1. 상속
- 부모 클래스에 정의된 멤버 변수, 메소드를 자식 클래스가 물려 받음
- class 자식 extends 부모 { }
class Car {
int speed;
public void setSpeed(int Speed) {
this.speed = speed;
}
}
public class EletricCar extends Car {
int battery;
public void charge(int amount) {
battery += amount;
}
}
public class ElectricCarTest {
public static void main(String[] args) {
ElectricCar obj = new ElectricCar();
obj.speed = 10;
obj.setSpeed(60);
obj.charge(10);
}
}
- 상속 -> 이미 존재하는 클래스의 필드와 메소드 재사용 -> 중복되는 코드 줄일 수 있음

2. 자바 상속의 특징
- 다중 상속 지원하지 않음 (여러 개의 클래스로부터 상속 X)
- 다단계 상속은 가능 (A / B extends A / C extends B)
- 상속의 횟수에는 제한 없음 (자식 클래스의 개수 상관 X)
- 상속 계층 구조의 최상위에는 java.lang.Object 클래스가 있음
- 모든 클래스의 부모 클래스
- toString( ) 메소드
- 다른 패키지의 클래스도 상속 가능 (패키지.클래스 import 필요)
class Animal {
int age;
void eat() {
System.out.println("먹고 있음 ... ");
}
}
class Dog extends Animal {
void bark() {
System.out.println("짖고 있음 ...");
}
}
public class DogTest {
public static void main(String[] args) {
Dog d = new Dog();
d.bark();
d.eat();
}
}
// 짖고 있음 ...
// 먹고 있음 ...
class Shape {
int x, y;
}
class Circle extends Shape {
int radius;
public Circle(int radius) {
this.radius = radius;
x = 0;
y = 0;
}
double getArea() {
return 3.18 * radius * radius;
}
public class CircleTest {
public static void main(String[] args) {
Circle obj = new Circle(10);
System.out.println("원의 중심: (" + obj.x + "," + obj.y + ")");
System.out.println("원의 면적: " + obj.getArea());
}
}
// 원의 중심: (0,0)
// 원의 면적: 314.0
3. 상속과 접근 지정자
- 자식 클래스는 부모 클래스의 public 멤버, protected 멤버, 디폴트 멤버(같은 패키지에 있는 경우) 상속 받음
- private 멤버는 상속되지 않음!
4. 상속과 생성자
- 자식 클래스의 객체가 생성될 때 부모 클래스의 생성자도 호출됨!
class Base {
public Base() {
System.out.println("Base() 생성자");
}
}
class Derived extends Base {
public Derived() {
System.out.println("Derived() 생성자");
}
}
public class Test {
public static void main(String[] args) {
Derived r = new Derived();
}
}
// Base() 생성자
// Derived() 생성자
- 자식 클래스 객체 안에는 부모 클래스에서 상속된 부분이 들어있음
-> 부모 클래스 부분을 초기화하기 위해 부모 클래스의 생성자도 호출됨
- 순서) (부모 클래스 생성자) -> (자식 클래스 생성자)
5. 명시적인 생성자 호출
- super(); : 부모 클래스의 생성자 호출
class Base {
public Base() {
System.out.println("Base() 생성자");
}
}
class Derived extends Base {
public Derived() {
super();
System.out.println("Derived() 생성자");
}
}class TwoDimPoint {
int x, y;
public TwoDimPoint() {
x = y = 0;
}
public TwoDimPoint(int x, int y) {
this.x = x;
this.y = y;
}
}
class TreeDimPoint extends TwoDimPoint {
int z;
public ThreeDimPoint(int x, int y, int z) {
super(x, y);
this.z = z;
}
}- 이 경우 부모 클래스의 두 생성자 중 TwoDimPoint(int x, int y)가 호출됨
- 인수의 형태에 따라 적절한 생성자 선택
6. 묵시적인 생성자 호출
class Base {
public Base() {
System.out.println("Base() 생성자");
}
}
class Derived extends Base {
public Derived() {
System.out.println("Derived() 생성자");
}
}- 컴파일러는 부모 클래스의 기본 생성자가 자동으로 호출되도록 함
- 묵시적인 생성자 호출을 하려면 부모 클래스에 기본 생성자(매개 변수가 없는 생성자)가 반드시 정의되어 있어야 함!
7. 메소드 오버라이딩
- 자식 클래스가 부모 클래스의 메소드를 자신의 필요에 맞춰 재정의하는 것
- 메소드 이름이나 매개 변수, 반환형은 같아야 함!
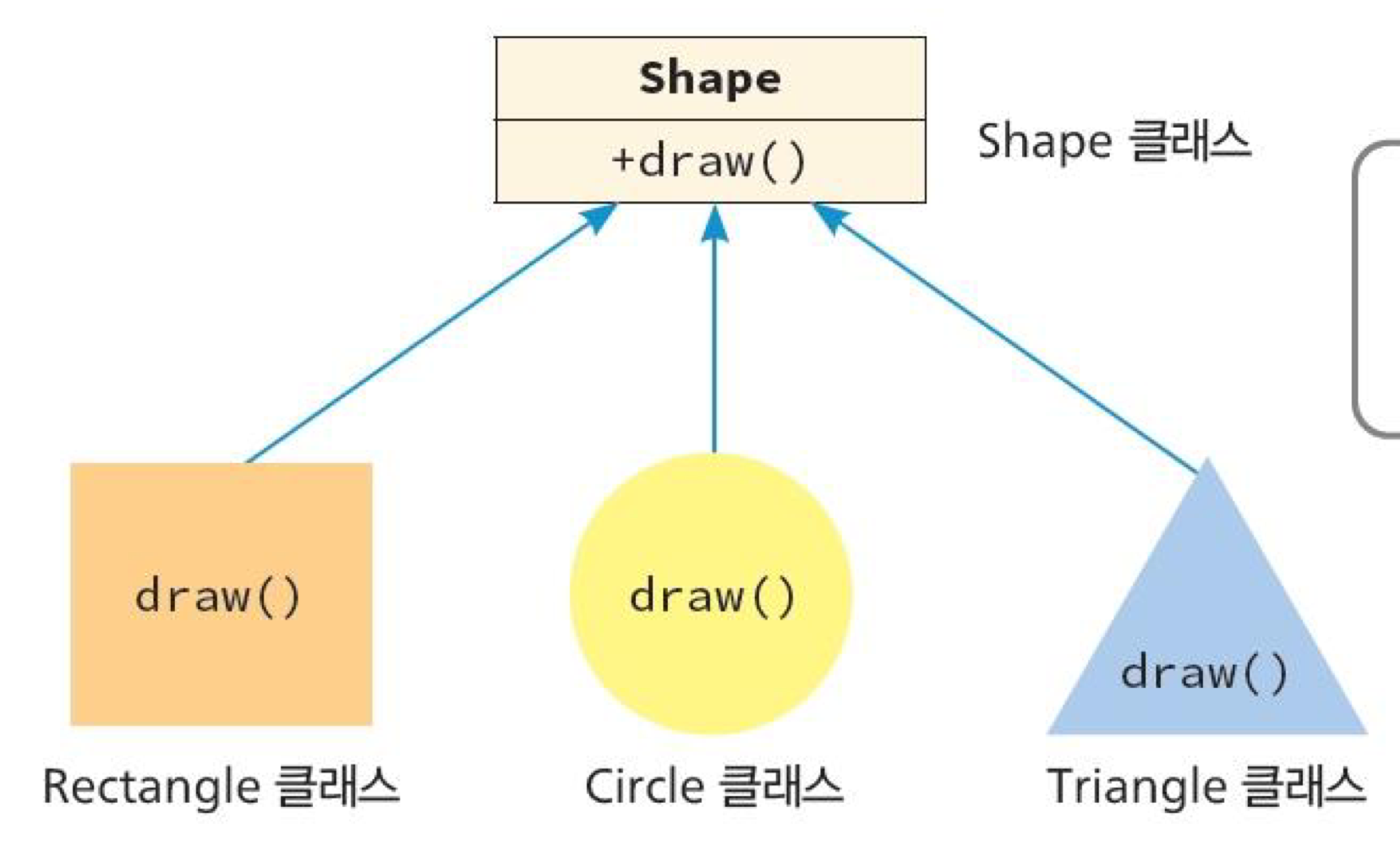
class Shape {
public void draw() { System.out.println("Shape"); }
}
class Circle extends Shape {
@override
public void draw() { System.out.println("Circle을 그립니다."); }
}
class Rectangle extends Shape {
@override
public void draw() { System.out.println("Rectangle을 그립니다."); }
}
class Triangle extends Shape {
@override
public void draw() { System.out.println("Triangle을 그립니다."); }
}
public class ShapeTest {
public static void main(String[] args) {
Rectangle s = new Rectangle();
s.draw();
}
}
// Rectangle을 그립니다.- Rectangle 클래스의 객체에 대해 메소드가 호출되면 Rectangle 클래스 안에서 오버라이딩된 draw()가 호출됨
- 철자를 잘못 쓰는 경우 컴파일러는 새로운 메소드로 인식하기 때문에 오버라이드가 일어나지 않음
-> @Override 어노테이션을 앞에 붙이면 이러한 경우 오류 발생시키므로 붙이는 것이 좋음!
8. 오버라이딩 & 오버로딩
- 오버로딩 (overloading) : 같은 이름을 가진 여러 개의 메소드 작성
- 오버라이딩 (overriding) : 부모 클래스의 메소드를 자식 클래스가 다시 정의하는 것
9. 정적 메소드 오버라이드
- 어떤 참조 변수를 통해 호출되는지에 따라 달라짐
class Animal {
public static void A() {
System.out.println("static method in Animal");
}
}
public class Dog extends Animal {
public static void A() {
System.out.println("static method in Dog");
}
public static void main(String[] args) {
Dog dog = new Dog();
Animal a = dog;
a.A();
dog.A();
}
}
// static method in Animal
// static method in Dog
10. 키워드 super
- super는 상속 관계에서 부모 클래스의 메소드나 필드를 명시적으로 참조하기 위해 사용됨
- 부모 클래스의 메소드를 오버라이딩한 경우에 super를 사용하면 부모 클래스의 메소드 호출 가능
class Shape {
public void draw() {
System.out.println("Shape 중에 하나를 그릴 예정입니다.");
}
}
class Circle extends Shape {
@Override
public void draw() {
super.draw(); // 부모 클래스의 draw 호출
system.out.println("Circle을 그립니다.");
}
}
public class ShapeTest {
public static void main(String[] args) {
Circle s = new Circle();
s.draw;
}
}
// Shape 중에 하나를 그릴 예정입니다.
// Circle을 그립니다.
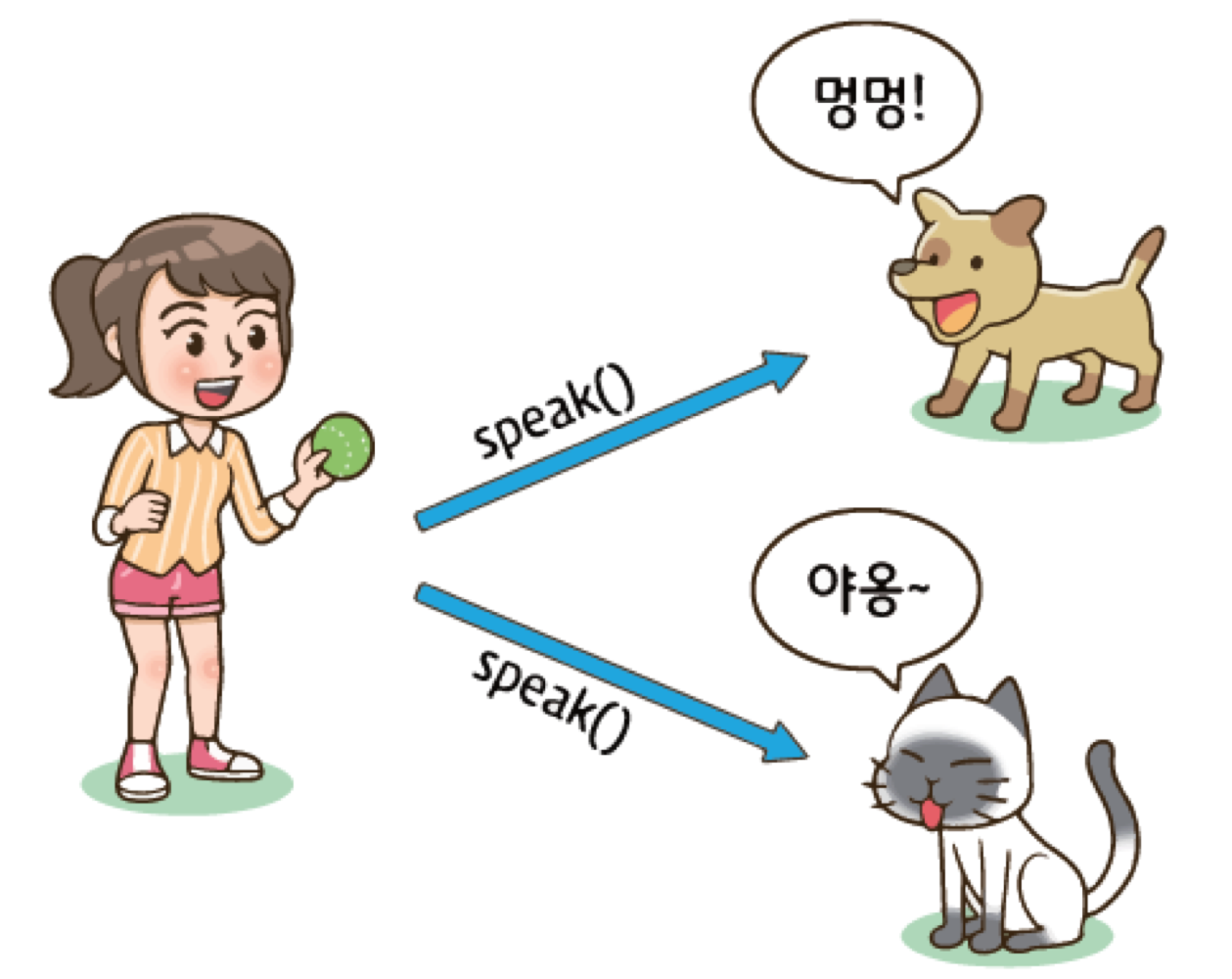
11. 다형성
- 오버로딩은 컴파일 시간에서의 다형성 지원
- 메소드 오버라이딩은 실행 시간에서의 다형성 지원
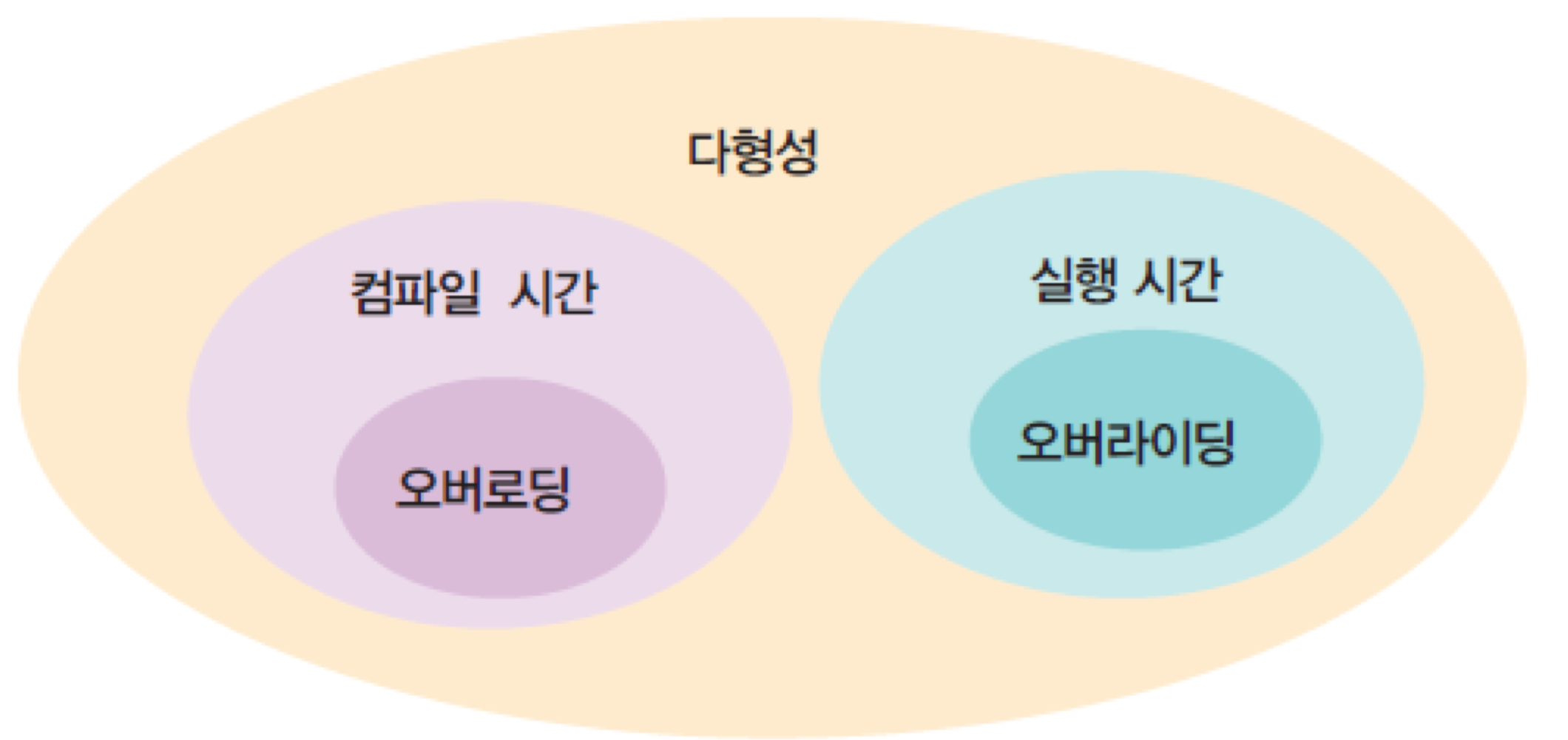
- 다형성: 객체들의 타입이 다르면 똑같은 메시지가 전달되더라도 서로 다른 동작을 하는 것
- 동일한 코드로 다양한 타입의 객체를 처리할 수 있는 기법
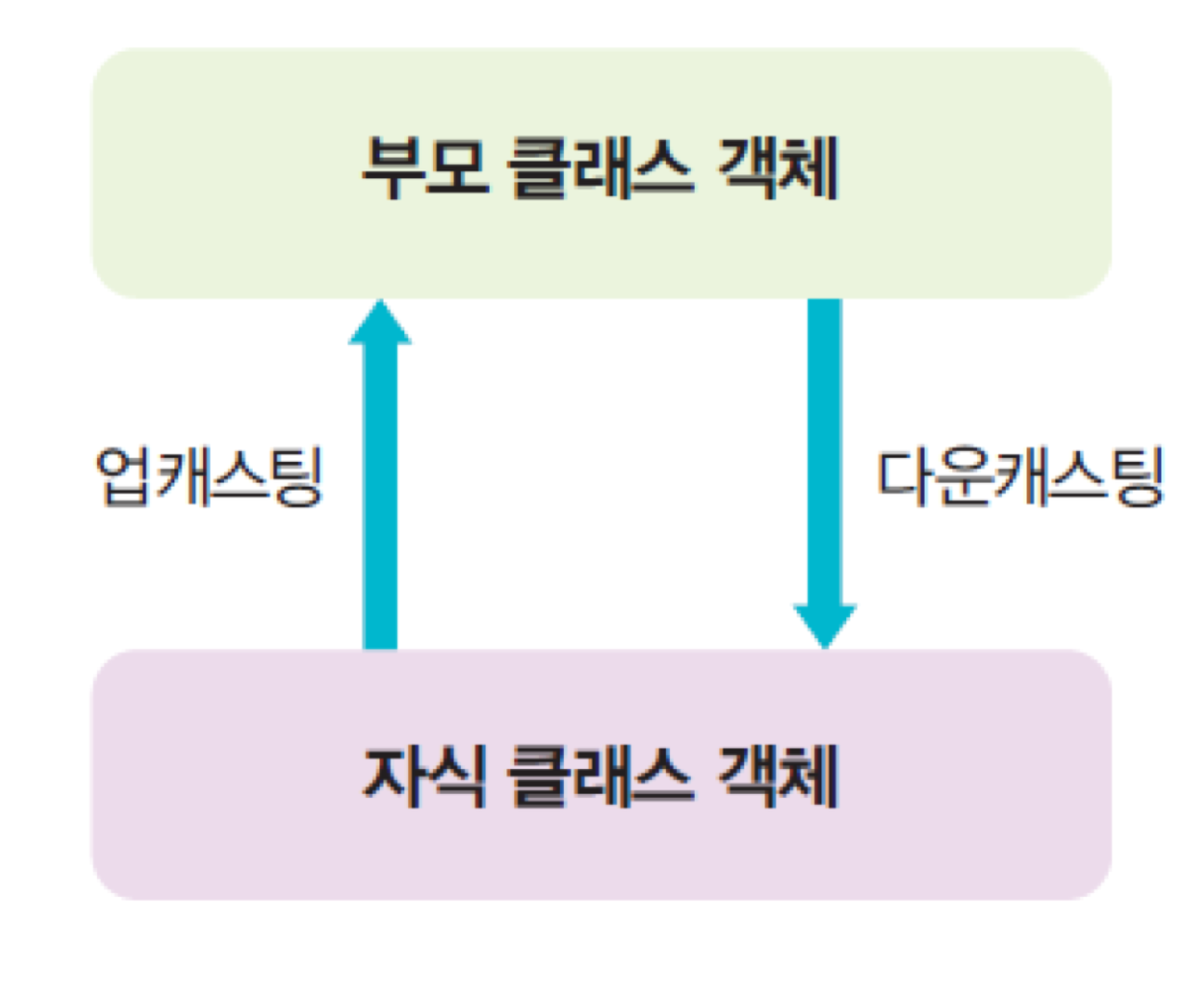
12. 업캐스팅
- 부모 클래스 변수로 자식 클래스 객체 참조 가능!
- 자식 클래스의 필드와 메소드에는 접근할 수 없음
- 자식 클래스의 부모 클래스 부분만 접근 가능!
- ex) Rectangle 클래스의 x, y (O) // width, height (X)
- 부모 클래스로 캐스팅 된다는 것은 멤버의 갯수 감소 의미! (부모 클래스의 멤버만 접근 가능)
- 업캐스팅을 하고 메소드를 실행할때 자식 클래스에서 오버라이딩한 메소드가 있을 경우, 오버라이딩 된 메소드가 실행됨!
// ex) Rectangle, Triangle, Circle 등의 도형 클래스가 부모 클래스인 Shape 클래스로부터 상속된 경우
class Shape {
protected int x, y; // 모든 도형의 공통 속성인 위치 기준점 (x, y)
public void draw() { System.out.println("Shape draw"); }
}
class Rectangle extends Shape {
private int width, height;
public void draw() { System.out.println("Rectangle draw"); }
}
class Triangle extends Shape {
private int base, height;
public void draw() { System.out.println("Triangle draw"); }
}
class Circle extends Shape {
private int radius;
public void draw() { System.out.println("Circle draw"); }
}
public class ShapeTest {
public static void main(String[] args) {
Shape s1, s2;
s1 = new Shape();
s2 = new Rectangle();
}
}publc class ShapeTest {
public static void main(String[] args) {
Shape s = new Rectangle();
// 업캐스팅
// s는 Shape 타입, Rectangle 객체 가리킴
Rectangle r = new Rectangle();
s.x = 0;
x.y = 0;
//s.width = 100; -> 오류!
//s.height = 100; -> s로 Rectangle의 필드와 메소드에 접근할 수 없음
}
}
- 다운캐스팅: 부모 객체를 자식 참조 변수로 참조하는 것, 명시적으로 해야 함
class Parent {
void print() { System.out.println("Parent 메소드 호출"); }
}
class Chile extends Parent {
@Override void print() { System.out.println("Child 메소드 호출"); }
}
public class Casting {
public static void main(String[] args) {
Parent p = new Child(); // 업캐스팅: 자식 객체를 부모 객체로 형변환
p.print(); // 동적 메소드 호출, 자식의 print() 호출
// Child c = new Parent(); -> 컴파일 오류!
Child c = (Child)p; // 다운캐스팅: 부모 객체를 자식 객체로 형변환
c.print(); // 메소드 오버라이딩, 자식의 print() 호출
}
}
// Child 메소드 호출
// Child 메소드 호출
13. 업캐스팅 하는 이유
- 공통적으로 할 수 있는 부분을 만들어 간단하게 다루기 위해
- 상속 관계에서 상속 받은 자식 클래스가 몇 개이든 하나의 인스턴스로 묶어서 관리할 수 있기 때문
// 기존
Rectangle[] r = new Rectangle[];
r[0] = new Rectangle();
r[1] = new Rectangle();
Triangle[] t = new Triangle[];
t[0] = new Triangle();
t[1] = new Triangle();
Circle[] c = new Circle[];
c[0] = new Circle();
c[1] = new Circle();// 업캐스팅
Shape[] s = new Shape[];
s[0] = new Rectangle();
s[1] = new Rectangle();
s[2] = new Triangle();
s[3] = new Triangle();
s[4] = new Circle();
s[5] = new Circle();- 하나의 타입으로 묶어 배열을 구성
- 코드량도 훨씬 줄어들고 가독성도 좋아지며 유지보수성도 좋아짐
- 자식 고유의 메소드 실행하려면 다운캐스팅
14. 동적 바인딩
- 업캐스팅: 여러 가지 타입의 객체를 하나의 자료구조 안에 모아서 처리하려는 경우에 필요
- 도형 클래스 예제) 각 도형을 그리는 방법은 모두 다르기 때문에 종류에 따라 다른 draw() 호출해야 함
- Shape 클래스가 draw() 갖고 있고, 자식 클래스들이 이 draw() 오버라이딩 한 경우
public class ShapeTest {
public static void main(String[] args) {
Shape[] arrayOfShapes; // Shape의 배열 arrayOfShapes[] 선언
arrayOfShapes = new Shape[3];
// 배열 arrayOfShapes의 각 원소에 객체를 만들어 대입
// 다형성에 의해 Shape 객체 배열에 모든 타입의 객체 저장 가능
arrayOfShapes[0] = new Rectangle();
arrayOfShapes[1] = new Triangle();
arrayOfShapes[2] = new Circle();
for (int i = 0; i < arrayOfShapes.length; i++) {
arrayOfShapes[i].draw();
}
}
}
// Rectangle draw
// Triangle draw
// Circle draw
15. 업캐스팅의 활용
- 메소드의 매개 변수를 부모 타입으로 선언하면 훨씬 넓은 범위의 객체 받을 수 있음
- 부모 클래스에서 파생된 모든 클래스의 객체를 다 받을 수 있음
public class ShapeTest {
public static void print(Shape s) {
System.out.println("x= " + s.x + " y= " + s.y);
}
public static void main(String[] args) {
Rectangle s1 = new Rectangle();
Triangle s2 = new Triangle();
Circle s3 = new Circle();
print(s1);
print(s2);
print(s3);
}
}
16. instanceof 연산자
- 변수가 가리키는 객체의 실제 타입 반환
17. 종단 클래스와 종단 메소드
- 종단 클래스(final class) : 상속시킬 수 없는 클래스
- 보안상의 이유로 주로 사용
- 서브 클래스에서 재정의 불가
final class String {
...
}
class Baduk {
enum Player { WHITE, BLACK }
...
final Player getFirstPlayer() {
return Player.BLACK;
}
}'Software > JAVA' 카테고리의 다른 글
| [JAVA] Day7. 자바 API 패키지, 예외처리, 모듈 (0) | 2023.01.02 |
|---|---|
| [JAVA] Day6. 추상클래스, 인터페이스, 중첩클래스 (0) | 2022.12.29 |
| [JAVA] Day 3-4. 클래스와 객체 (2) | 2022.12.29 |
| [JAVA] Day2. 조건문, 반복문, 배열 (0) | 2022.12.27 |
| [JAVA] Day1. 자바 기초 (0) | 2022.12.27 |