)
y_predict[:5]
학습이 기출문제와 정답으로 공부를 하는 과정이었다면, 예측은 실전 문제를 푸는 과정이라고 볼 수 있다.
위에서 5개 데이터의 예측 결과를 보자면 이와 같다. 1은 당뇨병, 0은 당뇨병이 아니라는 것이다.
# 피처의 중요도 시각화
sns.barplot(x = model.feature_importances_, y = feature_names)
seaborn을 활용해서 각 피처의 중요도를 시각화했다.
11. 정확도(Accuracy) 측정하기
# 실제값 - 예측값 -> 같은 값은 0으로 나옴
# 여기서 절대값을 씌운 값 = 1 인 값이 다르게 예측한 값임
diff_count = abs(y_test - y_predict).sum()
diff_count
# decision tree 예측할 때마다 다르게 예측할 수 있기 때문에 이 값은 다르게 나올 수 있음
# 항상 같게 하려면 model = DecisionTreeClassifier(random_state = 42)처럼 random_state 지정
우리는 예측 데이터셋의 정답도 알고있기 때문에 모델의 정확도를 측정할 수 있다.
outcome 값은 0 또는 1이기 때문에 실제값에서 예측값을 뺀 값의 절대값이 1인 값이 틀린 것이라고 볼 수 있다.
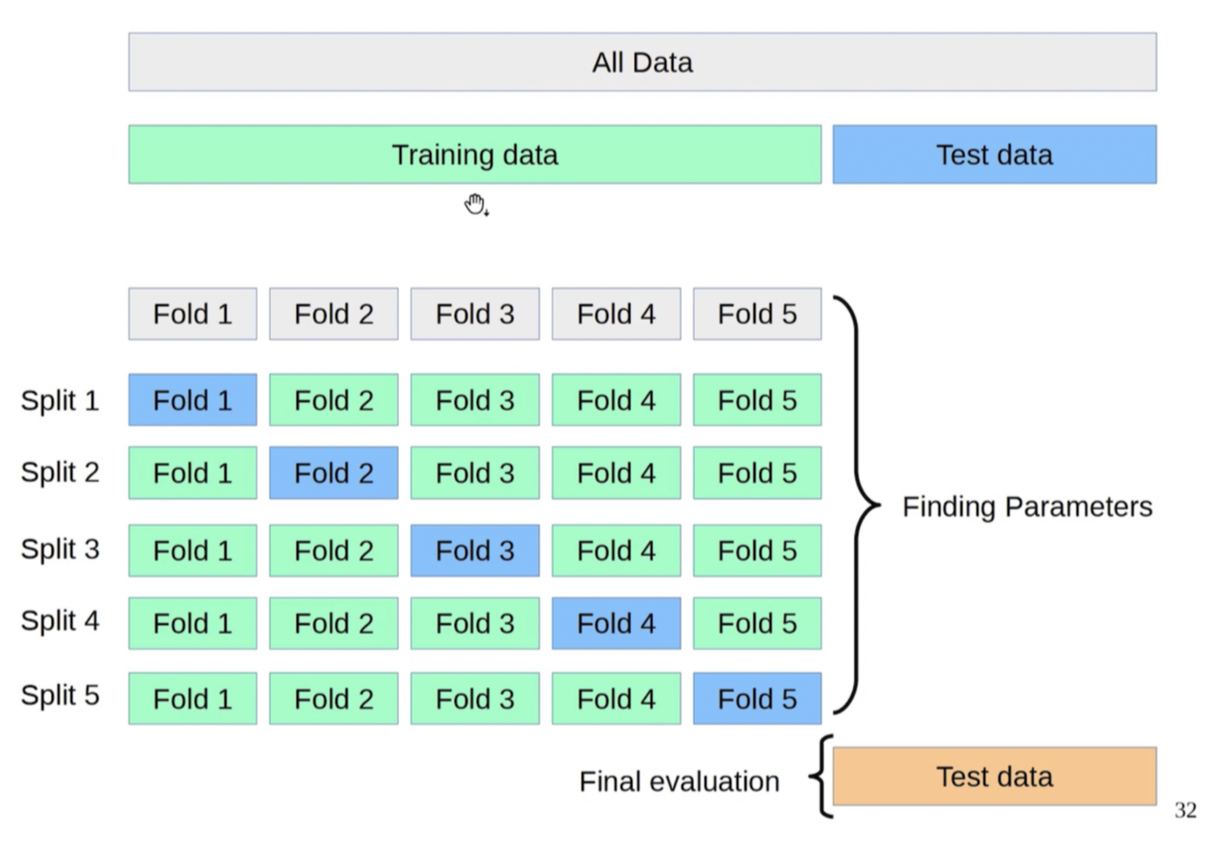
4. 예를 들어 5개의 폴더로 나누면 fold1부터 5까지 하나씩 test data로 놓고 나머지로 training 후 test data로 성능을 확인한다.
5. 각각의 fold에 있는 점수의 평균을 내서 가장 좋은 점수를 내는 모델과 파라미터를 찾는다.
clf = SVC(파라미터)
clf.fit(X_train, y_train)
3. grid searches
이러한 과정을 거쳐 알맞은 모델과 파라미터를 구한다.
4. 기본 예제
from sklearn imoprt tree
X = [[0, 0], [1, 1]]
y = [0, 1]
clf = tree.DecisionTreeClassifier()
clf.fit(X, y)
clf.predict([[2., 2.]])
clf.predict_proba([[2., 2.]])
결정 트리 분류 모델에 x = [0, 0] 일 때 y = 0이고, x = [1, 1] 일 때 y = 1인 훈련 데이터를 학습시켰다.
그리고 x = [2., 2.]일 때 y값을 예측했더니 1이 나왔다.
estimator.predict_proba 는 예측값을 비율로 출력하는 함수이다.
5. iris dataset 예제
from sklearn.datasets import load_iris
from sklearn import tree
import matplotlib.pyplot as plt
X, y = load_iris(return_X_y = True)
X, y # decisiontree 알고리즘이 숫자만 읽을 수 있기 때문에 카테고리 데이터 -> 숫자화
사이킷런 라이브러리에 내장되어 있는 아이리스 데이터셋을 불러왔다.
원래는 문자로 된 범주형 데이터지만, decision tree 알고리즘이 숫자만 읽을 수 있기 때문에 숫자로 변환한 것이다.
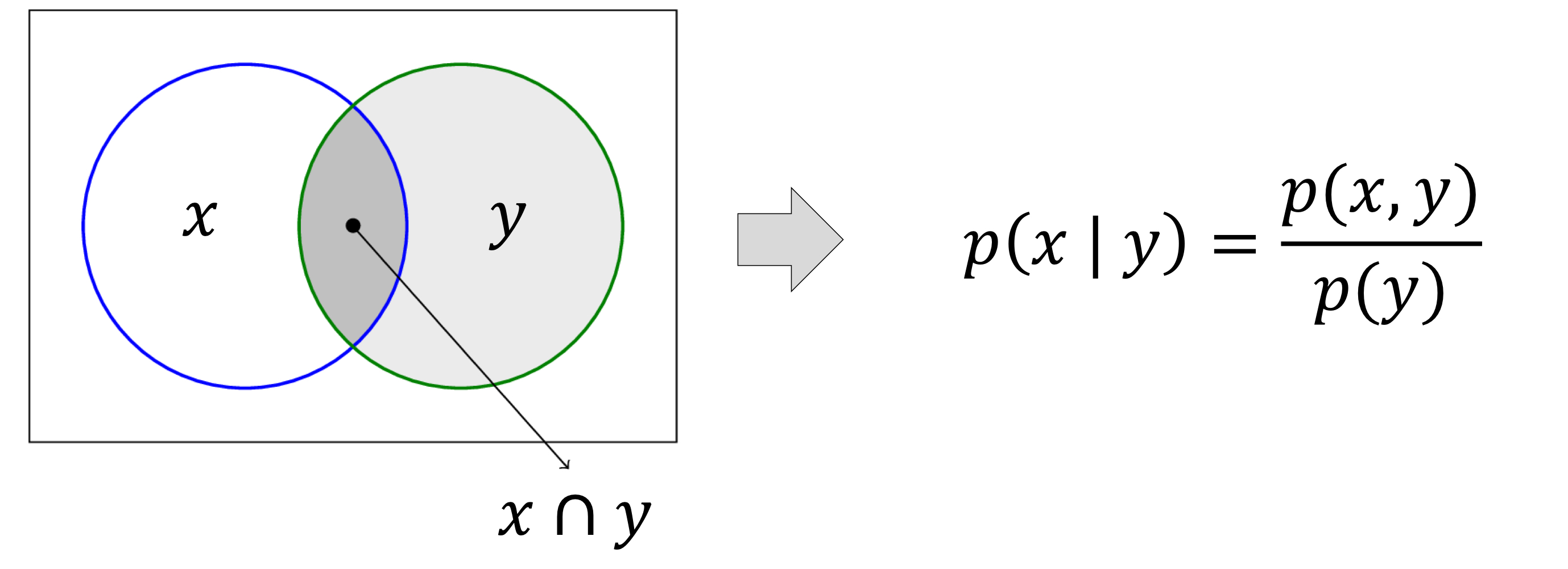
- 이전 장에서는 각 경우에 대한 결정을 expected value에 기반하여 어떻게 계산할 지 알아보았다.
- 이번에는 다른 전략으로 ranking에 대해 알아볼 것이다.
- 각 경우를 분리하여 결정하기보다는, 예측된 점수를 기반으로 사례들의 순위를 매긴 다음 상위 n개의 경우를 택하는 것이다.
- 많은 경우, 그저 가장 성능이 좋은 n개의 케이스를 원할 때가 있다. 예를 들어 캠페인을 위한 마케팅 예산이 이미 정해져 있는 경우가 그렇다.
- 이러한 경우 각 경우의 정확한 확률 추정치는 그닥 중요하지 않다.
- 정확한 확률값을 구하기보다 상대적인 순위를 통해서 가장 효율적인 몇가지 방법만 택하는 것이다.
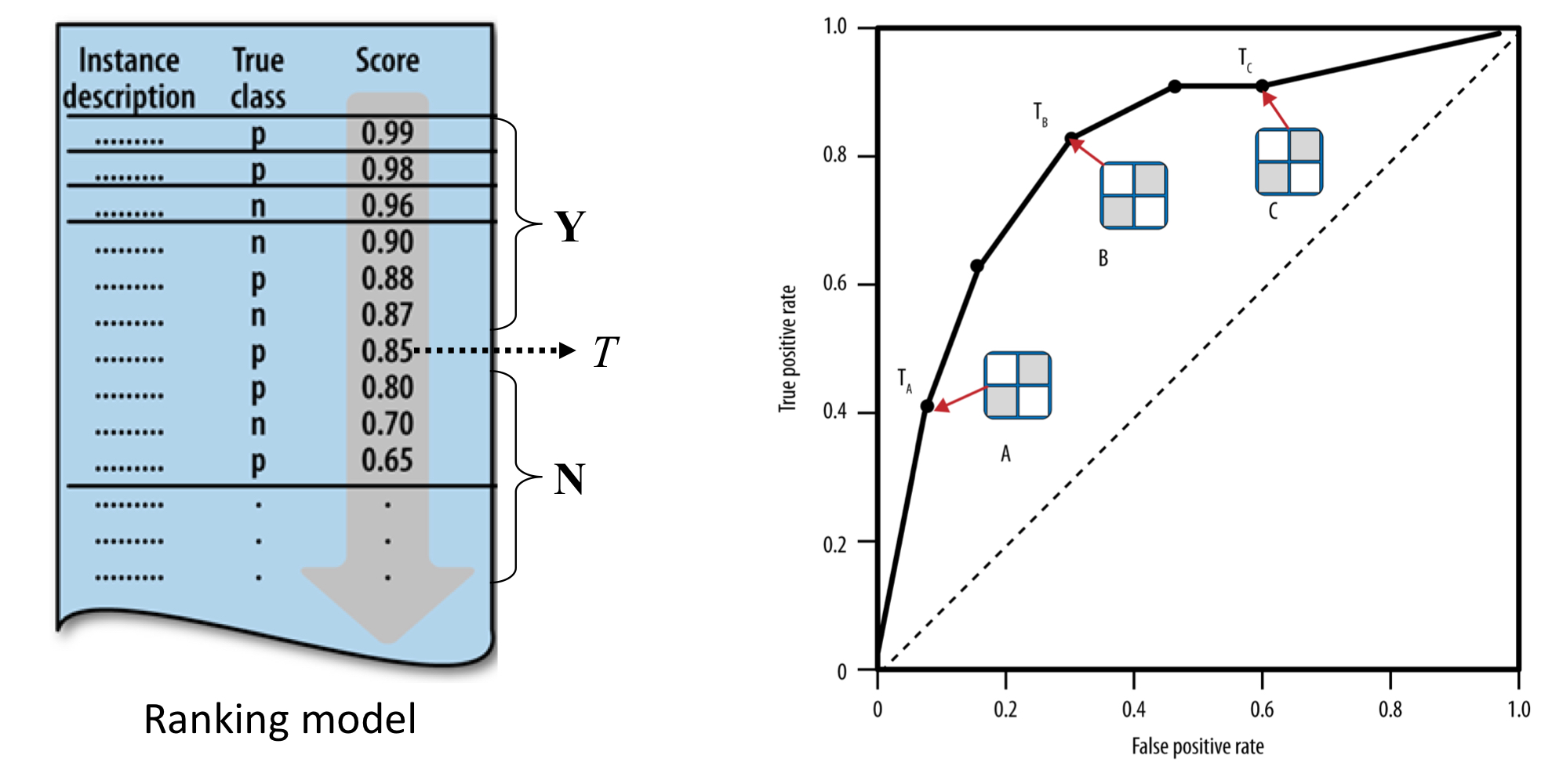
3. Ranking Instances
- 개체에 점수를 매기는 classifier가 있다고 하자. 이때 점수는 확률값 (or distance)이다.
- ex) class probability(decision tree, k-NN classifier), distance from the separating boundary(support vector machine, logistic regression)
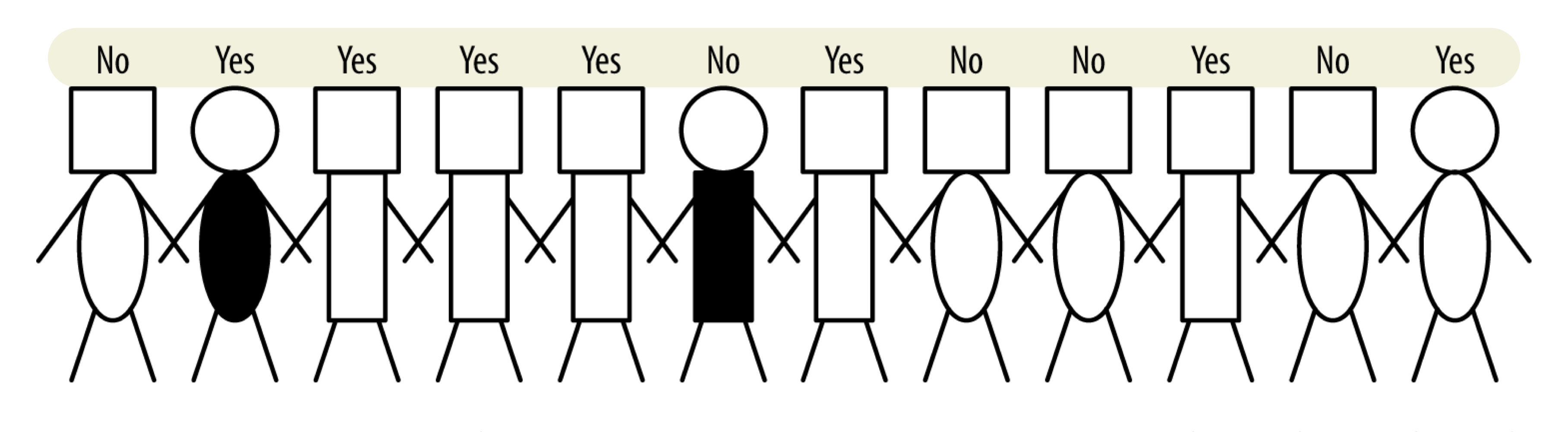
- 각 개체들을 점수에 따라 정렬한 후 특정한 값 T를 임계값으로 설정한다.
- 임계값을 높게 잡으면 정말 몇 개의 경우만 선택될 것이고, 임계값을 낮게 잡으면 가능한 많은 경우를 선택할 수 있을 것이다.
4. Thresholding Instances
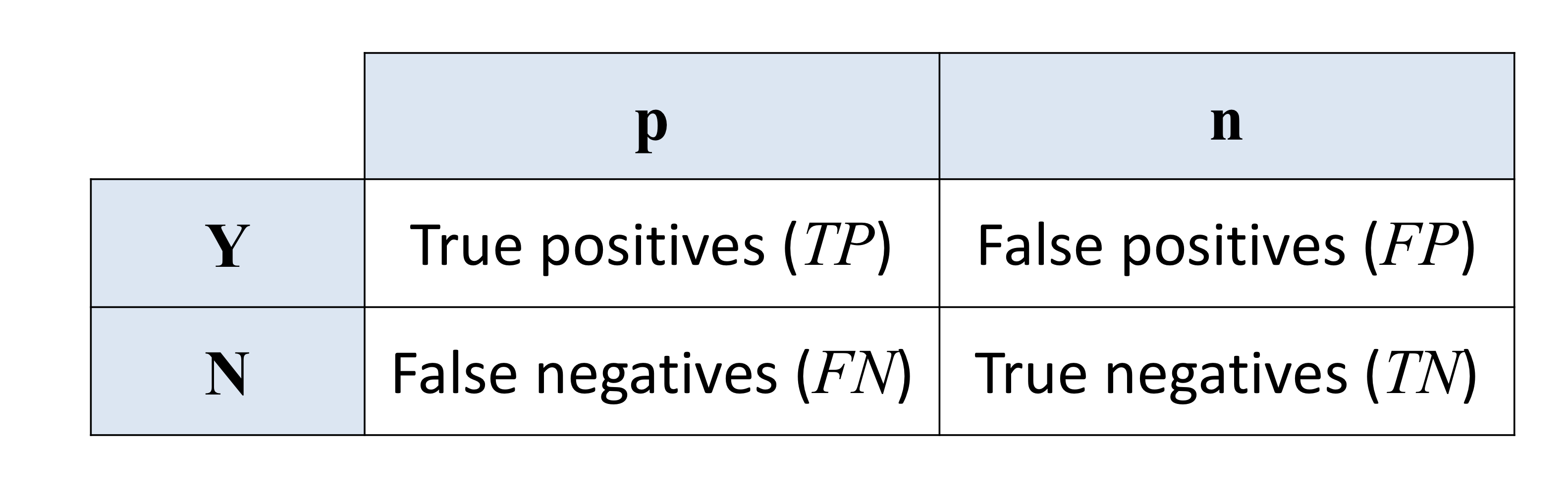
- 임계값이 변할 때마다 true positive와 false positive의 수가 달라진다.
- 따라서, 각 임계값마다 특정한 confusion matrix가 형성된다.
- 임계값을 기준으로 높은 순위는 'YES', 낮은 순위는 'NO'라고 예측하기 때문이다.
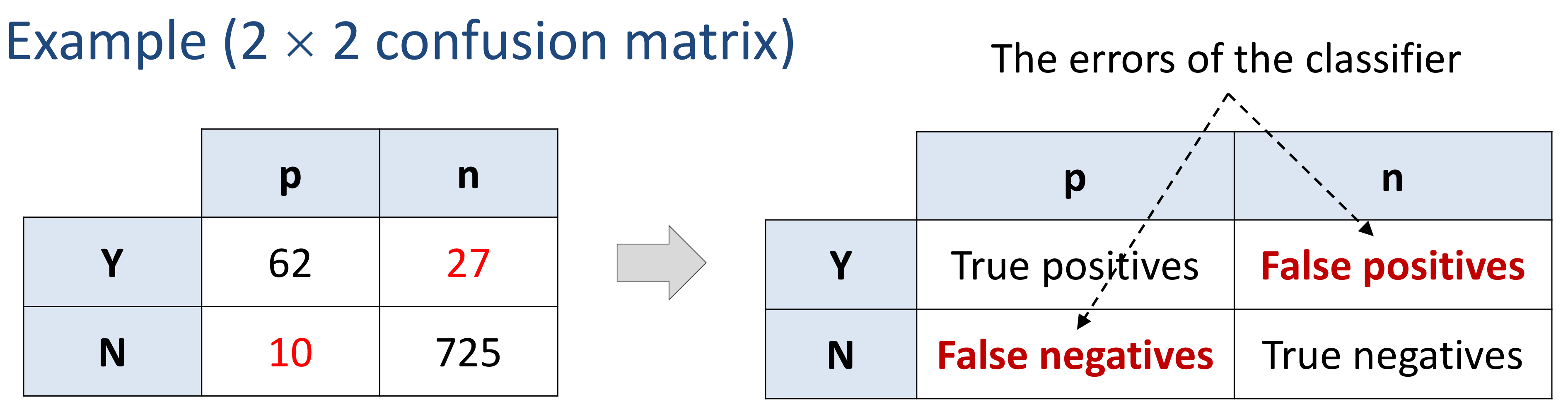
임계값에 따른 confusion matrix
- 임계값이 낮아질수록 개체들은 N에서 Y로 옮겨진다. (예측값이)
- (N, p) -> (Y, p), (N, n) -> (Y, n)
- 기술적으로, 각각의 임계값은 서로 다른 classifier를 생성한다.
- 그리고 각각의 confusion matrix를 통해 나타낸다.
- 그러면 다른 classifier에 의해 만들어진 순위는 서로 다른데 어떻게 비교해야 할까? 어떤 순위가 더 낫다고 볼 수 있을까?
- 또한, 적절한 임계값을 어떻게 찾을까?
- 이건 expected profit이 최대가 되는 임계값으로 결정할 수 있다.
5. Profit Curve
- 임계값에 따른 expected profit을 보여주는 곡선이다.
- 임계값이 낮아질수록 negative가 아니라 positive로 예측되는 개체들이 추가된다.
- 즉, 임계값이 낮아질수록 positive predict가 높아진다.
- 타겟 마케팅을 위한 3개의 classifier를 나타낸 profit curve이다.
- 각 곡선에 대해 고객들은 몇몇 모델에 기반하여 마케팅에 대해 응답할 확률에 따라 높은 확률부터 낮은 확률까지 정렬된다.
- 보통 고객의 비율에 대해 이야기할 것이다.
- x축은 임계값이고, y축은 그에 다른 이익이다.
- 곡선은 profit이 음수로 갈 수 있음을 보여준다. 항상 그런 것은 아니고 cost-benefit matrix에 따라 달라진다.
- 이윤이 작거나 응답자의 수가 작을 때 발생한다.
- 응답하지 않을 사람들에게 너무 많이 제공함으로써 비용을 너무 많이 지불하게 된다.
- 모든 곡선들은 같은 지점에서 시작해서 같은 지점에서 끝난다.
- 0%는 지출도 없고 이익도 없는 상태이다.
- 100%는 모든 사람들이 타겟이 된 상태이다. 따라서 모든 classifier가 같은 성능을 갖는다.
- 하지만, 그 사이에서는 classifier가 고객을 정렬한 방법에 따라 서로 다른 값을 갖는다.
- 직선인 경우는 random model을 적용한 경우로 최악의 성능을 갖는다.
- 위의 그래프에 따라 만약 마케팅에 예산이 정해져있어 8%의 고객에게만 제공할 수 있을 땐 x = 8 이내에서 가장 높은 값을 갖는 classifier 1을 선택하면 되고, 예산 상관없이 최고의 이익을 내고 싶다면 약 x = 50에서 가장 높은 값을 갖는 classifier 2를 선택하면 된다.
6. Two Limitation of Profit Curves
- 이전 장에서 본 조건부 확률을 이용하는 expected profit이다.
- 이 값을 이용하기 위해서는 사전확률인 p(p)와 p(n)을 알고 있어야 하고, 그 값은 안정적으로 고정되어 있어야 한다.
- 또한, cost와 benefit (b(h, a), c(h, a))도 알고 있어야 하고 안정적으로 고정되어 있어야 한다.
- 하지만, 많은 실제 경우에서는 이 값들은 정확하지 않고 불안정하다.
- ex) 사기 탐색의 경우 사기 금액이 정해져있지 않고 항상 변한다.
- churn 관리의 경우 고객에게 제공하는 상품의 금액이 항상 다를 것이다.
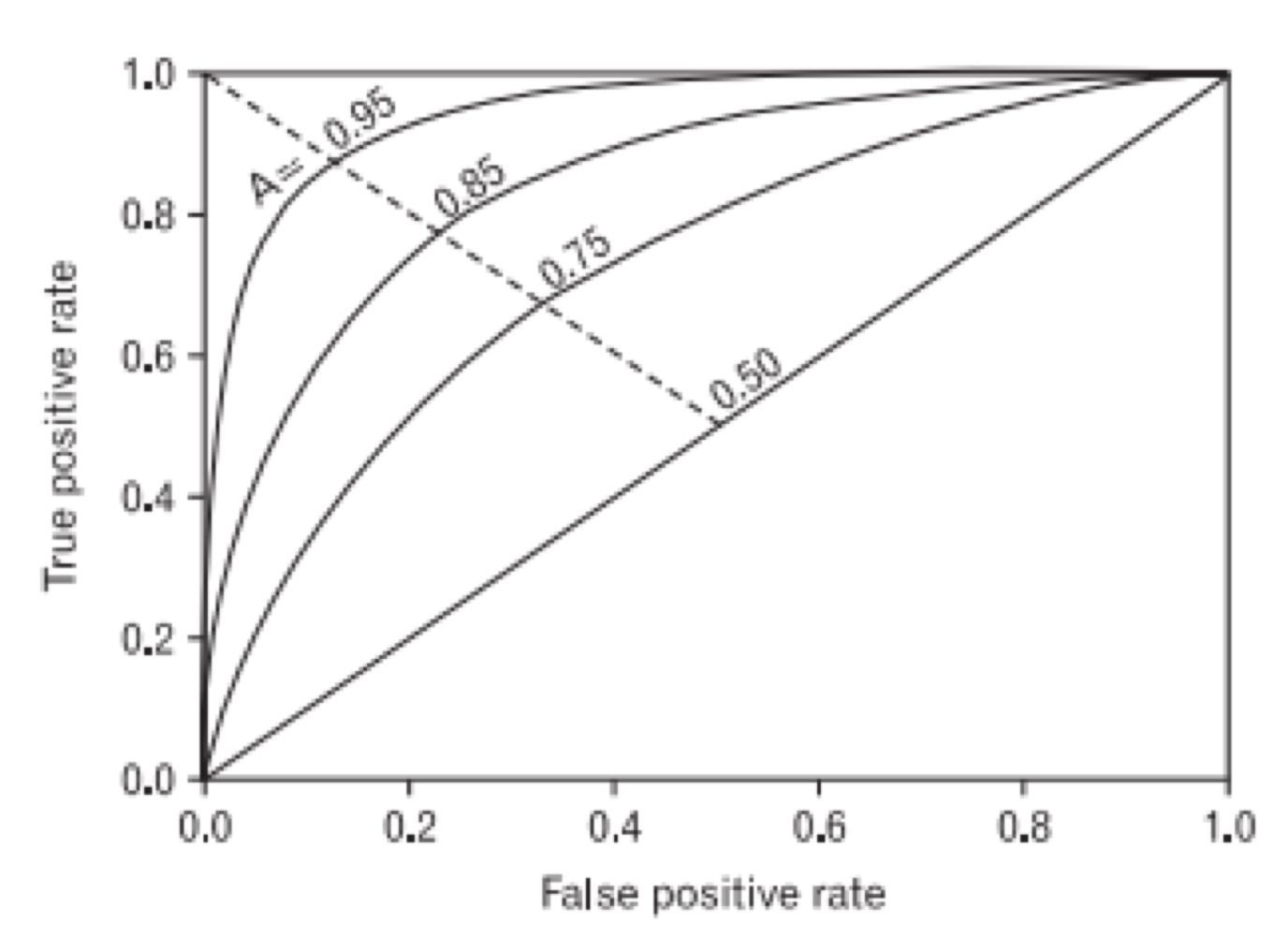
7. Receiver Operating Characteristic (ROC) Graph
- 전체 공간에 성능 가능성을 보여줌으로써 불확실성을 수용할 수 있는 방법이다.
- calssifier에 의해 만들어지는 benefits (true positives) 과 costs (false positives) 사이의 상대적인 성능값을 보여준다.
- F-measure F-값 = 2 x {(Precision x Recall) / (Precision + Recall)} : precision과 recall의 조화평균
- 이 세 가지는 정보 검색과 패턴 인식 (텍스트 분류) 에 널리 사용된다.
6. Baseline Performance
- 몇몇 경우, 우리는 모델이 어떤 기준선보다 더 나은 성능을 갖고있다고 증명해야 한다.
- 그렇다면 비교의 대상이 되는 적절한 기준선은 무엇일까?
- 그것은 실제 용도에 따라 다르다.
- 하지만 몇몇 일반적인 원칙들이 있다.
1) Random model
- 통제하기 쉬울 수 있지만, 그다지 흥미롭거나 유익하진 않을 것이다.
- 매우 어려운 문제나 처음 문제를 탐색할 때 유용할 것이다.
2) Simple (but not simplistic) model
- ex) weather forecasting
- 내일의 날씨는 오늘과 같을 것이다.
- 내일의 날씨는 과거부터 내일까지의 날씨의 평균일 것이다.
- 각 모델은 랜덤으로 예측하는 것보다 훨씬 나은 성능을 발휘한다. 어떤 새롭고 더욱 복잡한 모델도 이것들보다는 나은 성능을 가져야 한다.
3) The majority classifier 다수결
- 항상 훈련 데이터셋에서 다수의 클래스를 선택하는 방법이다.
- 우리는 모집단의 평균 값이라는 직접적으로 유사한 기준선을 가지고 있다.
- 보통 평균이나 중간값을 사용한다.
- ex) 추천 시스템 - 특정 영화가 주어졌을 때 고객이 몇개의 별점을 줄 지 예측해보자. - random model - simple models - model 1 : 고객이 영화들에게 준 별점의 평균 값을 사용할 것이다. - model 2 : 대중이 그 영화에 준 별점의 평균 값을 사용할 것이다. - combination of multiple simple models : 이 둘에 기초한 간단한 예측은 둘 중 하나를 따로 사용하는 것보다 훨씬 낫다.
- 간단한 모델을 비교하는 것 외에도, 배경 지식을 기반으로 한 간단하고 저렴한 모델을 기본 모델로 사용할 수 있다.
- ex) Fraud detection 사기 탐지 - 일반적으로 대부분 사기당한 계정들은 갑자기 사용률이 늘어난다고 알려져 있다. - 거래량 급상승에 대한 계좌 조회는 많은 사기를 잡기에 충분했다. - 이 아이디어를 구현하는 것은 간단하며, 유용한 기준선을 제공했다.