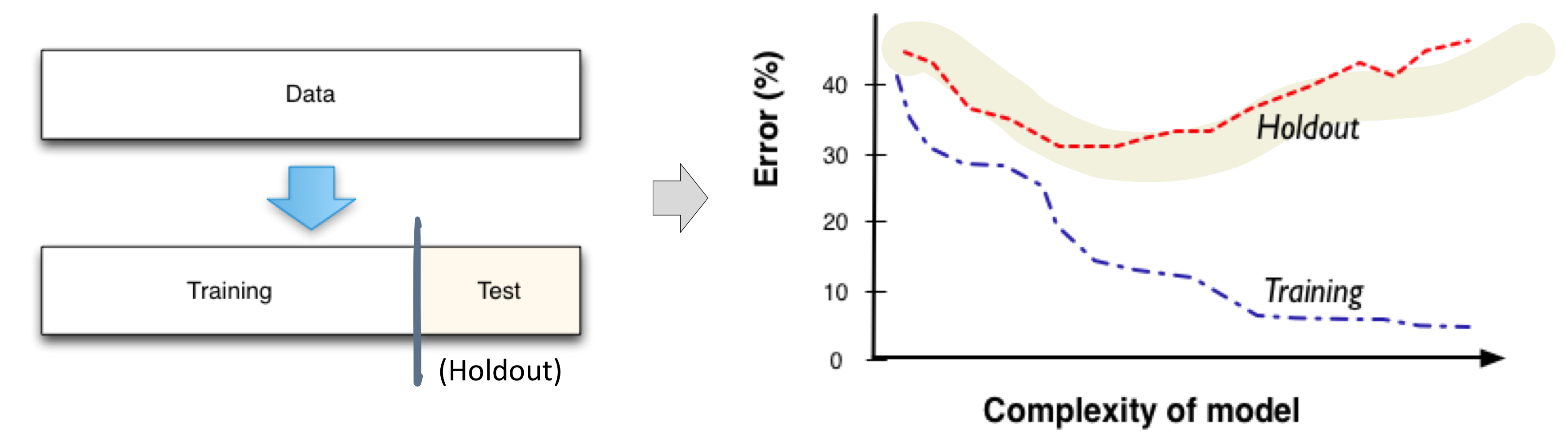
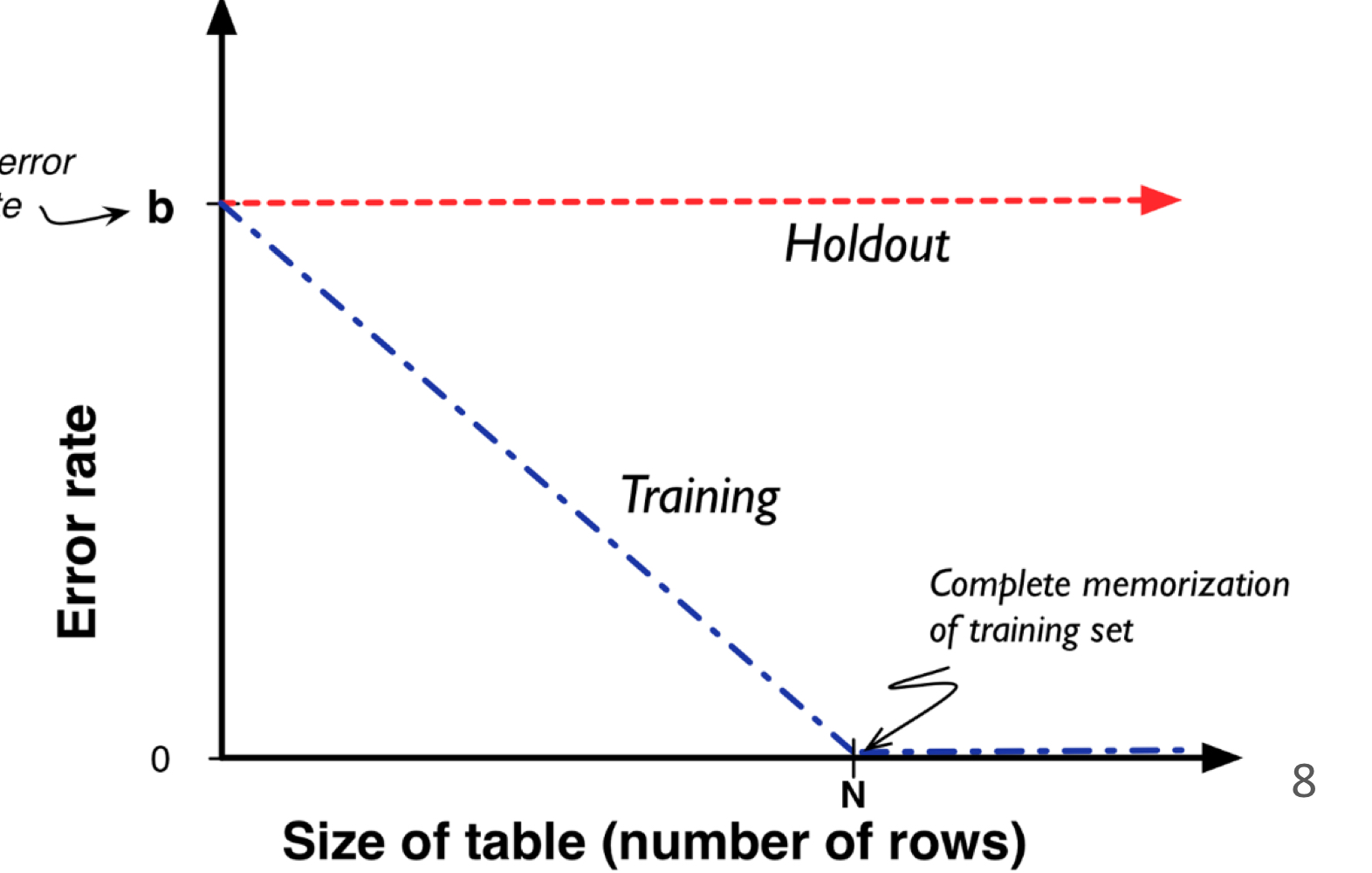
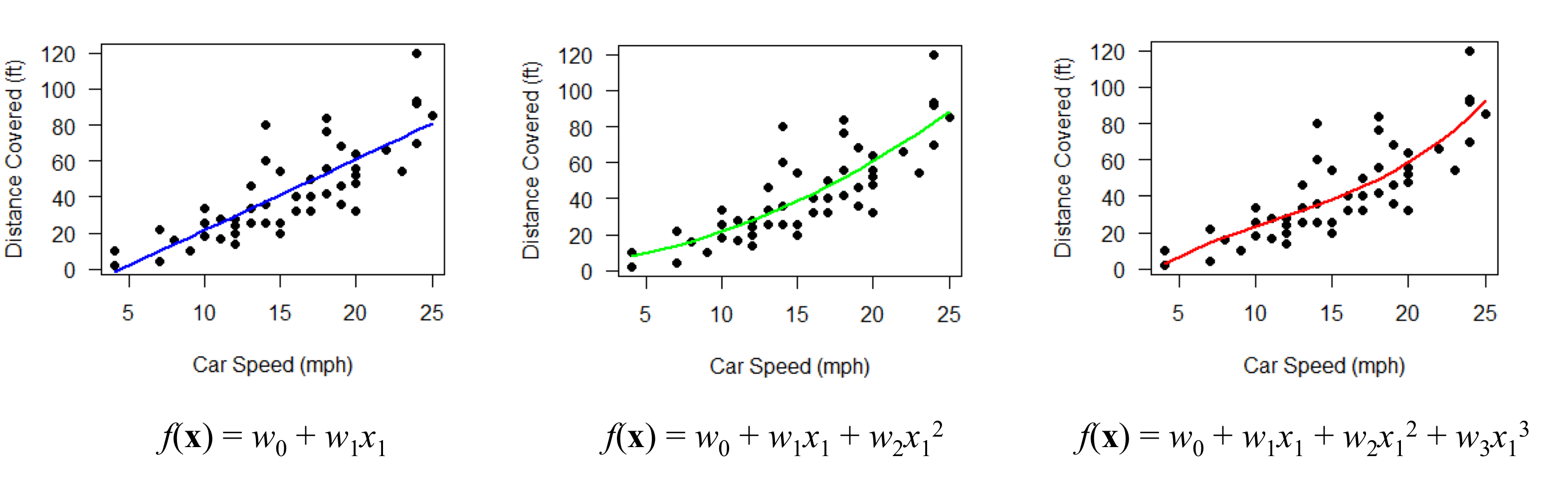
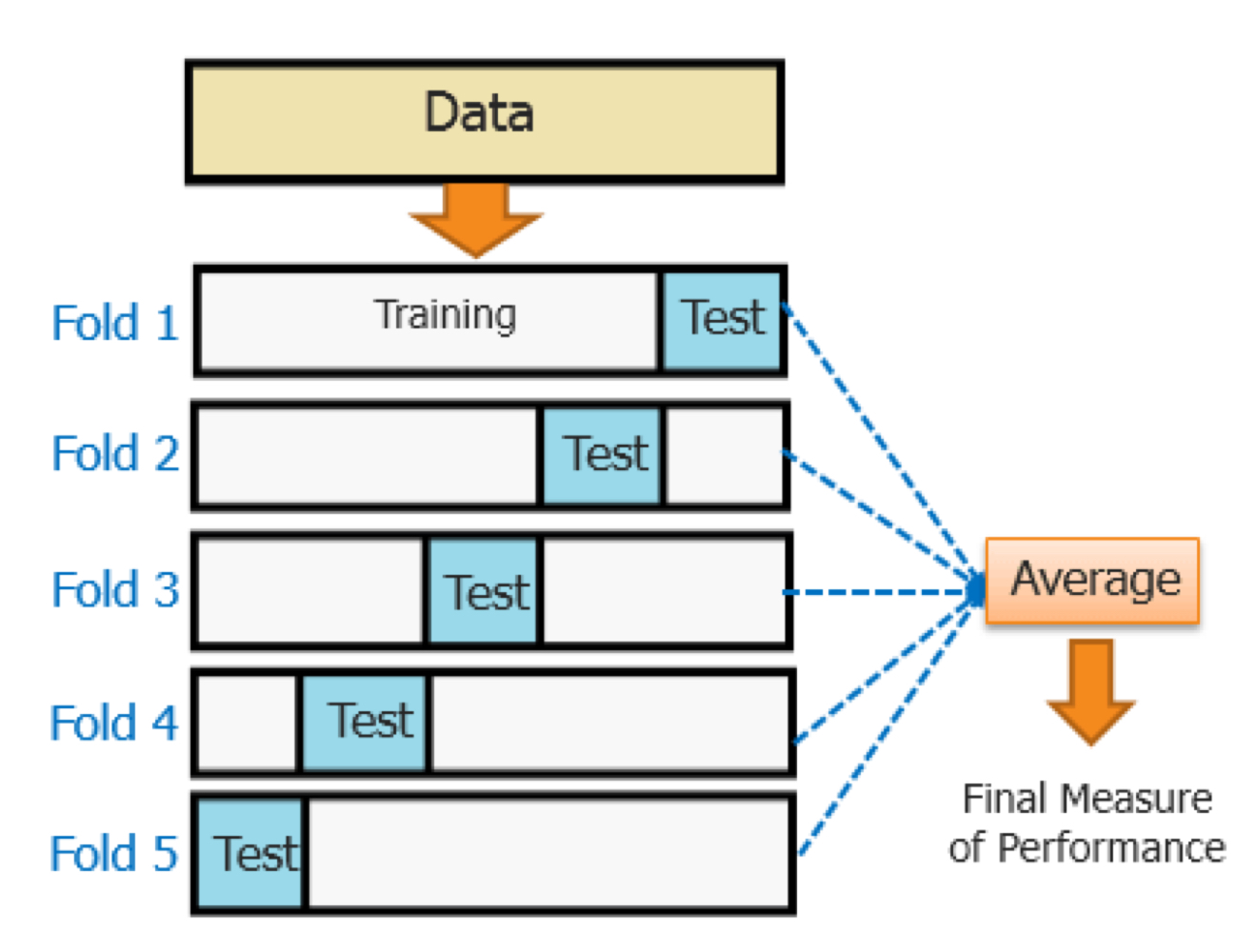
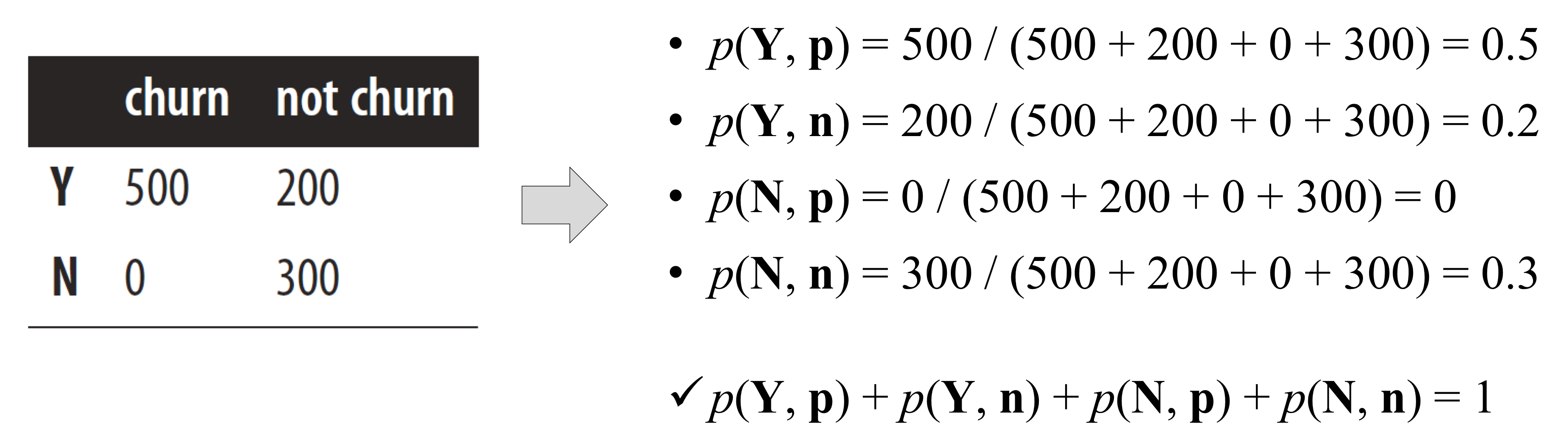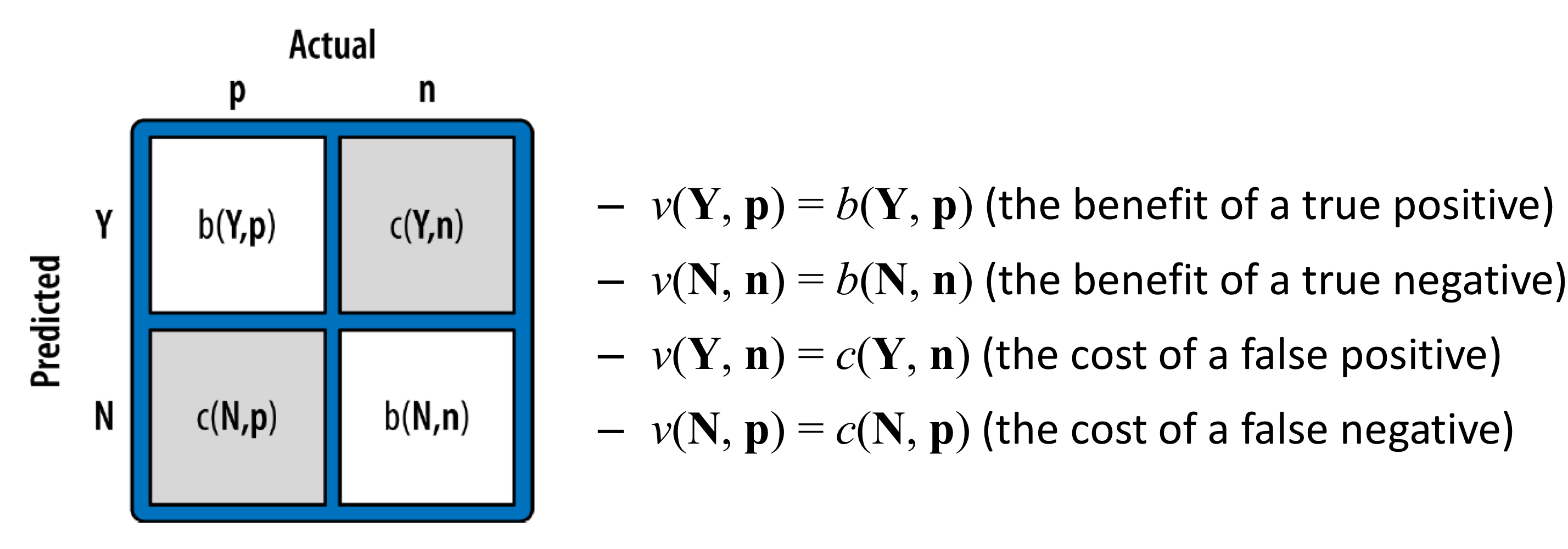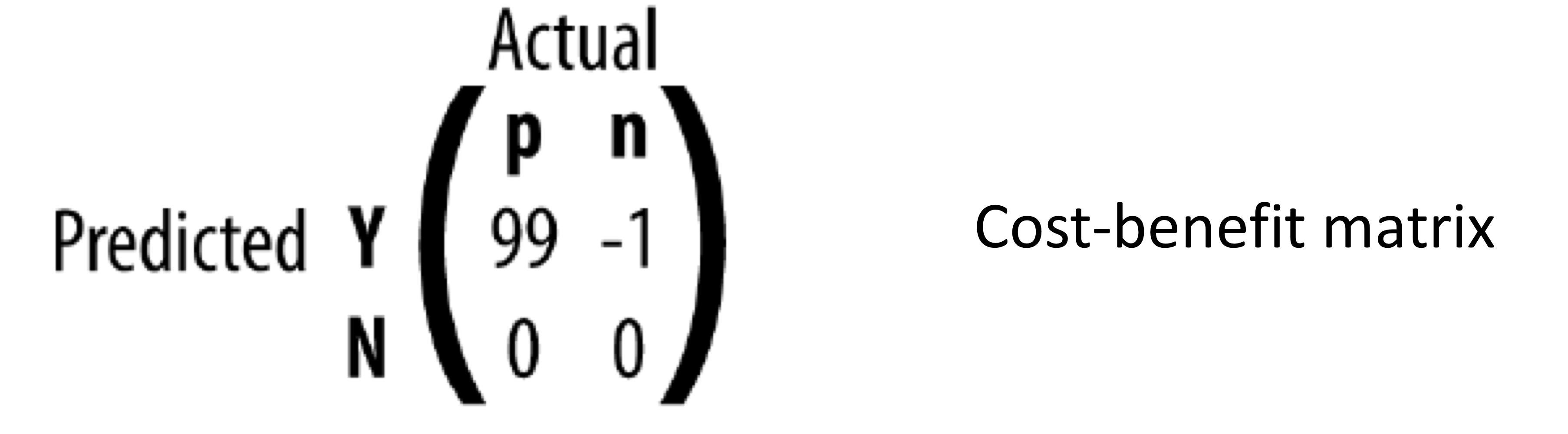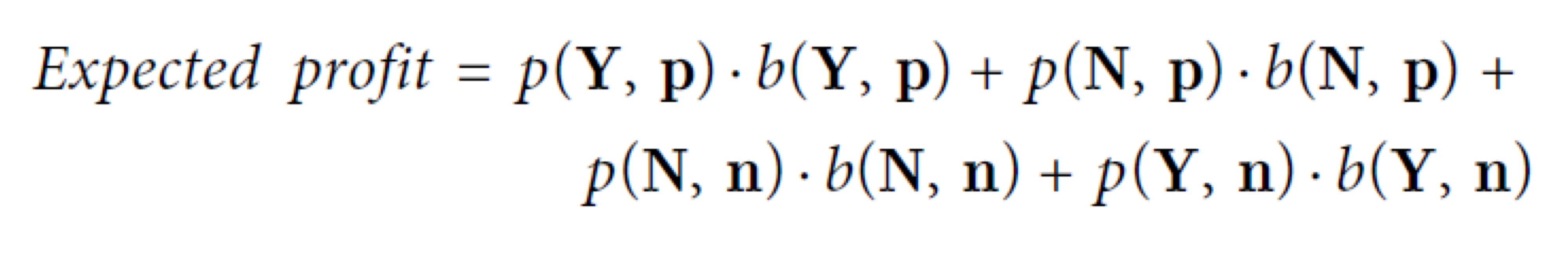수업 출처) 숙명여자대학교 소프트웨어학부 박동철 교수님 '데이터사이언스개론' 수업
1. Evidence-Based Classification
- 지금까지 분류를 위한 여러 방법을 알아보았다.
- 이제 분류의 다른 방법을 알아볼 것이다.
- Evidence
- 실제 일어난 것들. 실제 data 값들. (data instance의 feature values)
- data의 각각의 feature vector를 타겟 값에 대한 증거 (evidence)로 생각할 수 있다.

- 각 feature에 의해 주어진 증거의 강점을 안다면, 그것들을 확률적으로 결합하여 개체를 분류할 수 있다.
- 훈련 데이터로부터 각 증거의 강도를 알 수 있다.
2. (ex) online targeting advertising
- 고객들이 과거에 방문한 웹페이지를 기반으로 온라인 타겟 광고를 한다고 생각해보자.
- 웹페이지의 상단, 사이드, 하단에 광고를 띄우려고 한다.
- 화면 광고의 특징
- 검색 결과를 바탕으로 나타나는 검색 광고와는 다르다.
- 사용자들은 어느 키워드도 입력하지 않는다.
- 그러므로 우리는 사용자의 feature values를 기반으로 사용자가 특정 광고에 관심이 있는지 없는지 유추할 필요가 있다.
- 광고 타겟팅 문제를 더욱 정확하게 정의내려보자.
- 네이버나 페이스북과 같은 매우 큰 컨텐츠 제공자와 일하고 있다고 가정해보자.
- 다양한 컨텐츠, 많은 온라인 고객들을 보유하고 있다.
- 우리 웹사이트를 방문하는 고객들의 몇몇 부분집합을 타겟으로 하고자 한다.
- 이 광고 캠페인은 호텔을 광고하기 위해서 진행된다. 사람들이 호텔 방을 예약하도록 하는 것이 목표이다.
- 훈련 데이터를 얻기 위해서 우리는 온라인 고객들을 랜덤으로 선택하여 이 캠페인을 과거에 진행했다.
- 이제 우리가 원하는 것은 '타겟 고객을 대상으로' 광고 캠페인을 진행하는 것이다.
- 그를 통해 광고에 사용하는 비용 대비 많은 예약자를 얻고자 하는 것이다.
- 광고 타겟팅 문제를 어떻게 정의할 수 있을까?
- instance는 무엇이 될까
- 타겟 변수는 무엇이 될까
- 특성들은 무엇이 될까
- 훈련 데이터는 얼마나 모아야 할까
- 어떤 분류 모델을 이용해야 할까
- 다음과 같이 정의하고자 한다.
- instance : 고객
- target variable : 그 고객이 이 호텔 광고를 본 뒤 일주일 내에 예약을 한 적이 있거나 할 예정인가?
- features : key question! 이후에 다룰 예정
- training data : 타겟 변수에 대한 이진값 (Y / N)
- classification model : 광고를 본 후 방을 예약할 고객의 확률을 추정하기 위해 Naive Bayes classifier을 사용할 것이다.
- key question) 고객을 묘사하기 위해 어떤 특징 (features)을 활용해야 할까?
- 어떤 attribute가 필요할까
- 호텔에게 좋은 고객이 될 가능성이 높은 고객과 낮은 고객들을 차별화할 수 있도록 해야 한다.
- 이 예제에서 (호텔)는 고객이 이전에 방문했던, 혹은 좋아요를 눌렀던 컨텐츠들의 집합을 feature로 활용할 것이다.
- ex) Jessie = {www.sookmyung.ac.kr, "Avengers: Endgame", ...}
- 브라우저 쿠키나 다른 메커니즘을 통해 기록된 것을 이용할 것이다.
- 각 증거(컨텐츠 조각들)의 강도와 방향을 추정하기 위해 과거 데이터를 활용할 것이다.
- 그리고 클래스 멤버십의 가능성을 추정하기 위해 그것들을 결합할 것이다.
- 이 예제의 framework와 잘 맞는 여러 다른 문제들이 있다.
- 각 개체는 증거들의 집합으로 묘사된다.
- 우리는 개체를 분류하기 위해서 각 증거 조각의 강도를 결합해야 한다.
- ex) spam detection
- 각 메일은 단어들의 집합으로 구성되어 있다.
- 각 단어들이 이 메일이 스팸인지 아닌지 구분하는 증거가 된다.
- 메일을 분류하기 위해 증거들을 확률적으로 결합할 것이다.
- problem definition
- instance : an email message
- target classes : spam or not-spam
- features : the words (and symbols) in the email message
3. Combining Evidendce Probabilistically
- 우리는 고객이 광고를 본 후 호텔 룸을 예약할 확률을 알고싶다.
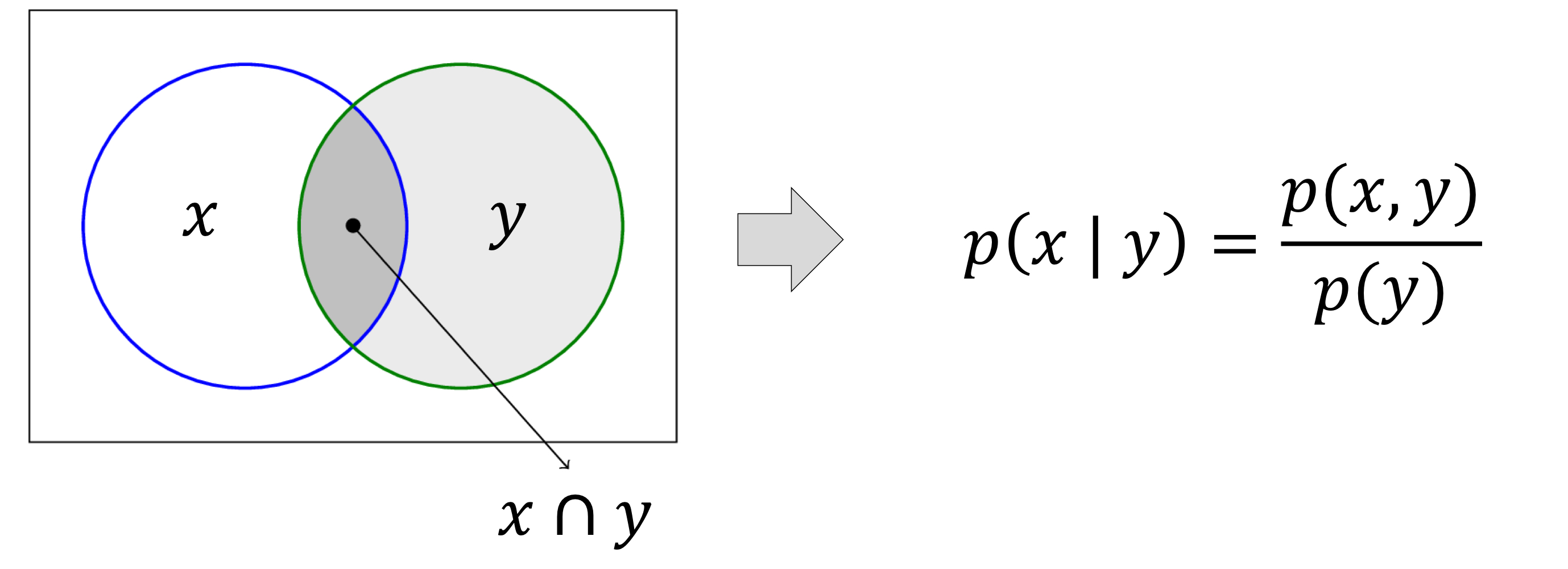
- 사건이 일어날 확률을 p(C)라고 하면, 우리는 조건부 확률인 p(C | E)에 관심을 가져야 한다.
- E = {e1, e2, ..., ek} : 고객이 방문한 웹사이트들의 집합
- C : 고객이 룸을 예약하는 사건
- E가 달라질 때마다 p(C | E)도 달라질 것이다. 즉, 서로 다른 웹사이트를 방문한 고객들은 서로 다른 행동을 보일 것이다.
- 훈련 데이터를 통해서 p(C | E)를 유추할 수 있다.
- 하지만, 중요한 문제가 있다. 훈련 데이터에서 정확히 똑같은 집합의 증거를 가진 개체 (k개의 웹사이트를 똑같이 방문한 사람) 는 거의 없을 것이다.
- 따라서 증거를 하나씩 분리해서 고려한 후에 다시 합쳐야 한다.
- 즉, E = {e1, e2, ..., ek} 일 때, e1, e2, ..., ek를 각자 분리해서 계산한다는 뜻이다.
4. Joint Probability
- Notations
- A, B : 두 사건
- p(A), p(B) : A와 B가 각각 일어날 확률
- p(AB) : 두 사건이 동시에 일어날 확률 -> joint probability
- 두 사건 A, B가 독립인 경우 p(AB) = p(A) · p(B)
- 독립이 아닌 경우 p(AB) = p(A) · p(B | A)
5. Bayes' Rule
- p(AB) = p(A) · p(B | A) = p(B) · P(A | B)
==> p(B | A) = {p(A | B) · p(B)} / p(A)
- A와 B를 각각 E, H라고 하자.
- H : 가능성을 평가하고자 하는 어떠한 가설
- E : 우리가 관찰할 수 있는 증거
==> p(H | E) = {p(E | H) · p(H)} / p(E)
- 이것이 베이즈 정리이다.
- p(H | E)를 구할 때 p(E | H)를 대신 살펴봄으로써 증거 E가 주어졌을 때 가설 H의 확률을 계산할 수 있다.
- 즉, p(E | H), p(H), p(E)를 통해서 p(H | E)를 구할 수 있다는 장점이 있다.
6. Importance of Bayes' Rule
- p(E | H), p(H), p(E)가 p(H | E)보다 결정하기 쉽다.
- ex) medical diagnosis
- 예를 들어, 내가 의사이고 빨간 반점을 가진 환자가 찾아왔다고 가정해보자.
- 나는 환자가 홍역을 갖고 있다고 추측할 수 있다.
- H를 '홍역', E를 '붉은 반점'이라고 할 때, p(H | E)를 구해야 한다.
- 하지만 p(H | E)를 바로 구하는 것은 거의 불가능하다.
- 왜냐하면 그 확률을 구하려면 한 사람에게 붉은 반점이 나타날 수 있는 모든 사례들과 그 중 홍역일 비율을 생각해야 하기 때문이다.
- 하지만, 대신 p(E | H), p(H), p(E)를 구해본다면,
- p(E | H) : 홍역일 때 붉은 반점이 생길 확률
- p(H) : 어떤 사람이 홍역에 걸릴 확률
- p(E) : 어떤 사람에게 붉은 반점이 생길 확률
- 이 확률들은 전문가로부터 이미 알려져 있거나 직접 구할 수 있다.
- 따라서 베이즈 정리를 통해서 p(H | E)를 더욱 쉽게 구할 수 있다.
7. Applying Bayes' Rule to Classification
- 데이터 사이언스의 많은 부분이 베이지안 방법에 기반을 두고 있다.
- 그들의 핵심 논리가 베이지 정리에 근거한 것이다.
- p(C = c | E) = {p(E | C = c) · p(C = c)} / p(E)
- C = c : 타겟 변수값이 c인 사건 (ex: C = 'YES' or C = 'NO')
- E : 증거 (the vector of feature values)
- p(C = c | E) : 증거가 E일 때 C = c일 확률. 우리가 구하고 싶은 값이며 '사후확률 (posterior probability)'라고 부른다.
- p(C = c) : 클래스 c의 사전확률. 모든 예시들 중 class가 c일 확률
- p(E | C = c) : 클래스 C = c일 때 증거가 E일 확률. feature vector가 E인 클래스 c의 비율
- p(E) : E일 가능성. 모든 예시들 중 E가 발생할 확률
- 아래 세 가지 확률은 데이터로부터 쉽게 구할 수 있다.
- 사후확률 p(C = c | E)
- 클래스 확률의 추정치로 바로 사용할 수 있다.
- 개체들의 순위를 매기기 위한 점수로 사용할 수 있다.
- 또는, 분류할 때 서로 다른 c값에 대해 p(C = c | E)의 최댓값을 선택할 수 있다.
- ex) p(C = 'YES' | E) = 0.7, p(C = 'NO' | E) = 0.3 -> determine C = 'YES'
- ex) spam detection
- w1, ..., wn : 메일 속 단어들
- p(Spam | w1, ..., wn) = {p(w1, ..., wn | Spam) · p(Spam)} / p(w1, ..., wn)
8. Major Difficulty in Computing p(C = c | E)
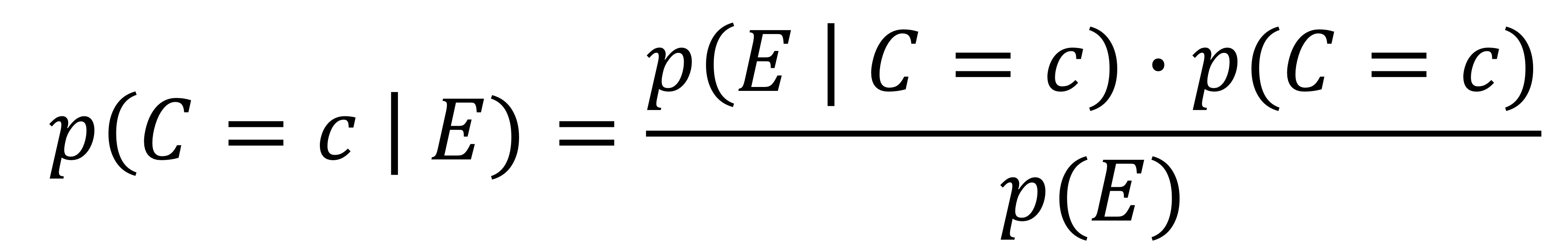
- E = {e1, e2, ..., ek}
- E는 충분히 크고, 구체적인 조건들의 집합이다.
- p(E | C = c) = p(e1, e2, ..., ek | C = c)
- 하지만 p(e1, e2, ..., ek | C = c)를 구하는 것은 어렵다.
- 훈련 데이터에서 증거가 주어진 E = {e1, e2, ..., ek}와 완전히 일치하는 특정 개체를 절대 볼 수 없을지도 모른다.
- 만약 존재한다고 하더라도 확신을 가지고 확률을 추정할만큼 충분히 있진 않을 것이다.
9. Conditional Independence
- p(AB | C) = p(A | C) · p(B | AC) = p(B | C) · p(A | BC)
- C가 일어날 때 A와 B는 독립적이지 않다.
- 하지만, C가 일어날 때 조건적으로 A와 B가 독립이라면
- p(AB | C) = p(A | C) · p(B | C) = p(B | C) · p(A | C)
- 이 경우가 더 확률을 계산하기 쉽다.
- 따라서 데이터사이언스의 베이지안 방법에서는 '조건부 독립'을 강하게 가정함으로써 이 문제를 다룬다.
- p(E | c) = p(e1 ^ e2 ^ ... ^ ek | C) = p(e1 | C) · p(e2 | C) · ... · p(ek | C)
- 클래스 c가 주어졌을 때, eᵢ를 다른 eⱼ와 독립적이라고 가정한다.
- 간단히 표현하기 위해서 C = c 를 c라고 표현하겠다.
- 각 p(eᵢ | c) 는 데이터로부터 바로 계산될 수 있다.
- 모두 맞는 feature vector를 찾을 필요가 없다.
- 단순히 클래스 c의 개체에서 각 feature eᵢ를 찾은 비율을 계산하면 된다.
- 그러면 증거를 한 번에 비교하는 것보다 상대적으로 eᵢ가 많이 발생할 수 있다.
10. Naive Bayes Classifier
- 이 전의 식과 베이즈 정리를 결합하면 다음과 같이 '나이브 베이즈 방정식 (Naive Bayes equation)'이 나온다. 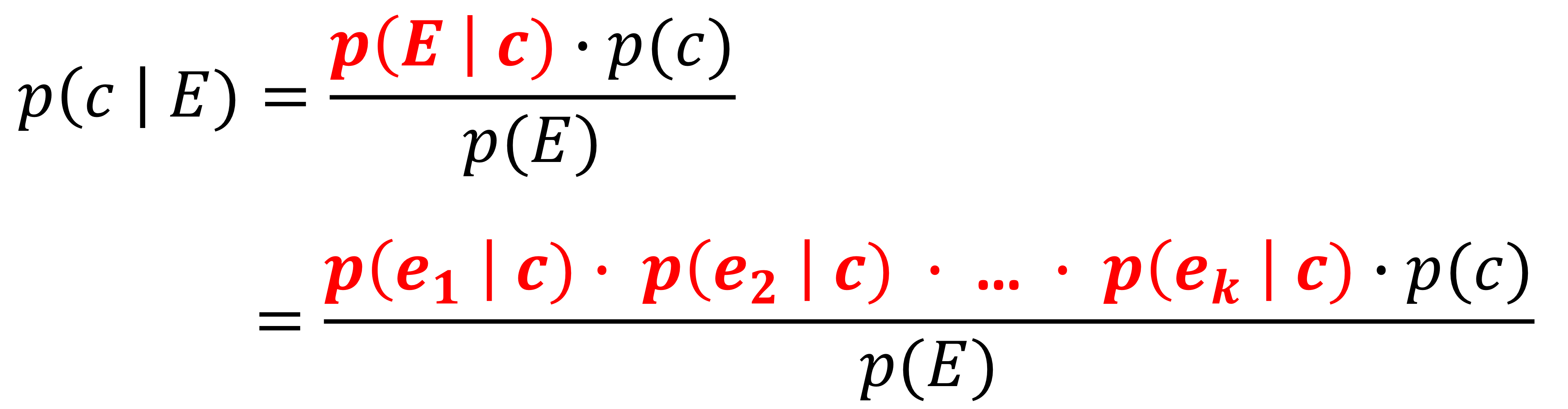
- 베이즈 방정식을 활용하여 표본이 각 클래스에 속할 확률을 추정하는 방식이다.
- 더 높은 확률을 갖는 클래스를 반환한다.
- 예를 들어, Y에 속할 확률이 30%라고 치면, N에 속할 확률은 70%가 아니라 따로 또 계산을 해줘야 한다.
만약 N에 속할 확률이 45%라면 Y에 속할 확률보다 크기 때문에 N으로 분류한다.
- 우리는 분류에만 관심이 있기 때문에 정확한 값보다는 어떤 클래스에 속할 확률이 더 큰지가 더 중요하다.
- 따라서 실제로는 분모의 p(E)는 모든 클래스에 대해 똑같기 때문에 생략하고, 분자만 계산한다.
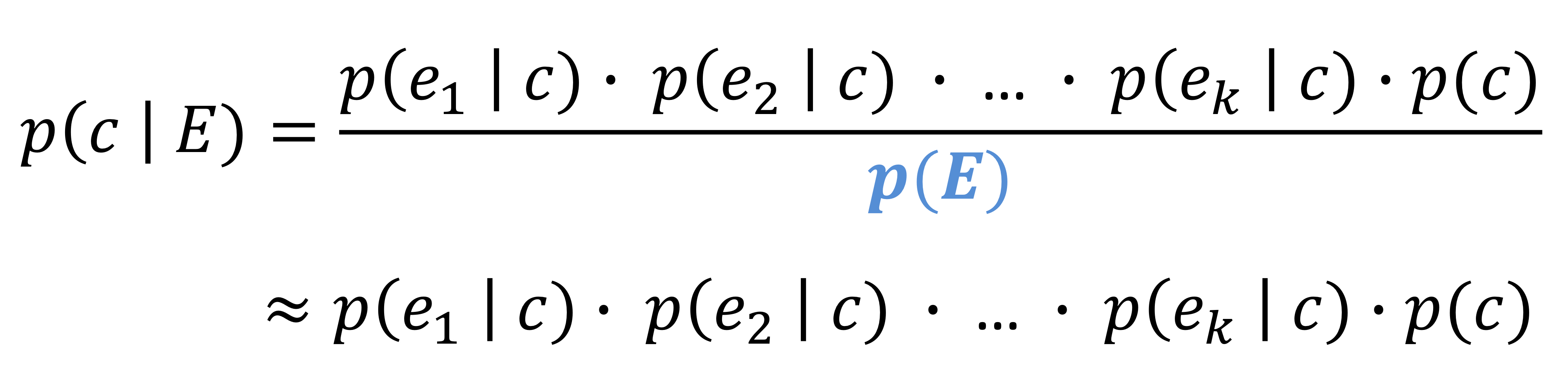
11. Advantage of Naive Bayes
- 매우 간단한 classifier이다.
- 그럼에도 불구하고 모든 특징 증거들을 고려한다.
- 저장공간과 실행시간에 대해 매우 효율적이다.
- 오직 p(c)와 p(eᵢ | c)만 저장하고, 몇몇의 간단한 곱셈만 수행하기 때문이다.
- 단순함과 강한 독립성 가정에도 불구하고 많은 실생활 문제들에서 놀라울 정도로 잘 수행된다.
- 독립이 아닌 사건들에도 적용할 수 있다. 독립성 가정의 위반은 분류 성능을 낮추지 않는 경향이 있다.
- 두 증거가 사실 독립적이지 않은데 독립적으로 다뤘다면 증거들의 double counting 문제가 생긴다.
- (ex) p(AB) = p(A) · p(B | A) vs. p(AB) = p(A) · p(B)
- 이는 classifier 측면에서는 별로 영향을 미치지 않는다. 단순히 확률이 과대평가될 가능성이 있다.
- 따라서 독립적이지 않은 evidence들이 많기 때문에 확률 추정치 자체가 정확하다고 볼 수는 없다.
- 그렇기 때문에 실무자들은 확률의 실제값과는 관련이 없는, 단지 순위를 매기기 위해 Naive Bayes를 사용한다.
- 자연스럽게 점증적으로 학습한다. (incremental learner)
- 한 번에 한 가지 훈련 사례를 모델에 업데이트 할 수 있다.
- 새로운 훈련 데이터가 들어올 때 과거의 모든 훈련 데이터들을 재처리 할 필요가 없다.
- 특히 새로운 라벨링 데이터가 들어올 때마다 모델을 업데이트하고자 하는 애플리케이션에 유리하다.
- ex) creating a personalized spam email classifier
- 사용자가 웹브라우저에서 '스팸'버튼을 클릭할 때 새로운 라벨링된 데이터가 들어온다. 그를 통해서 스팸 탐지 모델을 업데이트할 수 있다.
12. (ex) Weather Forecast

- 위와 같이 날씨에 따른 골프 가능 여부 데이터셋이 있다.
- 그럼 아래 사례의 클래스는 어떻게 예측할 수 있을까?

- 우선 모든 필요한 확률들을 계산해야 한다.
p(C | E) ≈ p(e1 | c) · p(e2 | c) · ... · p(ek | c)
- p(c)

- p(eᵢ | c) for "outlook"
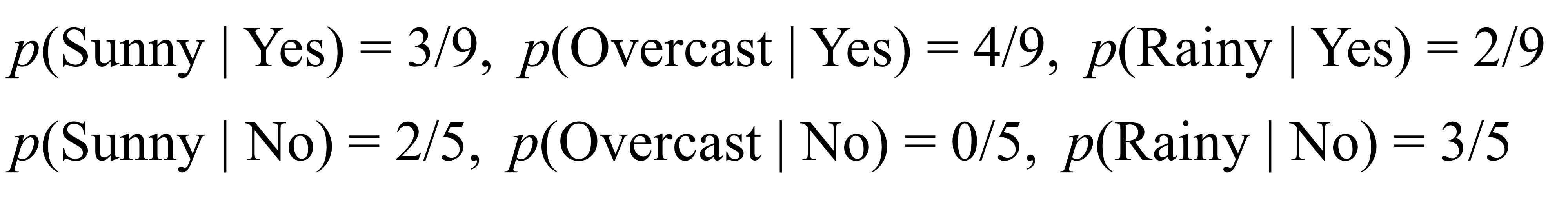
- p(eᵢ | c) for "temp"

- p(eᵢ | c) for "humidity"

- p(eᵢ | c) for "windy"

- compute p(c | E) for each class c
- p(Yes | rainy, cool, high, true) ≈ p(rainy | yes) · p(cool | yes) · p(high | yes) · p(true | yes) · p(yes) = 0.00529
- p(No | rainy, cool, high, true) ≈ p(rainy | no) · p(cool | no) · p(high | no) · p(true | no) · p(no) = 0.02057
- 정확한 확률값의 크기에 상관없이 Yes보다 No인 확률이 더 크기 때문에 play golf = No 로 결정된다.
13. (ex) Patient Diagnosis
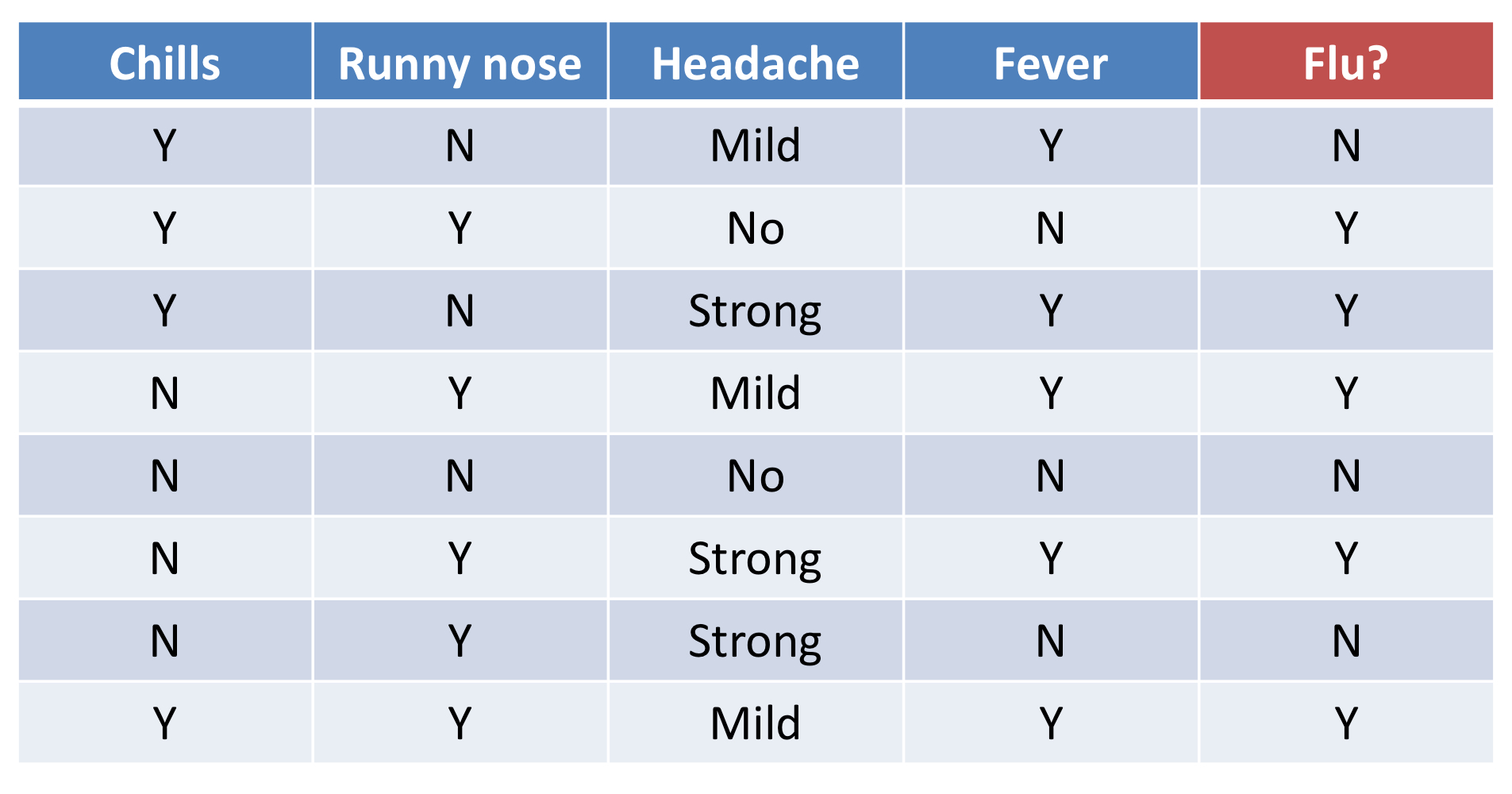

- 위의 예제와 같이 데이터셋을 통해서 flu 클래스를 예측해보고자 한다.
- p(c)

- p(eᵢ | c) for "chills"

- p(eᵢ | c) for "runny nose"

- p(eᵢ | c) for "headache"

- p(eᵢ | c) for "fever"

- compute p(c | E) for each class
- p(flu = Y | chills = Y, runny nose = N, headache = Mild, feaver = N) = 0.006
- p(flu = N | chills = Y, runny nose = N, headache = Mild, feaver = N) = 0.0185
- flu = N인 확률이 더 크기 때문에 Flu = N으로 결정된다.
14. (ex) Spam Detection


- p(c)
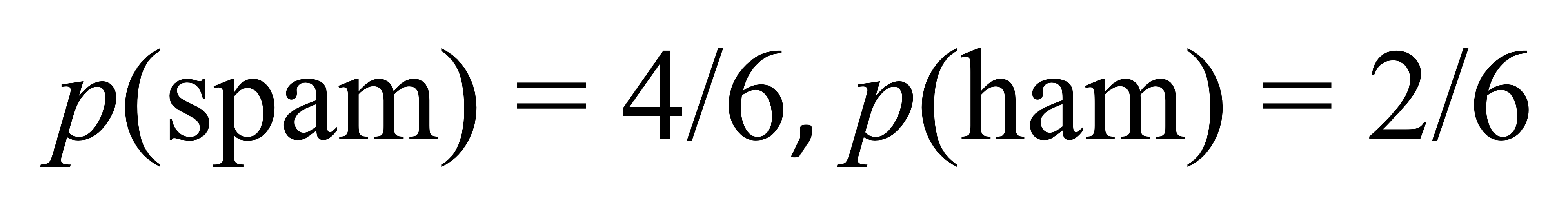
- p(eᵢ | c) for the word "password"

- p(eᵢ | c) for the word "review"

- p(eᵢ | c) for the word "send"
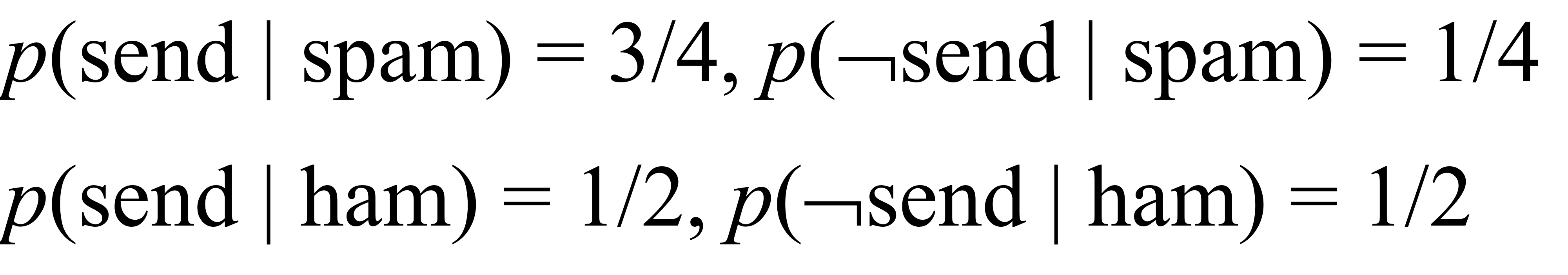
- p(eᵢ | c) for the word "us"

- p(eᵢ | c) for the word "your"

- p(eᵢ | c) for the word "account"

- compute p(c | E) for each class c
- p(spam | ¬password, review, ¬send, ¬us, your, account) = 0.000976
- p(ham | ¬password, review, ¬send, ¬us, your, account) = 0
- spam 일 확률이 더 크기 때문에 spam으로 결정된다.
15. A Model of Evidence "Lift"
- 전체 모집단에 대해 선택된 하위 모집단에서 positive class가 얼마나 더 만연한지 측정하는 classifier 평가지표이다.
- 즉, Lift = positive / sampling (targeting)
- evidence lifts의 하나로 Naive Bayes를 생각해볼 수 있다.


- 변환한 식에서 p(eᵢ | c) / p(eᵢ) 가 클래스 c의 evidence lift이다.

- evidence lift는 eᵢ가 클래스 c를 얼마나 더 lift 시키는지, 클래스 c와 얼마나 연관성이 있는지, eᵢ가 이 개체를 클래스 c로 분류하는데 얼마나 도움이 되는지를 나타내는 지표이다.

- 사전확률 p(c)에서부터 시작하여 예시 E를 살펴볼 것이다.
- 각각의 증거 eᵢ는 클래스에 대한 확률을 높이거나 낮춘다.
- 만약 liftc(eᵢ) > 1 이라면 확률은 증가할 것이고, liftc(eᵢ) < 1이라면 확률은 감소할 것이다.
16. (ex) Evidence Lifts from facebook 'likes'
- 최근 연구자들은 페이스북의 '좋아요'가 보통 직접적으로 드러나지 않는 사람들의 특징들을 꽤 예측한다는 논문을 발표했다.
- 지식 수준이 어떤지, 정신적인 상태는 어떤지, 이미 밝힌 동성애자인지, 술을 마시거나 담배를 피는지, 종교나 정치적 견해는 어떤지 등 말이다.

- 어떤 사람이 좋아요를 누른 기록과 각각 "High IQ"에 대한 evidence lifts이다.
- "Sheldon Cooper"에 좋아요를 눌렀다는건 일반적인 사람들보다 '높은 IQ'를 갖고 있을 확률이 30% 더 높다는 의미이다.
- 마찬가지로 "Lord of the rings"에 좋아요를 눌렀다는건 일반적인 사람들보다 '높은 IQ'를 가지고 있을 확률이 69% 높다는 의미이다.
- 일반적으로 페이스북 인구에서 타겟 변수를 'IQ > 130'으로 잡으면, 약 14%의 사람들이 Yes 클래스에 해당한다는 가설이 있다.
- 그러면 아무것도 좋아요를 누르지 않은 경우엔 'IQ > 130'일 확률 추정치는 기본 비율인 14%이다.
- 만약 "Sheldon Cooper"에 좋아요를 눌렀다면, 확률 추정치는 0.14 x 1.3 = 18% 로 30% 증가된 값이 된다.
- 만약 (Sheldon Cooper, Star Trek, Lord of the Rings) 세 개에 좋아요를 눌렀다면, 확률 추정치는 0.14 x 1.3 x 1.39 x 1.69 = 43%가 된다.
- 이처럼 evidence lift를 통해서 행동 특성을 예측할 수 있다.
'Software > Data Science Introduction' 카테고리의 다른 글
| [데이터사이언스개론] Representing and Mining Text (2) | 2021.06.10 |
|---|---|
| [데이터사이언스개론] Visualizing Model Performance (0) | 2021.06.09 |
| [데이터사이언스개론] What is a good model? (0) | 2021.06.08 |
| [데이터사이언스개론] Similarity, Neighbors, Clusters (0) | 2021.06.04 |
| [데이터사이언스개론] Overfitting and Avoidance (0) | 2021.04.22 |