[출처: 실무로 배우는 빅데이터 기술, 김강원 저]
1. 클라우데라 매니저(CM) 설치
- CM : 빅데이터 에코시스템을 쉽게 설치하고 관리해주는 빅데이터 시스템 자동화 도구
- 빅데이터 소프트웨어에 대한 프로비저닝, 매니지먼트, 모니터링 수행
- 프로비저닝 : 하둡 에코시스템 편리하게 설치, 삭제, 수정 관리
- 매니지먼트 : 설치한 에코시스템의 설정 변경 및 최적화 지원
- 모니터링 : 하드웨어의 리소스 및 설치 컴포넌트의 상태 모니터링 / 대시보드
2. 가상머신 서버 설치
- 원래는 명령어를 이용하여 CM을 설치해야 하지만, 현재 CM 정책이 수정되어 책에 나와있는 명령어로 설치가 안됨
- 저자님의 깃허브에서 가상머신 2개 이미지 파일을 받을 수 있음
https://drive.google.com/file/d/1oLikMIC6bzt0jNV0n49YNOM0foNPXDZh/view?usp=sharing
Pilot Project VM.zip
drive.google.com
- 기존에 설치했던 서버들을 지우고, 이 이미지 파일로 서버를 설치하면 됨
3. 파일럿 pc 운영체제 호스트 파일 수정
- 메모장 관리자 권한으로 실행
- [파일] - [열기] 에서 C:\Windows\System32\drivers\etc 로 이동 후 hosts 파일 열기

- 가상머신에 설치한 리눅스 서버의 IP/도메인명 정보 입력 후 저장 (server01, server02만 입력)
4. 크롬으로 CM 접속
http://server01.hadoop.com:7180
- 기동하는데 시간이 조금 걸리기 때문에 접속이 바로 안되더라도 여러 번 새로고침
- 사용자 이름, 암호 모두 admin
- CM 첫화면
- 우선은 HDFS, YARN, ZooKeeper 만 설치

- CM 홈화면
- 각 서버의 리소스(CPU, 메모리, 디스크, I/O 등)와 설치된 SW 모니터링하며 현재 상태값 보여줌
- 각 소프트웨어가 불량으로 표시되어도, 정지 상태가 아니라면 진행에 문제 없음 -> 리소스 절약
5. HDFS 구성 변경
1) HDFS 복제 계수 설정
- 하둡에서 원본 파일을 저장하면 안정성을 위해 2개의 복제본 추가로 생성해 총 3개의 파일 만들어짐
- 파일럿 프로젝트에서는 2개로도 충분하기 때문에 2개로 변경
- 복제 계수를 늘리면 여러 데이터노드에 파일이 분산 저장되어 분석 작업시 성능 극대화

2) HDFS 접근 권한 해제
- 하둡 파일시스템에 대한 접근 권한 해제
- 테스트 환경을 고려한 설정. 실제 플젝에서는 계정별로 접근 권한 분리하여 적용

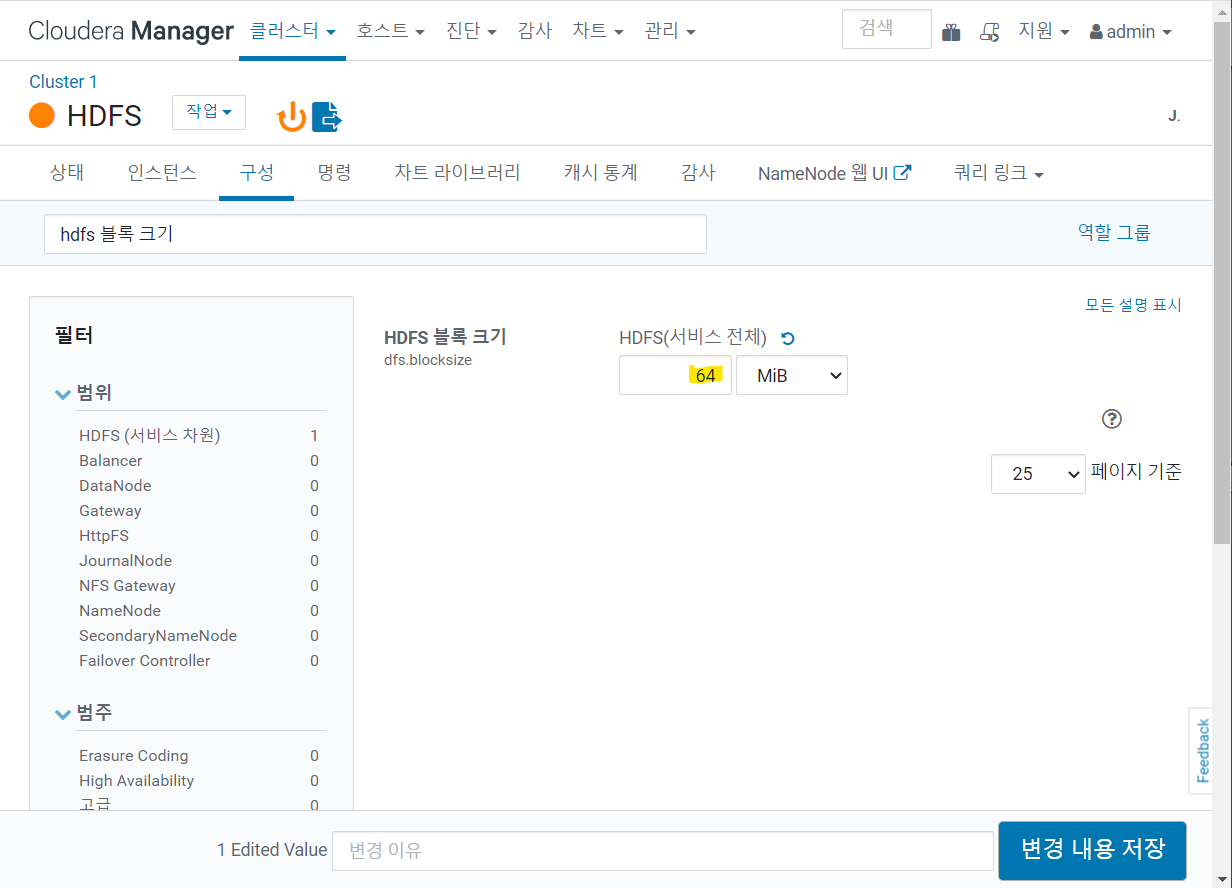
3) HDFS 블록 크기 변경
- 128MB -> 64MB
- 파일럿 프로젝트에서 수집/적재하는 파일의 최대 크기는 110MB
- 하둡은 기본 블록 크기보다 작은 파일 처리시 효율성 떨어짐
6. YARN 구성 변경
- YARN 스케줄러와 리소스매니저 메모리 크기 설정
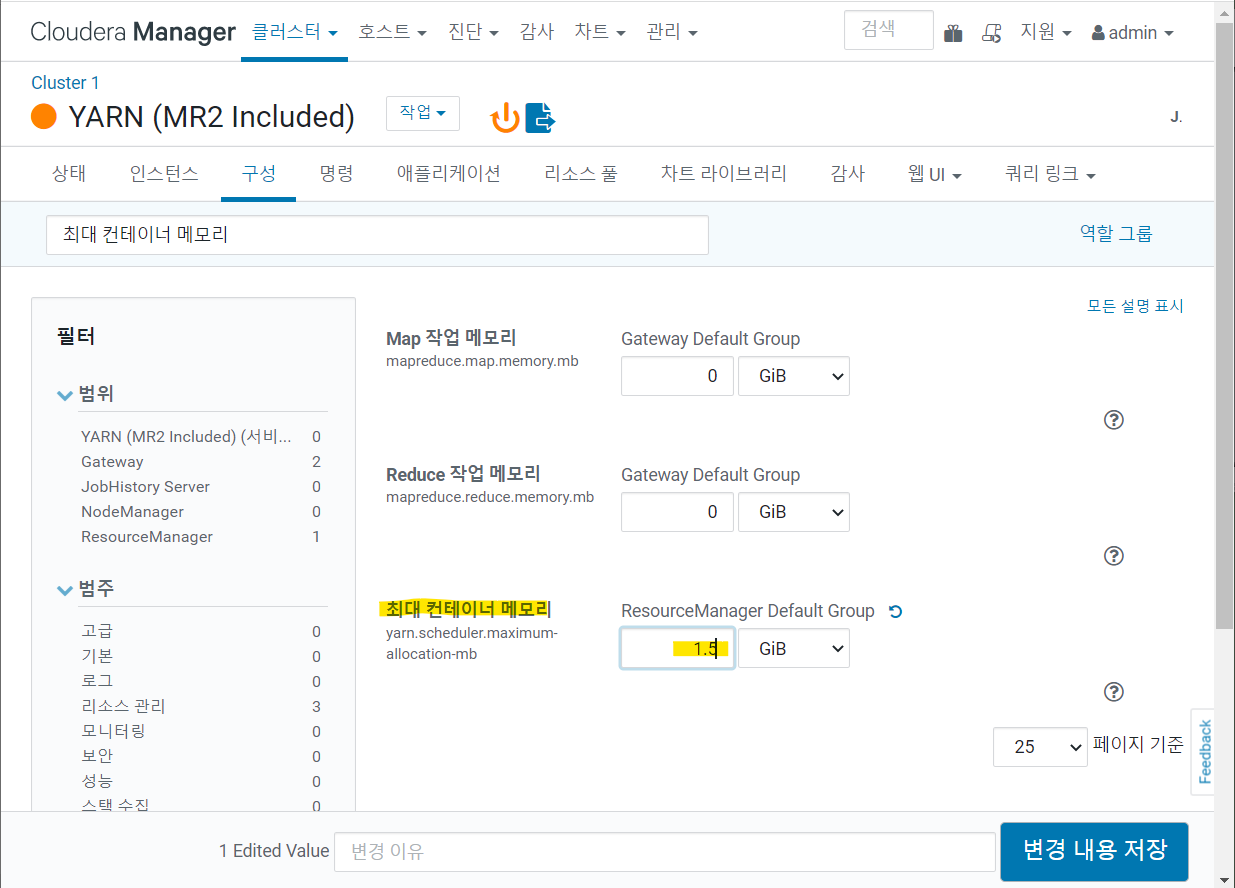
- 1-> 1.5 GiB
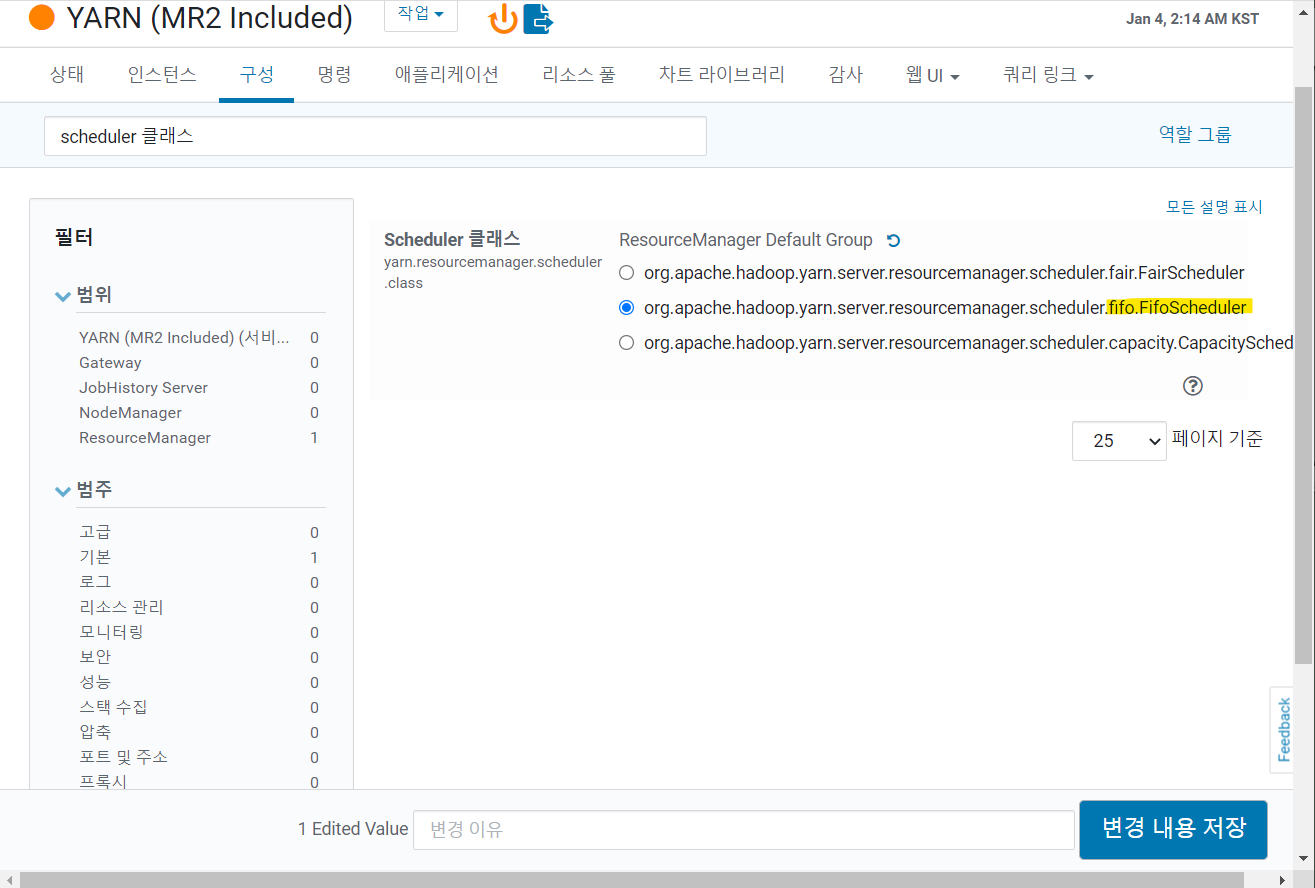
2) YARN 스케줄러 변경
- 하둡에서 job이 실행될 때 YARN의 스케줄러가 분산 데이터노드의 리소스를 고려해 잡 스케줄링
- FairScheduler -> FIFOScheduler
- Fair가 더 개선된 스케줄이지만, 개인의 pc로 이용하기에는 리소스 경합이 발생해 병목 현상 발생
* 병목 현상: 두 구성 요소의 최대 성능의 차이로 인해 한 구성 요소가 다른 하드웨어의 잠재 성능을 제한하는 것
7. 클러스터 재시작
- 설정들 최종 반영하기 위해 클러스터 재시작
- 홈에서 [Cluster 1] - [작업] - [재시작]

8. HDFS 예제 실습
- 저자님 깃허브에서 예제소스 폴더 다운로드 (제가 올려도 되는건지 모르겠어서 링크는 생략하겠습니다)
1) Filezilla로 샘플 txt 파일 -> server02 /home/bigdata 로 전송


* HDFS 명령어
https://hadoop.apache.org/docs/r3.1.2/hadoop-project-dist/hadoop-common/FileSystemShell.html
Apache Hadoop 3.1.2 – Overview
<!--- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or a
hadoop.apache.org
hdfs dfs [GENERIC_OPTIONS] [COMMAND_OPTIONS]# cat : 파일 읽어서 보여줌 (리눅스 cat과 동일)
hdfs dfs -cat [경로]
# count : 폴더, 파일, 파일 사이즈
hdfs dfs -count [경로]
# ls : 디렉터리 내부 파일
hdfs dfs -ls [디렉터리]
# mkdir : 특정 path에 디렉터리 생성
hdfs dfs -mkdir (-p) [path]
# cp : 파일 복사
hdfs dfs -cp [소스 경로] [복사 경로]
2) 파일 저장 및 확인
cd /home/bigdata
hdfs dfs -put Sample.txt /tmp- Sample.txt 파일이 HDFS의 /tmp 디렉터리로 저장됨
hdfs dfs -ls /tmp- 파일 목록에 Sample.txt 존재
3) 파일 내용 보기
hdfs dfs -cat /tmp/Sample.txt
4) 저장한 파일 상태 확인
hdfs dfs -stat '%b %o %r %u %n' /tmp/Sample.txt- 파일 크기, 파일 블록 크기, 복제 수, 소유자명, 파일명 정보 보여줌
5) 파일 이름 바꾸기
hdfs dfs -mv /tmp/Sample.txt /tmp/Sample2.txt- Sample.txt -> Sample2.txt로 변경
6) 파일 시스템 상태 검사
hdfs fsck /- 전체 크기, 디렉터리 수, 파일 수, 노트 수 등 파일 시스템의 전체 상태 보여줌
hdfs dfsadmin -report- 하둡 파일시스템의 기본 정보 및 통계 보여줌
* HDFS 파일의 비정상 상태
- HDFS 점검 명령을 실행할 때 파일 시스템에 문제가 발생할 경우 "CORRUPT FILES", "MISSING BLOCKS", "MISSING SIZE", "CORRUPT BLOCKS" 등의 항목에 숫자가 표기됨
- 이 같은 상태가 지속되면 하둡은 물론 HBase, 하이브 등에 부분적인 문제 발생 가능
- HDFS는 비정상적인 파일 블록 발견한 경우 다른 노드에 복구하려고 시도, 사용자가 직접 삭제/이동 명령 조치할 수 있음
# 강제로 안전모드 해제
hdfs dfsadmin -safemode leave
# 손상된 파일 강제로 삭제
hdfs fsck / -delete
# 손상된 파일을 /lost + found 디렉터리로 이동
hdfs fsck / -move
9. 주키퍼 클라이언트 명령을 이용한 설치 확인
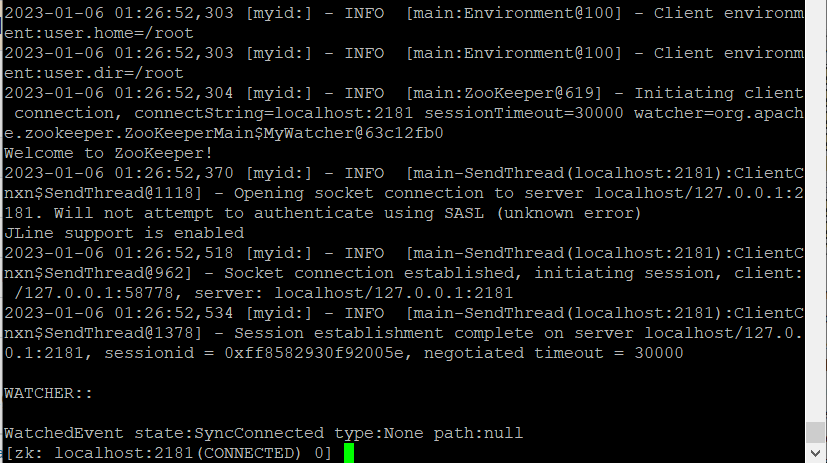
1) zookeeper-client 실행
zookeeper-client
2) 주키퍼 z노드 등록/조회/삭제
create /pilot-pjt bigdata
ls /
get /pilot-pjt
delete /pilot-pjt
- bigdata를 담고 있는 pilot-pjt 라는 znode 생성, 조회, 삭제
** zookeeper와 znode
- zookeeper : 분산 어플리케이션을 구성하기 쉽게 도와주는 시스템 (znode로 구성된 분산 데이터 모델을 지원하는 시스템)
- z노드 : 클러스터를 구성하고 있는 각각의 서버
- 주키퍼는 데이터를 디렉터리 구조로 관리하며, key-value 스토리지처럼 key로 접근 가능
- 디렉터리 구조의 각 데이터 노드가 znode
# 참고 사이트
https://engkimbs.tistory.com/660
[주키퍼, Zookeeper] 아파치 주키퍼(Apache Zookeeper) 소개 및 아키텍처
| 대규모 분산 시스템과 코디네이션 시스템의 필요성? 과거에는 한 대의 컴퓨터에서 동작하는 단일 프로그램이 대다수였지만, 현재 빅데이터와 클라우드 환경에서 대규모의 시스템들이 동작하
engkimbs.tistory.com
10. 스마트카 로그 시뮬레이터 설치
1) server02에 작업 폴더 생성
cd /home
mkdir -p /home/pilot-pjt/working/car-batch-log
mkdir /home/pilot-pjt/working/driver-realtime-log
chmod 777 -R /home/pilot-pjt
2) 자바 컴파일, 실행 환경 변경 (1.7 -> 1.8)
rm /usr/bin/java
rm /usr/bin/javac
ln -s /usr/java/jdk1.8.0_181-cloudera/bin/javac /usr/bin/javac
ln -s /usr/java/jdk1.8.0_181-cloudera/bin/java /usr/bin/javajava -version- 1.8.0_181 확인

3) 자바로 만들어진 스마트카 로그 시뮬레이터 프로그램 server02에 업로드
- 파일질라 이용

- bigdata.smartcar.loggen-1.0.jar 파일을 /home/pilot-pjt/working에 업로드
# 저 파일을 열어서 코드를 보고싶었는데 일단 찾은 방법들이 전부 맥으로는 실행이 안돼서 다음에 시도해보겠음 ,,
4) 스마트카 로그 시뮬레이터 실행
- bigdata.smartcar.loggen-1.0.jar 파일에 두 개의 메인 자바프로그램이 있음
- 1. 스마트카 운전자의 운행 정보를 실시간으로 발생시키는 DriverLogMain.java
- 2. 스마트카의 상태 정보를 주기적으로 발생시키는 CarLoginMain.java
- DriverLogMain.java 먼저 실행
cd /home/pilot-pjt/working
java -cp bigdata.smartcar.loggen-1.0.jar com.wikibook.bigdata.smartcar.loggen.DriverLogMain 20160101 10* java -cp [경로] [클래스 이름] (현재 열려 있는 명령 창에서만 유효)
- cp (classpath) : JVM이 프로그램을 실행할 때 클래스 파일을 찾는 데 기준이 되는 파일 경로, JVM의 매개 변수
- 자바에서 외부 라이브러리 파일이나 jar 파일 포함하여 컴파일하기 위해서는 classpath 이용
- bigdata.smartcar.loggen-1.0.jar : 포함하고자 하는 라이브러리나 jar 파일 (필요한 클래스 파일들)
- com.wikibook.bigdata.smartcar.loggen.DriverLogMain : 컴파일 할 파일
- 시뮬레이터 작동 확인
cd /home/pilot-pjt/working/driver-realtime-log
tail -f SmartCarDriverInfo.log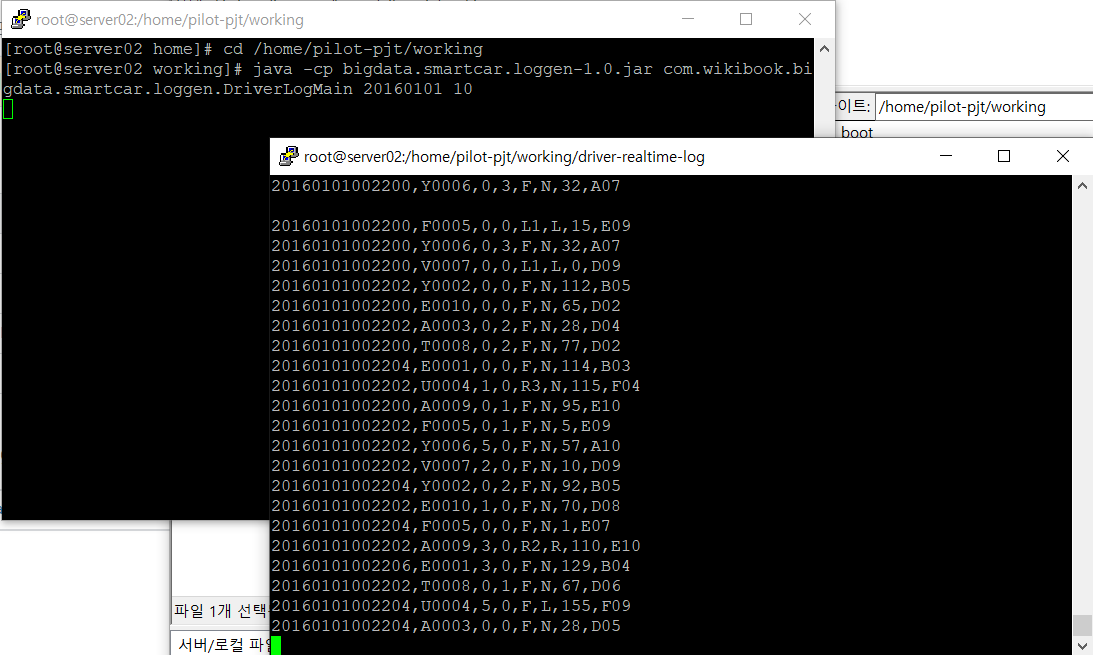
- 데이터 형식 정의

- CarLogMain.java 실행
cd /home/pilot-pjt/working
java -cp bigdata.smartcar.loggen-1.0.jar com.wikibook.bigdata.smartcar.loggen.CarLogMain 20160101 10* 코드 설명
- 첫번째 매개 변수: 실행 날짜
- 두번째 매개 변수: 스마트카 대 수
-> 2016년 1월 1일 기준으로 10대의 스마트카에 대한 로그 파일인 SmartCarStatusInfo_20160101.txt 생성됨
- 시뮬레이터 작동 확인
cd /home/pilot-pjt/working/SmartCar
tail -f SmartCarStatusInfo_20160101.txt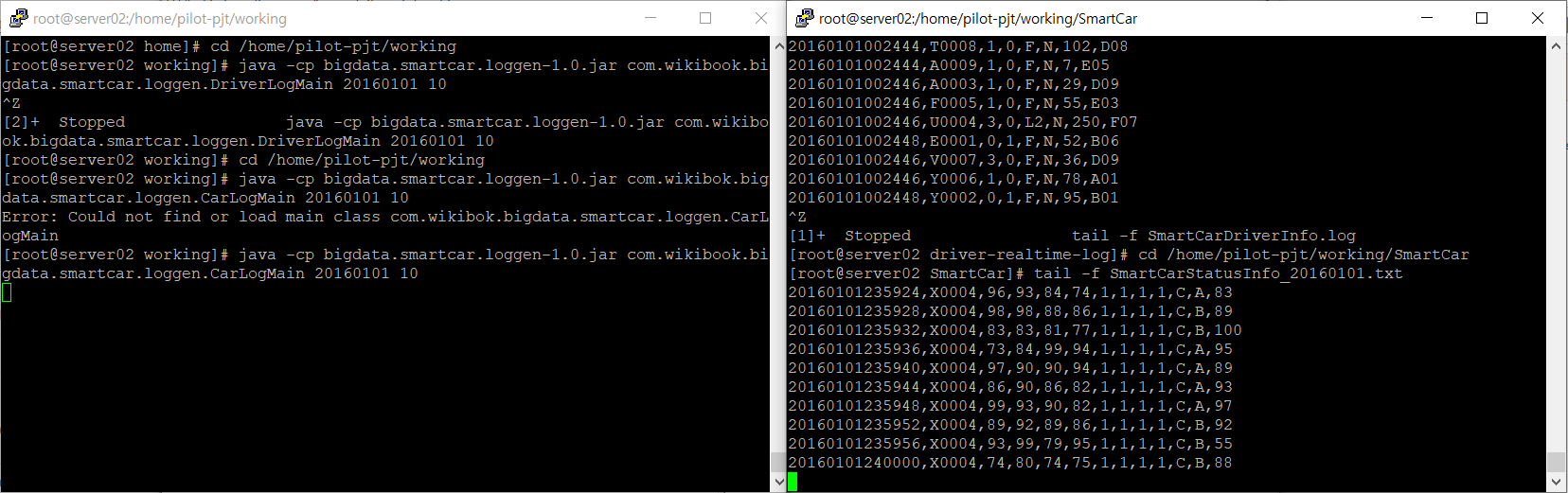
- 데이터 형식 정의

'Data Engineering' 카테고리의 다른 글
| [DACOS] Ch03 이론. 빅데이터 수집 (2) | 2023.01.21 |
|---|---|
| [DACOS] Ch2 실습. 파일럿 프로젝트 환경설정(1) (6) | 2023.01.02 |
| [DACOS] Ch02 이론. 빅데이터 파일럿 아키텍처 (0) | 2022.12.28 |