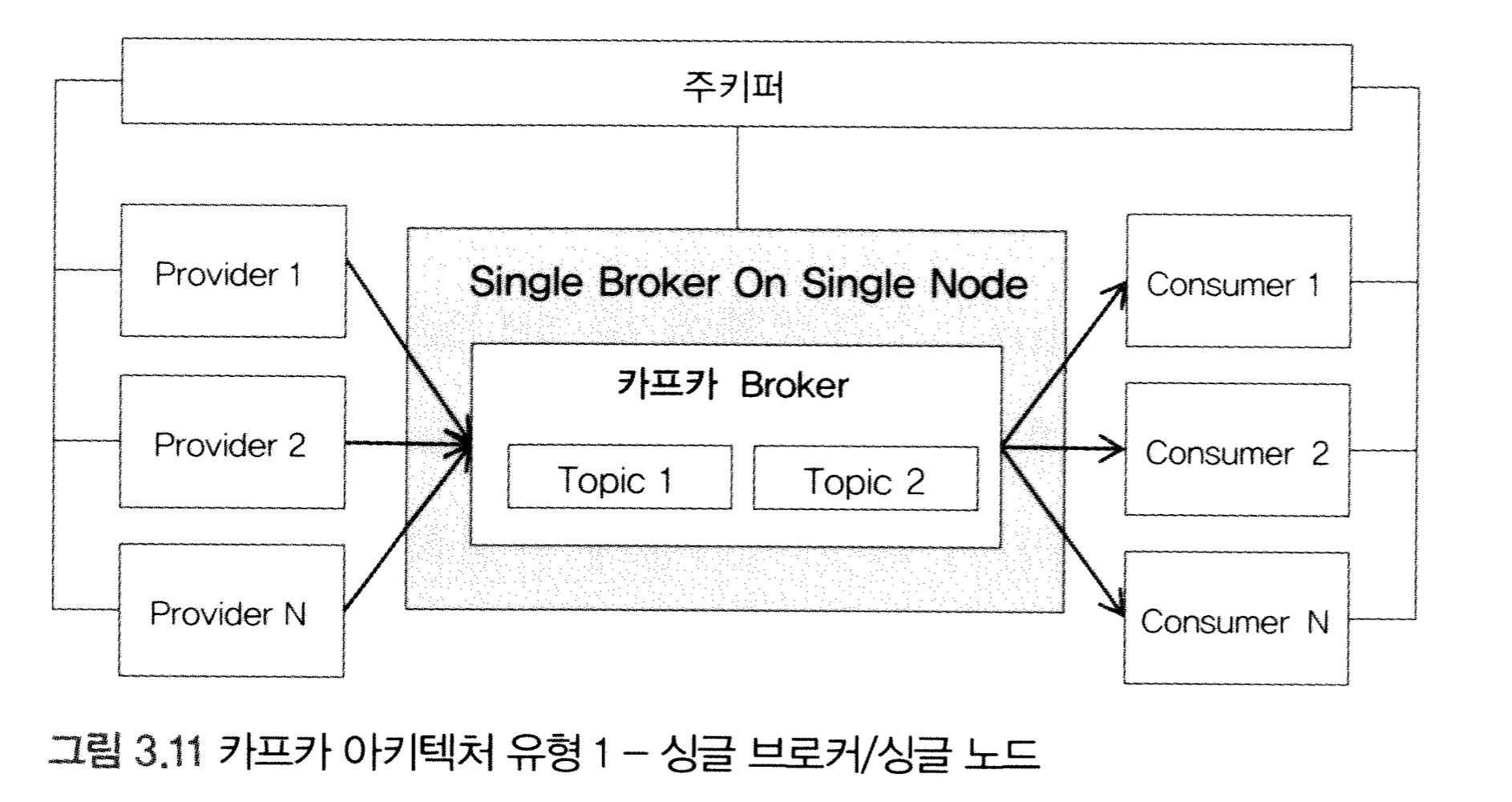
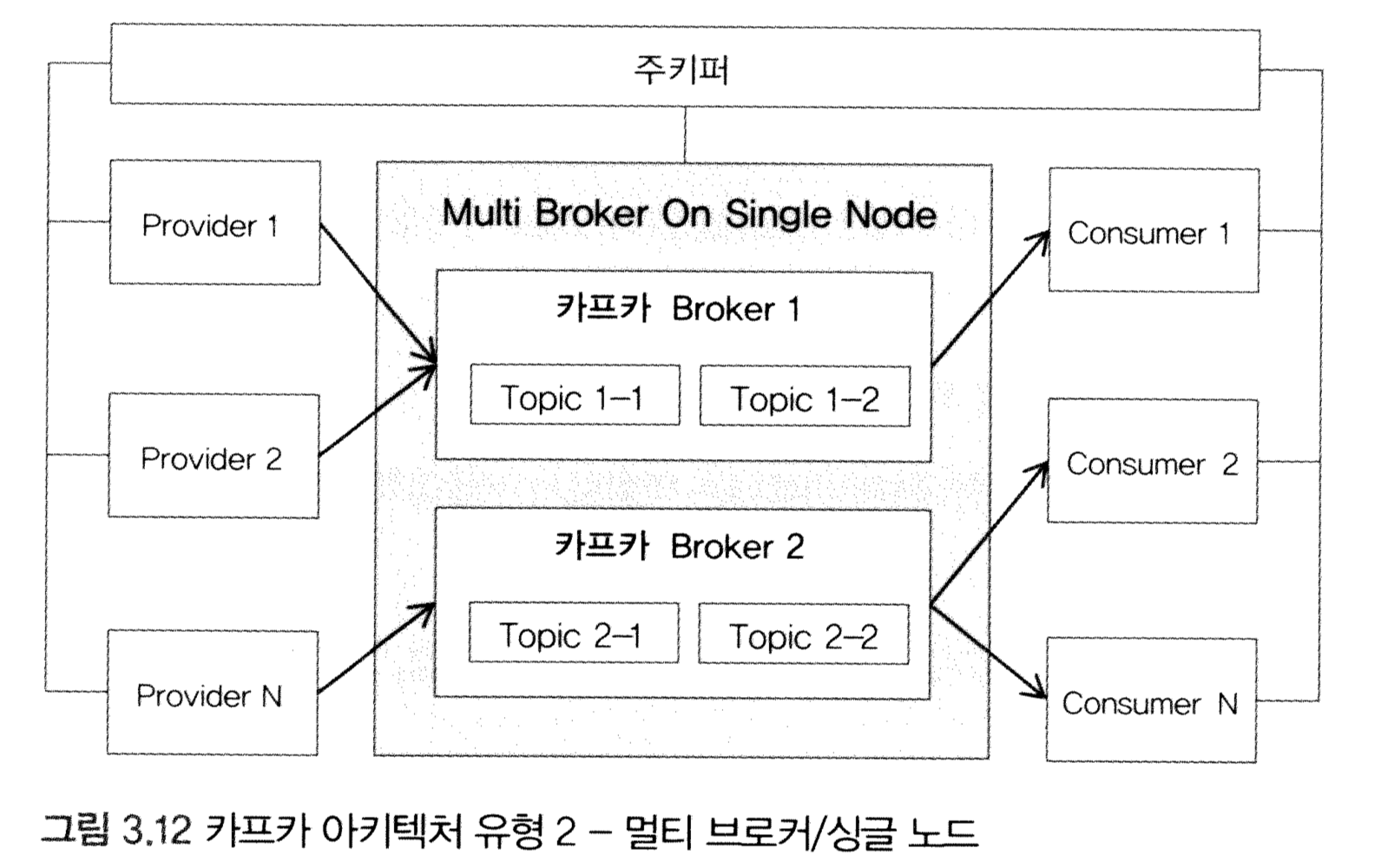
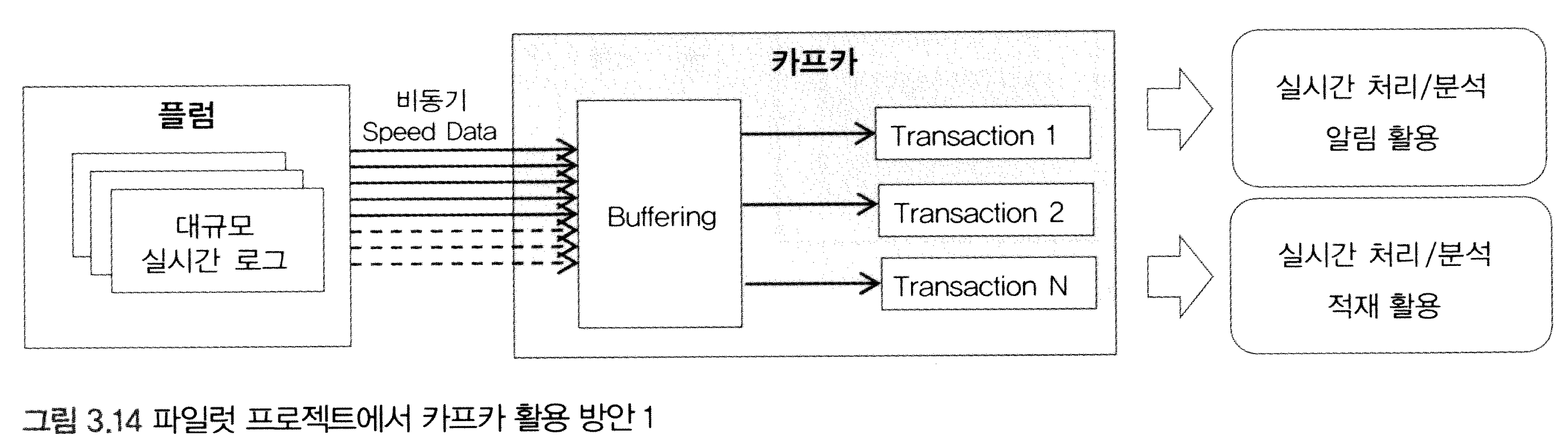
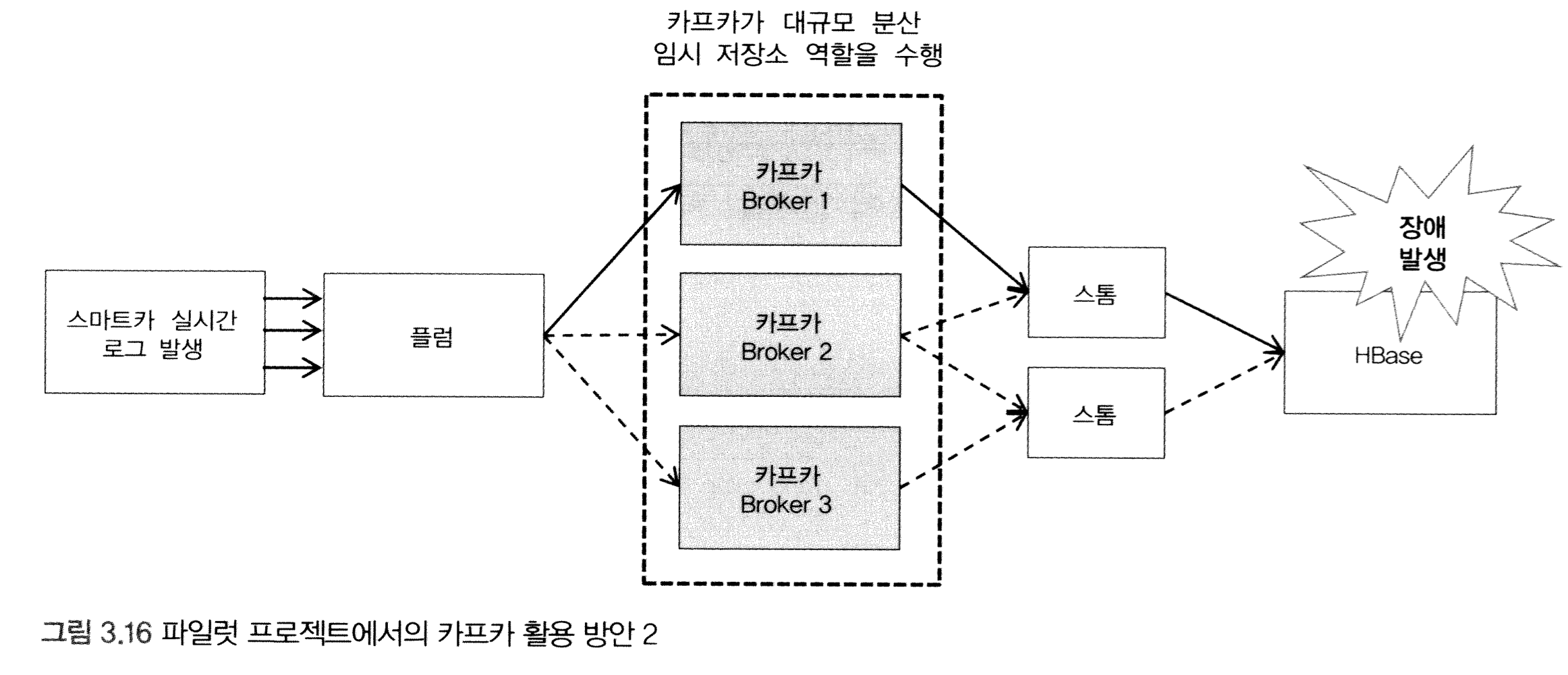
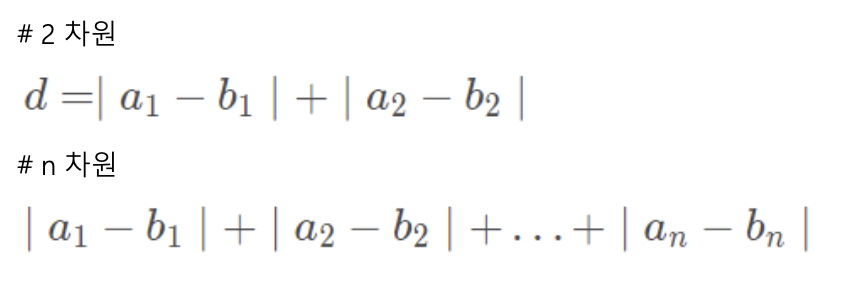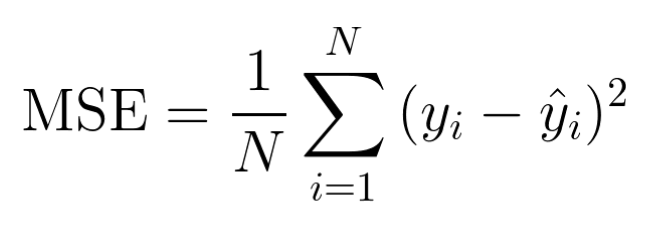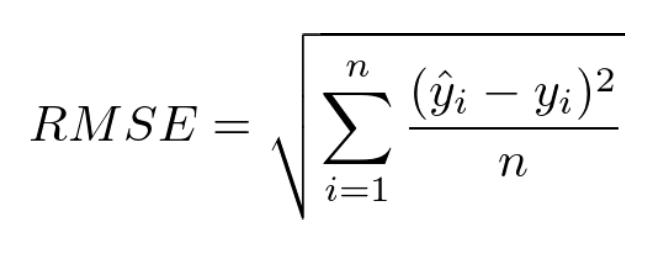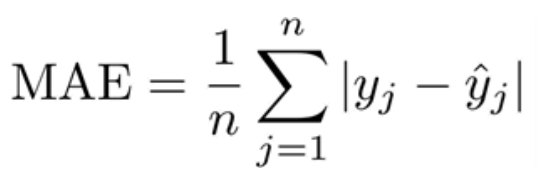import java.util.Scanner;
public class J1085 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int x = sc.nextInt();
int y = sc.nextInt();
int w = sc.nextInt();
int h = sc.nextInt();
int left = x;
int right = w-x;
int up = h-y;
int down = y;
int[] arr = {left, right, up, down};
int min = arr[0];
for(int num : arr) {
if(num < min) {
min = num;
}
}
System.out.print(min);
}
}
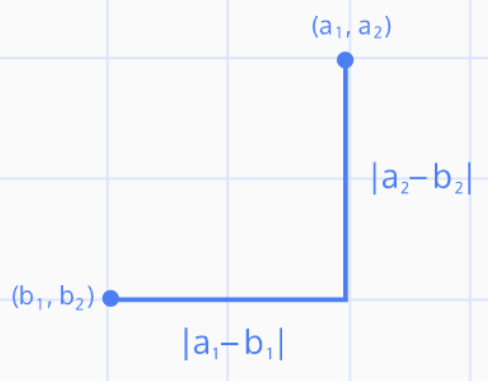
- 독립변수 x에 대응하는 종속변수 y와 가장 유사한 값을 갖는 함수 f(x)를 찾는 과정
→ f(x)를 통해 미래 사건 예측
^y = f(x) ≈ y
- 회귀 분석을 통해 구한 함수 f(x)가 선형 함수일 때 f(x) = 회귀 직선
- 선형 회귀 분석
- 특성과 타겟 사이의 관계를 잘 나타내는 선형 회귀 모형을 찾고, 이들의 상관관계는 가중치/계수(m), 편향(b)에 저장됨
=> ^y = w * x + b
2. 비용 함수 = 손실 함수
- 선형 모델의 예측과 훈련 데이터 사이의 거리를 재는 함수
- 비용 함수의 결과값이 작을수록 선형 모델의 예측이 정확함
- 선형 회귀는 선형 모델이라는 가설을 세우는 방식이므로, 실제 데이터(훈련 데이터)와 선형 모델의 예측 사이에 차이 존재
- 실제 데이터와 선형 모델의 예측 사이의 차이를 평가하는 함수 → 비용 함수를 사용하여 정확도 계산
- MSE 가장 많이 사용 [실제값과 예측값의 차이인 오차들의 제곱의 평균]
3. 선형 회귀 구현
1) 선형 회귀 모델 구현
# 훈련 세트, 테스트 세트 생성
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight, random_stae = 42)
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
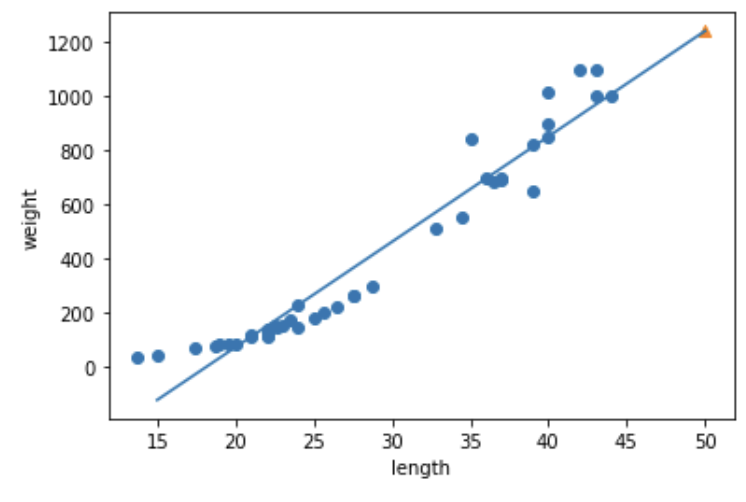
# 50cm 농어 평균 무게 예측
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_input, train_target)
print(lr.predict([50]))
# 1241.83860323
2) 회귀 확인
# 회귀 직선 ^y = W * x + b 구하기
print(lr.coef_, lr.intercept_)
# [39.01714496], -709.0186449535477
# => y = lr.coef_ * x + lr.intercept_
plt.plot([15, 50], [15*lr.coef_+lr.intercept_, 50*lr.coef_+lr.intercept_])
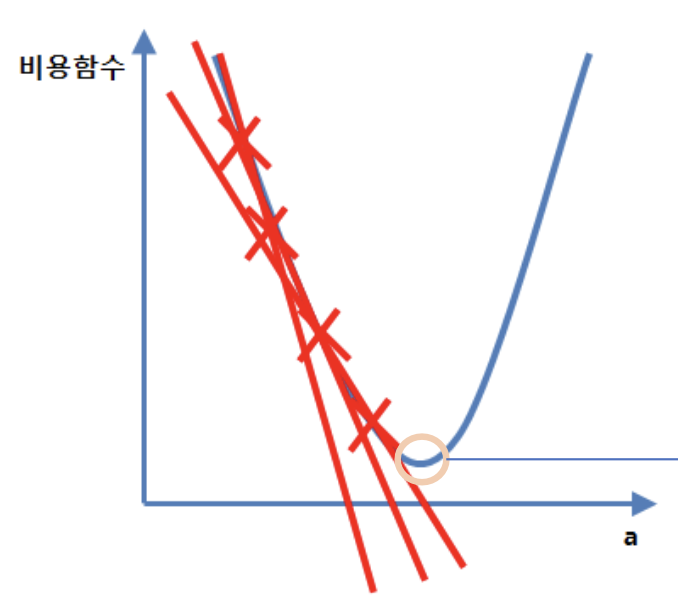
- 비용 함수의 기울기를 계속 낮은 쪽으로 이동시켜 극값(최적값)에 이를 때까지 반복하는 것
- 경사 하강법을 이용하여 비용 함수에서 기울기가 '0'일 때의 비용(오차)값을 구할 수 있음
- 비용 함수의 최소값을 구하면 이때 회귀 함수를 최적화 할 수 있게 됨
- 비용 함수에서 기울기가 '0'일 때 (비용 함수가 최솟값일 때) 모델의 기울기와 y절편을 구하여 회귀 함수 최적화
5. 경사 하강법 - learning rate(학습률)
- 선형 회귀에서 가중치(w)와 편향(b)을 경사 하강법에서 반복 학습시킬 때, 한 번 반복 학습시킬 때마다 포인트를 얼만큼씩 이동시킬 것인지 정하는 상수
- 학습률이 너무 작은 경우: local minimum에 빠질 수 있음
- 학습률이 너무 큰 경우: 수렴이 일어나지 않음
=> 적당한 learning rate를 찾는 것이 중요!
- 시작을 0.01로 시작해서 overshooting이 일어나면 값을 줄이고, 학습 속도가 매우 느리다면 값을 올리는 방향으로 진행
import numpy as np
import matplotlib.pyplot as plt
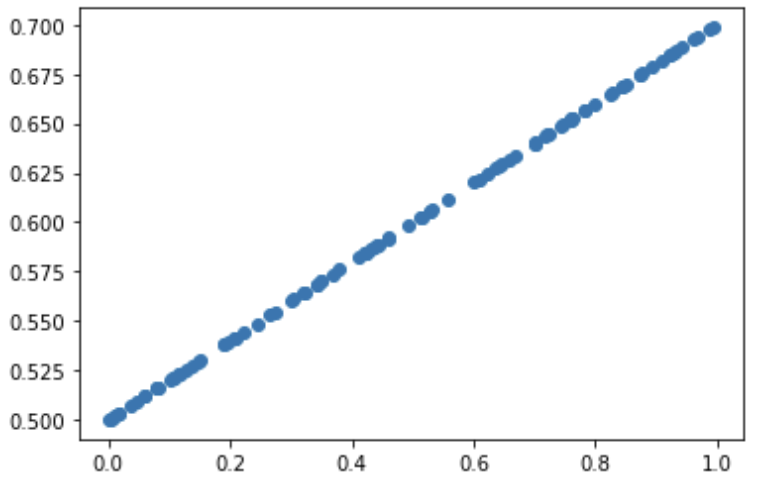
X = np.random.rand(100)
Y = 0.2 * X + 0.5 # 실제값 함수 가정
plt.figure()
plt.scatter(X, Y)
plt.show()
# 실제값, 예측값 산점도 그리는 함수
def plot_prediction(pred, y):
plt.figure()
plt.scatter(X, Y)
plt.scatter(X, pred)
plt.show()
# 경사 하강법 구현
W = np.random.uniform(-1, 1)
b = np.random.uniform(-1, 1)
learning_rate = 0.7 # 임의
for epoch in range(100):
Y_pred = W * X + b # 예측값
error = np.abs(Y_pred - Y).mean()
if error < 0.001:
break
# gradient descent 계산 (반복할 때마다 변경되는 W, b값)
w_grad = learning_rate * ((Y_pred-Y) * X).mean()
b_grad = learning_rate * ((Y_pred-Y)).mean()
# W, b 값 갱신
W = W - w_grad
b = b - b_grad
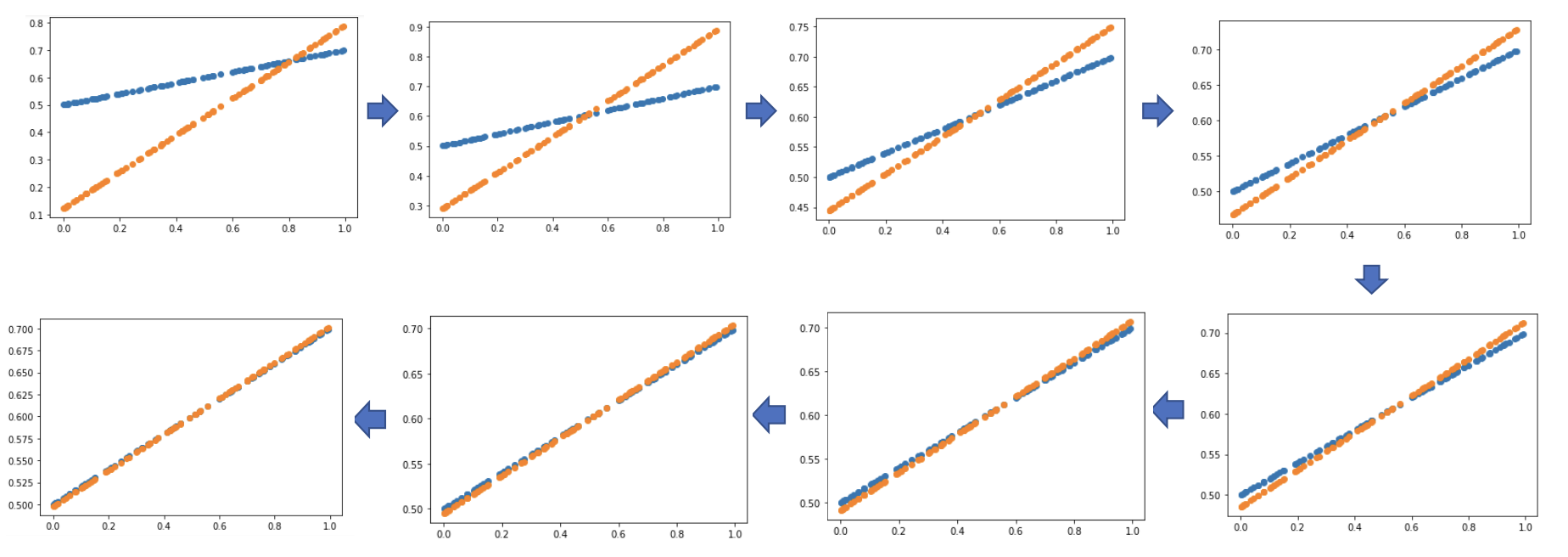
# 실제값과 예측값이 얼마나 근사해지는지 epoch % 5 ==0 될 때마다 그래프 그림
if epoch % 5 == 0:
Y_pred = W * X + b
plot_prediction(Y_pred, Y)
[파랑: 실제값, 주황: 예측값]
- 반복문이 실행되면서 오차가 점차 작아짐을 알 수 있음
- 최종적으로 오차가 줄어들며 실제값을 정확히 추정할 수 있음!
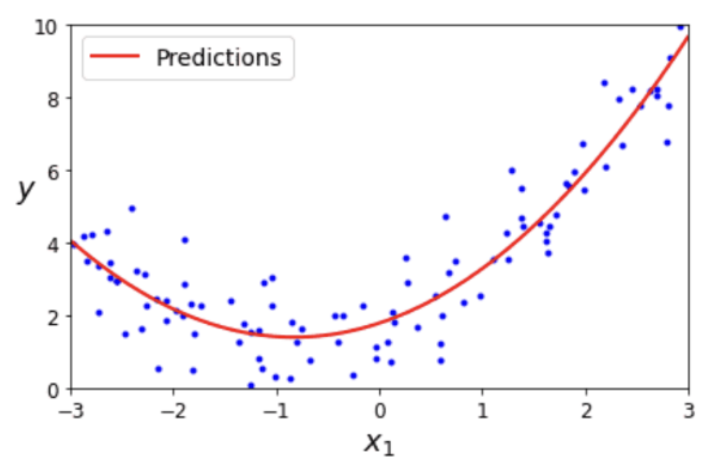
6. 다항 회귀
- 다항식을 사용한 선형 회귀
- y = a * x² + b * x + c 에서 x²을 z로 치환하면 y = a * z + b * x + c라는 선형식으로 쓸 수 있음
=> 다항식을 이용해서도 선형 회귀를 할 수 있음 → 최적의 곡선 찾기
- 비선형성을 띄는 데이터도 선형 모델을 활용하여 학습시킬 수 있다는 것
- 다항 회귀 기법: log, exp, 제곱 등을 적용해 선형식으로 변형한 뒤 학습시키는 것
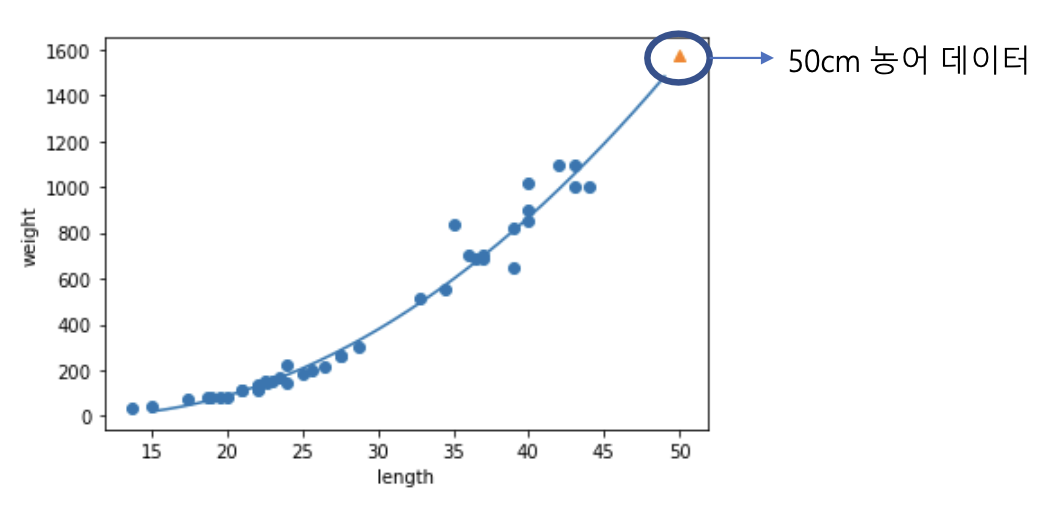
위의 선형회귀 모델의 문제점 해결
# 50cm 농어 평균 무게 예측
# 훈련 세트, 테스트 세트의 길이를 제곱한 값의 열 추가 - 새로운 훈련, 테스트 세트 생성
train_poly = np.column_stack((train_input**2, train_input))
test_poly = np.column_statck((test_input**2, test_input))
# 새로운 훈련 세트, 테스트 세트로 선형 회귀 모델 훈련
lr = LinearRegression()
lr.fit(train_poly, train_target)
# 무게 예측
print(lr.predict([50**2, 50]))
# [1573.98423528]
class sklearn.neighbors.KNeighborsRegressor(n_neighbhors=5, *, weights='uniform', algorithm='auto',
leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None):
'''
n_neighbors: 이웃의 수 K (defualt = 5)
weights: 예측에 사용되는 가중 방법 결정 (default = 'uniform') or callable
"uniform" : 각각의 이웃이 모두 동일한 가중치
"distance" : 거리가 가까울수록 높은 가중치
callable : 사용자가 직접 정의한 함수 사용
algorithm('auto', 'ball_tree', 'kd_tree', 'brute') : 가장 가까운 이웃을 계산할 때 사용할 알고리즘
"auto" : 입력된 훈련 데이터에 기반해 가장 적절한 알고리즘 사용
"ball_tree" : Ball-Tree 구조
"kd_tree" : KD-Tree 구조
"brute" : Brute-Force 탐색 사용
leaf_size : Ball-Tree나 KD-Tree의 leaf size 결정 (default = 30)
- 트리를 저장하기 위한 메모리, 트리의 구성과 쿼리 처리 속도에 영향
p : 민코프스키 미터법의 차수 결정 (1이면 맨해튼 거리, 2이면 유클리드 거리)
'''
from sklearn.neighbors import KNeighborRegressor
knr = KNeighborsRegressor()
knr.fit(train_input, train_target)
knr.score(test_input, test_target) # 테스트 모델에 대한 평가
# 0.9928094061
test_prediction = knr.predict(test_input) # 테스트 세트에 대한 예측
knr.score(train_input, train_target) # 훈련 모델에 대한 평가
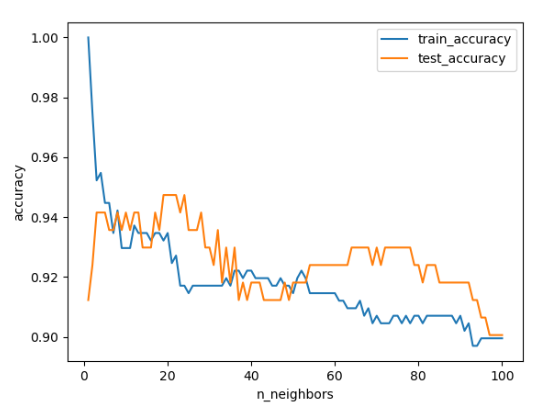
# 0.9698823289 이 경우는 과소적합 (훈련 < 테스트 점수)
knr.n_neighbors = 3 # 모델을 훈련세트에 잘 맞게 하기 위해 k 줄임 (5→3)
knr.fit(train_input, train_target) # 재훈련
knr.score(train_input, train_target)
# 0.9804899950
knr.score(test_input, test_target)
# 0.9746459963 # 훈련 > 테스트 점수이고, 차이가 크지 않으므로 적합!
knr.KNeighborRegressor()
x = np.arange(5, 45).reshape(-1, 1)
knr.n_neighbors = 3
knr = KNeighborsRegressor()
x =np.arange(5, 45).reshape(-1, 1) # 5에서 45까지 x 좌표 생성
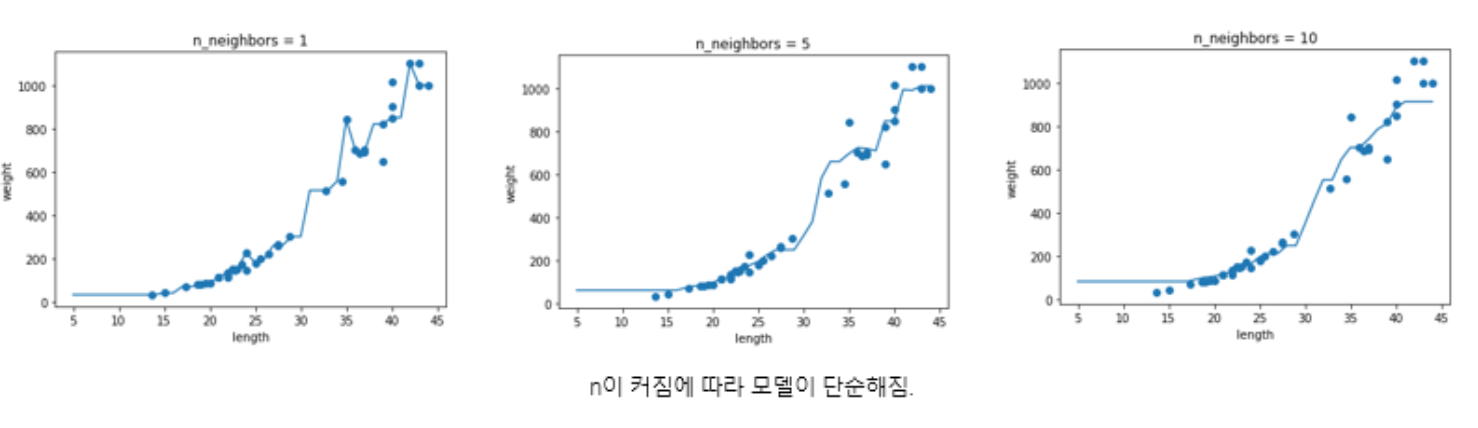
for n in [1, 5, 10]:
knr.n_neighbors = n
knr.fit(train_input, train_target) # 모델 훈련
prediction = knr.predict(x) # 지정한 범위 x에 대한 예측
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.title('n_neighbors = {}'.format(n))
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
df = df.dropna(how = 'all')
df = df.dropna(thresh = 1)
df = df.dropna(subset=['col1', 'col2', 'col3'], how = 'all') # 모두 결측치일 때 해당 행 삭제
df = df.dropna(subset=['col1', 'col2', 'col3'], thresh = 2) # 특정 열에 2개 초과의 결측치가 있을 때 해당 행 삭제
5-2) 대치
- 단순 대치: 중앙값, 최빈값, 0, 분위수, 주변값, 예측값 등으로 결측치 대치
- 다중 대치: 단순 대치법을 여러번! (대치 - 분석 - 결합)
- 판다스에서 결측치 대치하는 함수들
fillna()
# 전체 결측치를 특정 단일값으로 대치
df.fillna(0)
# 특정 열에 결측치가 있을 경우 다른 값으로 대치
df['col'] = df['col'].fillna(0)
df['col'] = df['col'].fillna(df['col'].mean())
# 결측치 바로 이후 행 값으로 채우기
df.fillna(method='bfill')
# 결측치 바로 이전 행 값으로 채우기
df.fillna(method='pad')
replace()
# 결측치 값 0으로 채우기
df.replace(to_replace = np.nan, value = 0)
interpolate()
# 인덱스를 무시하고, 값을 선형적으로 같은 간격으로 처리
df.interpolate(method = 'linear', limit_direction = 'forward')
5-3) 예측 모델
- 결측값을 제외한 데이터로부터 모델을 훈련하고 추정값을 계산하고 결측치 대체
- K-NN, 가중 K-NN, 로지스틱 회귀, SVM, 랜덤 포레스트 방식 등
7. 중복 데이터 처리
- 중복은 언제든지 발생할 수 있지만, 중복 데이터 사이에 속성의 차이나 값의 불일치가 발생한 경우, 처리해야 함
- 두 개체를 합치거나 응용에 적합한 속성을 가진 데이터를 선택하는 등
# 중복 데이터 확인
df.duplicated(['col'])
# 중복 데이터 삭제
drop_duplicates()
# 해당 열의 첫 행을 기준으로 중복 여부 판단 후, 중복되는 나머지 행 삭제
drop_duplicated(['col'])
df.drop_duplicates(keep = )
subset = None # default, 특정 열 지정 X, 모든 열에 대해 작업 수행
keep = 'first' # 가장 처음에 나온 데이터만 남김
keep = 'last' # 가장 마지막에 나온 데이터만 남김
keep = False # 중복된 어떤 데이터도 남기지 않음
8. 불균형 데이터 처리
- 분류를 목적으로 하는 데이터 셋에 클래스 라벨의 비율이 불균형한 경우
- 각 클래스에 속한 데이터 개수 차이가 큰 데이터
- 정상 범주의 관측치 수와 이상 범주의 관측치 수가 현저히 차이나는 데이터
- 이상 데이터를 정확히 찾아내지 못할 수 있음
8-1) Under Sampling
- 다수 범주의 데이터를 소수 범주의 데이터 수에 맞게 줄이는 샘플링 방식
- Random Undersampling, Tomek's Link, CNN
8-2) Over Sampling
- 소수 범주의 데이터를 다수 범주의 데이터 수에 맞게 늘리는 샘플링 방식
- Random Oversampling
- ADASYN, SMOTE
9. 이상치 탐지 기법
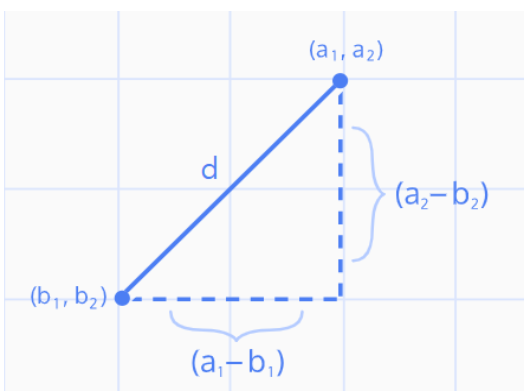
1) z-score
- z = (x - μ) / σ
- 변수가 정규분포 따른다고 가정, 각 특성값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지 나타냄
class MyThread extends Thread {
public void run() {
for (int i = 0; i <= 10; i++)
System.out.print(i + " ");
}
}
public class MyThreadTest {
public static void main(String args[]) {
Thread t = new MyThread();
t.start();
}
}
// 0 1 2 3 4 5 6 7 8 9 10
3-2) 스레드 생성: Runnable 인터페이스 구현하는 방법
- Runnable 인터페이스를 구현한 클래스 작성
- run() 메소드 작성
- Thread 객체 생성하고 Runnable 객체 인수로 전달
- start() 호출해서 스레드 시작
class MyRunnable implements Runnable {
public void run() {
for (int i = 0; i <= 10; i++)
System.out.print(i + " ");
}
}
public class MyRunnableTest {
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
t.start();
}
}
// 0 1 2 3 4 5 6 7 8 9 10
- 스레드 2개 예제
class MyThread extends Thread {
public void run() {
for (int i = 0; i < 10; i ++) {
System.out.print(i + " ");
}
}
}
class MyRunnable implements Runnable {
public void run() {
for (int i = 0; i < 30; i ++) {
System.out.print("[" + i + "]");
}
}
}
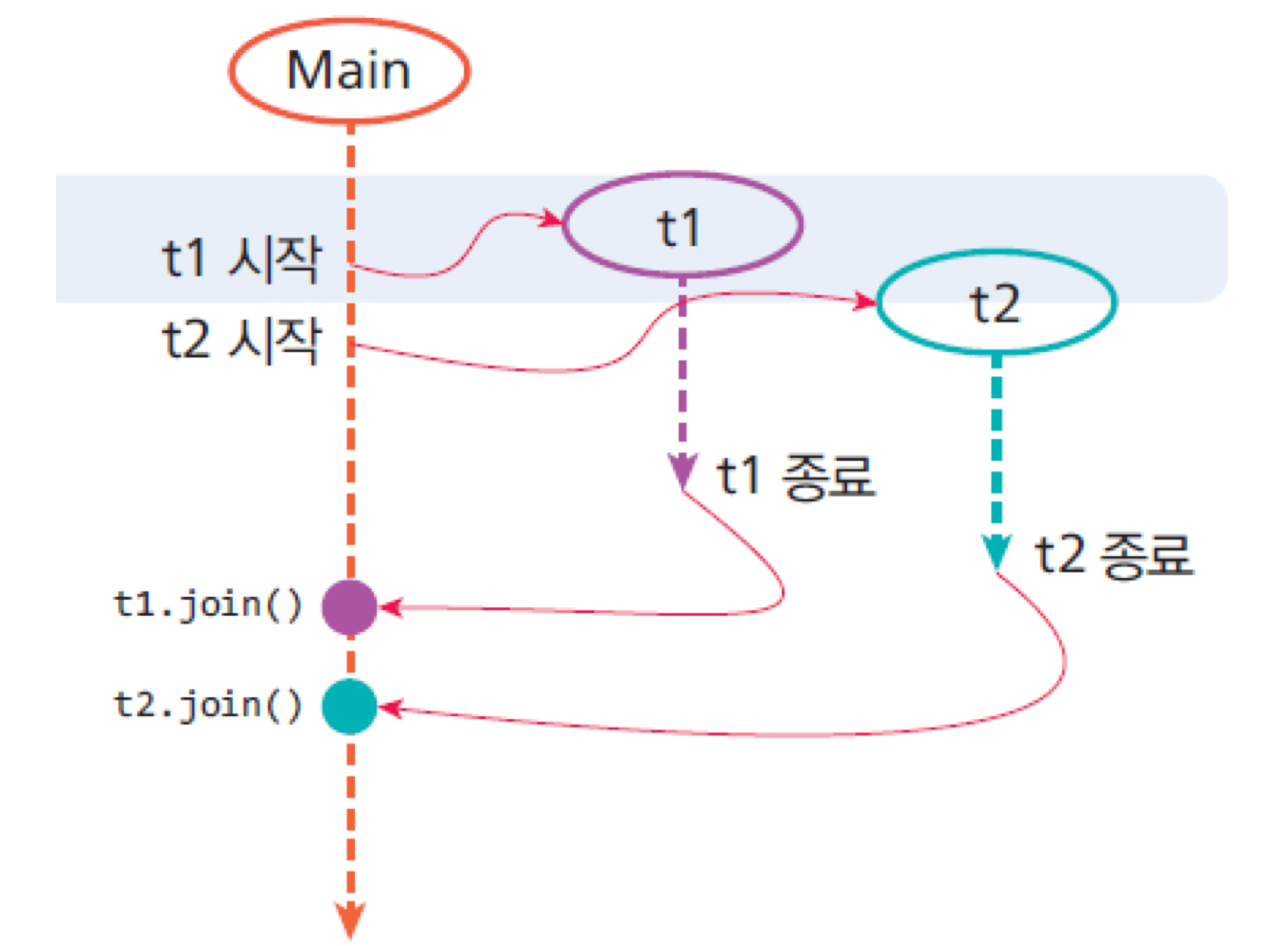
public class ThreadTest {
public static void main(String[] args) throws InterruptedException {
System.out.println("main start");
MyThread mt = new MyThread();
mt.start();
MyThread mt2 = new MyThread();
mt2.start();
Thread t = new Thread(new MyRunnable()); // runnable -바로 스타트 불가.
t.start();
// 모든 작업이 끝났을 때 종료 메세지를 출력하고 싶은 경우
mt.join();
mt2.join();
t.join(); // 끝날 때까지 기다리기
System.out.println("\nmain end");
}
}
/**
main start
0 1 2 3 4 0 5 6 7 8 9 1 2 3 4 5 6 7 8 9 [0][1][2][3][4][5][6][7][8][9][10][11][12][13][14][15][16][17][18][19][20][21][22][23][24][25][26][27][28][29]
main end
**/
- 람다식 이용한 스레드 작성
public class LambdaTest {
public static void main(String[] args) {
Runnable task = () -> {
for (int i = 0; i <= 10; i++)
System.out.print(i + " ");
};
new Thread(task).start();
}
}
// 0 1 2 3 4 5 6 7 8 9 10
4. 스레드 상태
- New : Thread 클래스의 인스턴스는 생성되었지만, start() 메소드를 호출하기 전
- Runnable : start() 메소드가 호출되어 실행 가능한 상태, 하지만 아직 스케줄러가 선택하지 않았으므로 실행 상태는 아님
- 실행 가능 상태 : 스레드가 스케줄링 큐에 넣어지고, 스케줄러에 의해 우선순위에 따라 실행
- 실행 중지 상태
- 스레드나 다른 스레드가 suspend()를 호출하는 경우
- 스레드가 wait() 호출하는 경우
- 스레드가 sleep() 호출하는 경우
- 스레드가 입출력 작업을 하기 위해 대기하는 경우
5. 스레드 스케줄링
- 대부분 스레드 스케줄러는 선점형 스케줄링과 타임 슬라이싱을 사용해 스레드 스케줄링
- 어떤 스케줄링을 선택하느냐는 JVM에 의해 결정됨
6. 스레드 우선순위
- 1 ~ 10 사이의 숫자료 표시됨
- 기본 우선순위 : NORM_PRIORITY(5)
- MIN_PRIORITY(1)
- MAX_PRIORITY(10)
- void setPriority(int newPriority) : 현재 스레드의 우선 순위 변경
- getPriority() : 현재 스레드의 우선 순위 반환
7. sleep()
- 지정된 시간동안 스레드 재움
- 스레드가 수면 상태로 있는 동안 인터럽트되면 InterruptedException 발생
- 4초 간격으로 메시지 출력
public class SleepTest {
public static void main(String[] args) throws InterruptedException {
String messages[] = {"Hello.",
"My name is A.",
"I'm majoring in computer science.",
"I'm taking a JAVA class."};
for (int i = 0; i < messages.length; i++) {
Thread.sleep(4000);
System.out.println(messages[i]);
}
}
}
/**
Hello.
My name is A.
I'm majoring in computer science.
I'm taking a JAVA class.
**/
8. join()
- 스레드가 종료될 때까지 기다리는 메소드
- 특정 스레드가 작업을 완료할 때까지 현재 스레드의 실행을 중지하고 기다리는 것
9. 인터럽트와 yield()
- 인터럽트 : 하나의 스레드가 실행하고 있는 작업을 중지하도록 하는 메커니즘 -> 대기 상태나 수면 상태가 됨
- yield() : CPU를 다른 스레드에게 양보하는 메소드
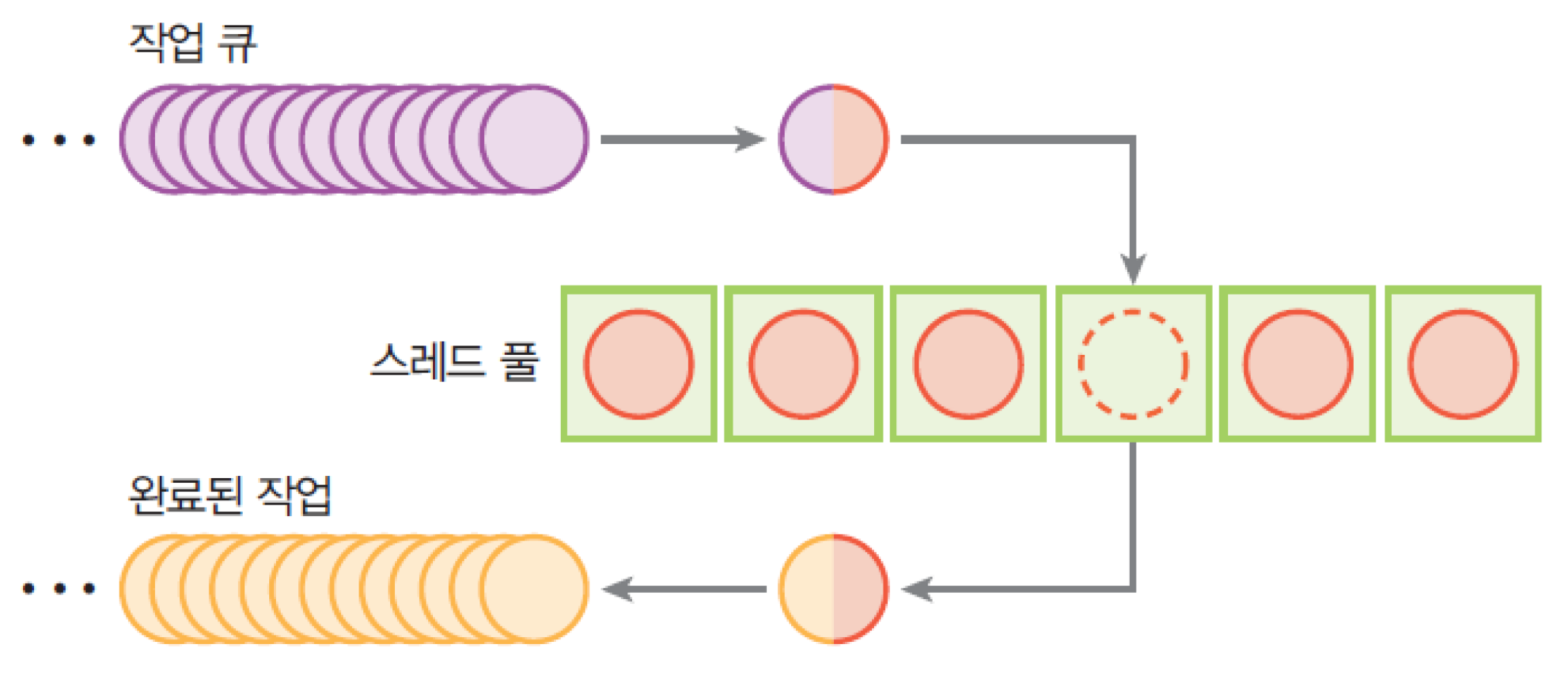
10. 자바 스레드 풀
- 스레드 풀 : 미리 초기화된 스레드들이 모여 있는 곳
- 스레드 풀의 동일한 스레드를 사용하여 N개의 작업을 쉽게 실행할 수 있음
- 스레드의 개수보다 작업의 개수가 더 많은 경우, 작업은 FIFO 큐에서 기다려야 함
- Java5 부터 자바 API는 Executor 프레임워크 제공
-> 개발자는 Runnable 객체를 구현하고 ThreadPoolExecutor로 보내기만 하면 됨
class MyTask implements Runnable {
private String name;
public MyTask(String name) {
this.name = name;
}
public String getName() { return name; }
public void setName(String name) { this.name = name; }
@Override
public void run() {
try {
System.out.println("실행중 : " + name);
Thread.sleep(long)(Math.random() * 1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public class ThreadPoolTest {
public static void main(String[] args) {
ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newFixedThreadPool(2);
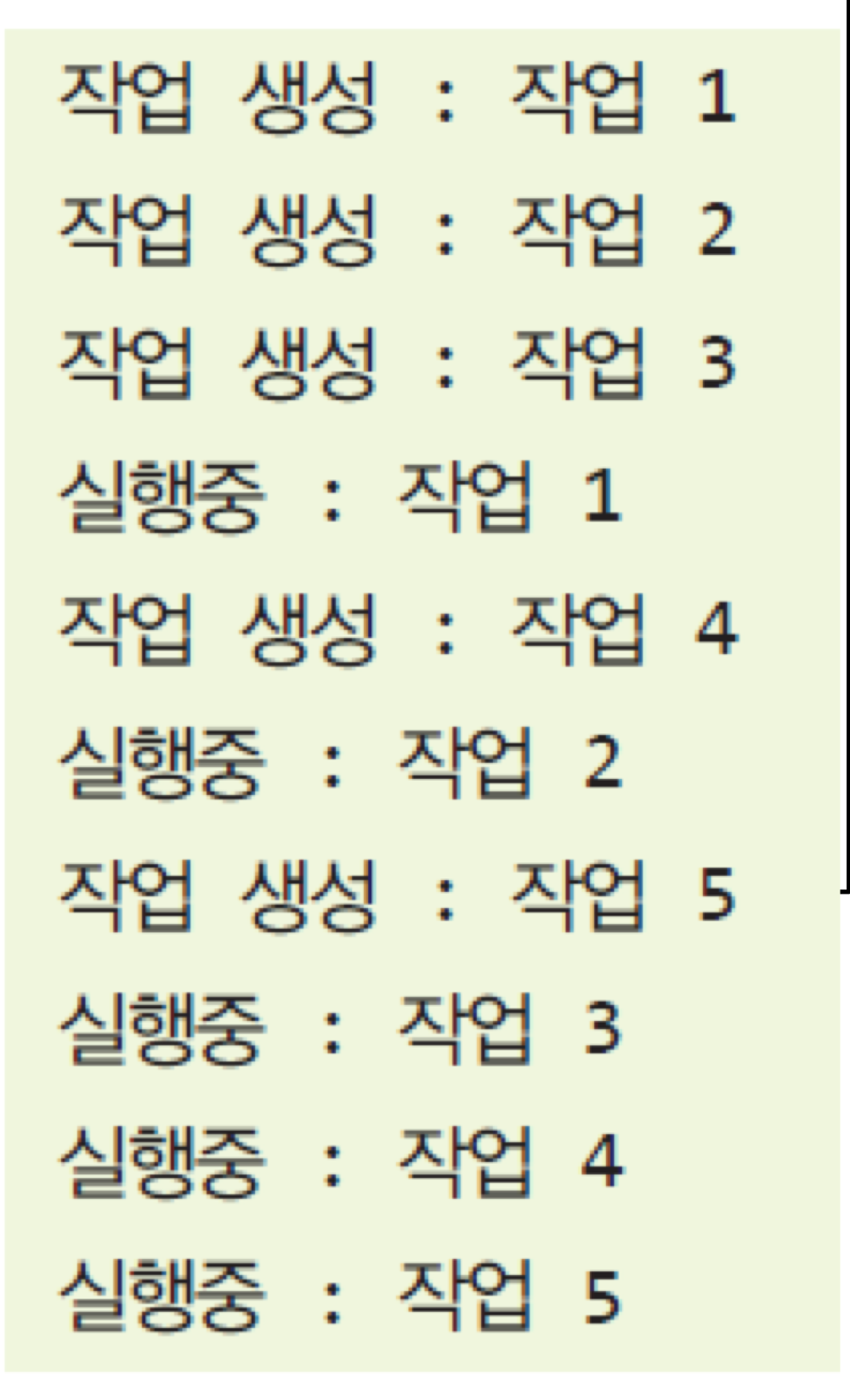
for(int i = 0; i <= 5; i++) {
MyTask task = new MyTask("작업 " + i);
System.out.println("작업 생성 : " + task.getName());
executor.execute(task);
}
executor.shutdown();
}
}
11. 스레드 사용시 주의해야 할 점
- 동일한 데이터를 공유하기 때문에 매우 효율적으로 작업할 수 있지만, 2가지의 문제가 발생할 수 있음
- 문제 예제
class Printer {
void print(int[] arr) {
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
Thread.sleep(100);
}
}
}
class MyThread1 extends Thread {
Printer prn;
int[] myarr = {10, 20, 30, 40};
MyThread1(Printer prn) { this.prn = prn; }
public void run() { prn.print(myarr); }
}
class MyThread2 extends Thread {
Printer prn;
int[] myarr = {1, 2, 3, 4};
MyThread2(Printer prn) { this.prn = prn; }
public void run() { prn.print(myarr); }
}
public class TestSynchro {
pubilc static void main(String args[]) {
Printer obj = new Printer();
MyThread1 t1 = new MyThread1(obj);
MyThread2 t2 = new MyThread2(obj);
t1.start();
t2.start();
}
}
// 1 10 20 2 30 3 4 40
// 순서는 계속 바뀔 수 있음, 둘이 섞여서 엉망으로 출력됨
11-1) 동기화 (Synchronization)
- 한 번에 하나의 스레드만이 공유 데이터를 접근할 수 있도록 제어하는 것이 필요
- 자원에 한 번에 하나의 스레드만이 접근할 수 있고, 하나의 스레드 작업이 끝나면 다음 스레드가 사용할 수 있도록 하여 해결
- 자바에서의 동기화 방법
- 동기화 메소드
- 동기화 블록
- 정적 동기화
- 락(lock) 또는 모니터(monitor) 사용
// 메소드 앞에 synchronized 키워드 붙이기
class Printer {
synchronized void print(int[] arr) {
....
}
}
// 10 20 30 40 1 2 3 4
// 부분 코드만 동기화 -> synchronized 블록으로 설정
class Printer {
void print(int[] arr) throws Exception {
synchronized(this) {
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
Thread.sleep(100);
}
}
}
}
12. 교착 상태, 기아 상태
- 동일한 자원을 접근하려고 동기화를 기다리면서 대기하는 스레드들이 많아지면 JVM이 느려지거나 일시 중단 되기도 함
- 문제 예제
public class DeadLockTest {
public static void main(String[] args) {
final String res1 = "Gold";
final String res2 = "Silver";
Thread t1 = new Thread(() -> {
synchronized(res1) {
System.out.println("Thread 1 : 자원 1 획득");
try { Thread.sleep(100); } catch (Exception e) {}
synchronized(res2) {
systme.out.println("Thread 1 : 자원 2 획득");
}
}});
Thread t2 = new Thread(() -> {
synchronized(res2) {
System.out.println("Thread 2 : 자원 2 획득");
try { Thread.sleep(100); } catch (Exception e) {}
synchronized(res1) {
System.out.println("Thread 2 : 자원 1 획득");
}
}});
t1.start();
t2.start();
}
}
// Thread 1 : 자원 1 획득
// Thread 2 : 자원 2 획득
12-1) 방법1 : 잠금 순서 변경
Thread t2 = new Thread(() -> {
synchronized(res1) {
System.out.println("Thread 2 : 자원 1 획득");
try { Thread.sleep(100); } catch (Exception e) {}
synchronized(res2) {
System.out.println("Thread 2 : 자원 2 획득");
}
}});
/**
Thread 1 : 자원 1 획득
Thread 1 : 자원 2 획득
Thread 2 : 자원 1 획득
Thread 2 : 자원 2 획득
**/
12-2) 방법2: 스레드 간의 조정
13. wait(), notify()
- 이벤트가 발생하면 알리는 방법
- 생산자/소비자 문제에 적용
// buffer 클래스
class Buffer {
private int data;
private boolean empty = true;
public synchronized int get() {
while (empty) {
try {
wait();
} catch (InterruptedException e) {
}
}
empty = true;
notifyAll();
return data;
}
public synchronized void put(int data) {
while (!empty) {
try {
wait();
} catch (InterruptedException e) {
}
}
empty = false;
this.data = data;
notifyAll();
}
}
// 생산자
class Producer implements Runnable {
private Buffer buffer;
public Producer(Buffer buffer) {
this.buffer = buffer;
}
public void run() {
for (int i = 0; i < 10; i++) {
buffer.put(i);
System.out.println("생산자: " + i + "번 케익을 생산하였습니다.");
try {
Thread.sleep((int) (Math.random() * 100));
} catch (InterruptedException e) {
}
}
}
}
// 소비자
class Consumer implements Runnable {
private Buffer buffer;
public Consumer(Buffer drop) {
this.buffer = drop;
}
public void run() {
for (int i = 0; i < 10; i++) {
int data = buffer.get();
System.out.println("소비자: " + data + "번 케익을 소비하였습니다.");
try {
Thread.sleep((int) (Math.random() * 100));
} catch (InterruptedException e) {
}
}
}
}
public class ProducerConsumerTest {
public static void main(String[] args) {
Buffer buffer = new Buffer();
(new Thread(new Producer(buffer))).start();
(new Thread(new Consumer(buffer))).start();
}
}
/**
생산자: 0번 케익을 생산하였습니다.
소비자: 0번 케익을 소비하였습니다.
생산자: 1번 케익을 생산하였습니다.
소비자: 1번 케익을 소비하였습니다.
...
생산자: 9번 케익을 생산하였습니다.
소비자: 9번 케익을 소비하였습니다.
**/
바이트 스트림 클래스 이름에는 InputStream(입력), OutputStream(출력)이 붙음
문자 스트림 클래스 이름에는 Reader(입력), Writer(출력)이 붙음
2. 문자 스트림
- 입출력 단위가 문자 (바이트 X)
- 자바는 유니코드 이용하여 문자 저장
- 주요 메소드
- 파일에서 문자 읽고 쓸 때는 FileReader, FileWriter 사용
- 파일에서 문자 읽는 경우 일반적으로 반복문 사용
int ch;
while ((ch = fr.read()) != -1)
System.out.print((char) ch + " ");
import java.io.*;
public class FileReaderTets(String met){
public static void main(String[] args) {
FileReader fr;
try {
fr = new FileReader("test.txt");
int ch;
while((ch fr.read() != -1)
System.out.print((char) ch + " ");
fr.close();
} catch (IOException e) {
e.printSTackTrace();
}
}
}
3. try-with-resources 사용
- close() 따로 호출하지 않아도 자동으로 호출
import java.io.*;
public class FileReaderTest2 {
public static void main(String[] args) throws Exception {
try(FileReader fr = new FileReader("test.txt")) {
int ch;
while((ch = fr.read()) != -1 )
System.out.print((char) ch);
} catch (IOException e) {
e.printStackTrace();
}
}
}
4. 중간 처리 스트림
- 자료형이 다른 몇 개의 데이터 파일에 출력했다가 다시 읽기
import java.io.*;
public class DataStreamTest {
public static void main(String[] args) throws IOException {
DataInputStream in = null;
DataOutputStream out = null;
try {
out = new DataOutputStream(new FileOutputStream("data.bin"));
out.writeInt(123);
out.writeFloat(123.456F);
out.close();
in = new DataInputStream(new FileInputStream("data.bin"));
int aint = in.readInt();
float afloat = in.readFloat();
System.out.println(aint);
System.out.println(afloat);
}
finally { // 예외에 상관없이 실행
if (in != null) // in이 생성 되어있다면
in.close();
if (out != null)
out.close();
}
}
}
// 123
// 123.456
5. 버퍼 스트림
- 버퍼 입력 스트림: 입력 장치에서 한번에 많이 읽어서 버퍼에 저장, 입력을 요구하면 버퍼에서 꺼내서 반환함
- 버퍼가 비었을 때만 입력 장치에서 읽음
inputStream = new BufferedReader(new FileReader("input.txt"));
outputStream = new BufferedWriter(new FileWriter("output.txt"));
- 줄 단위로 복사하기 (BufferedReader, PrintWriter 클래스 사용)
import java.io.*;
public class CopyLines {
public static void main(String[] args) {
try (BufferedReader in = new BufferedReader(new FileReader("test.txt"))) {
PrintWriter out = new PrintWriter(new FileWriter("output.txt"))) {
String line;
while ((line = in.readLine()) != null) {
out.println(line);
}
} catch(IOException e) {
e.printStackTrace();
}
}
}
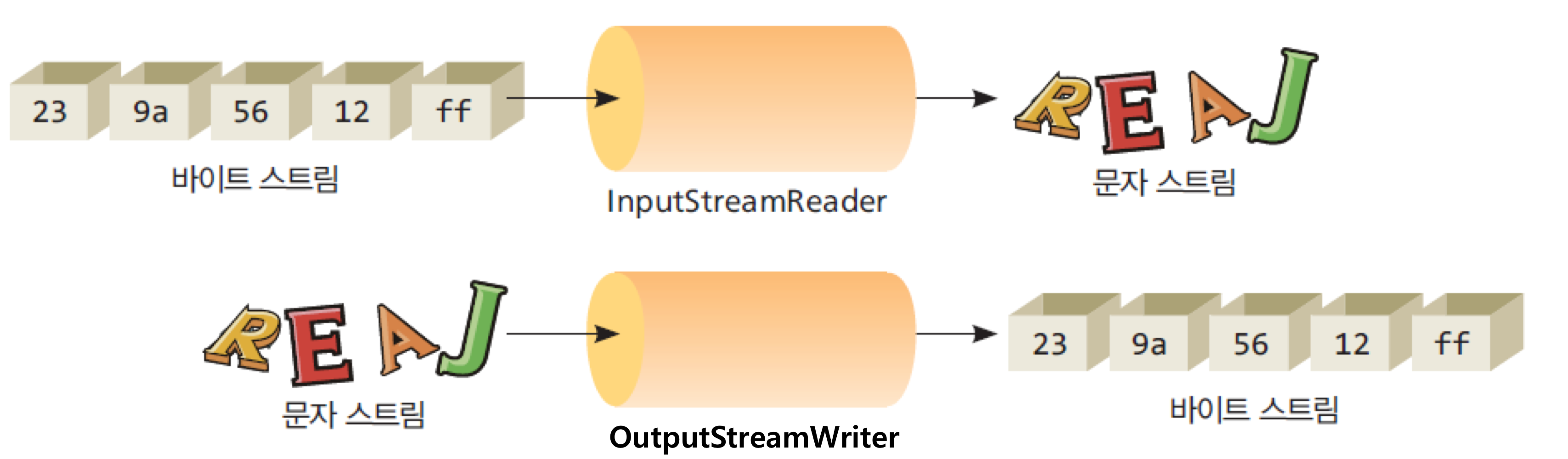
6. InputStreamReader, OutputStreamWriter 클래스
- 바이트 스트림과 문자 스트림을 연결하는 두 개의 범용 브릿지 스트림
6-1) 한글 코드
- ASCII
- EUC-KR : 한글 완성형, 16비트, 국내 규격
- CP949 (MS949) : 한글 지원을 위해 MS 윈도우 계열에서 등장한 확장 완성형 인코딩 방식, ANSI
- 유니코드 : 전 세계에서 사용하는 수많은 문자들 각각에 부여한 코드들의 집합
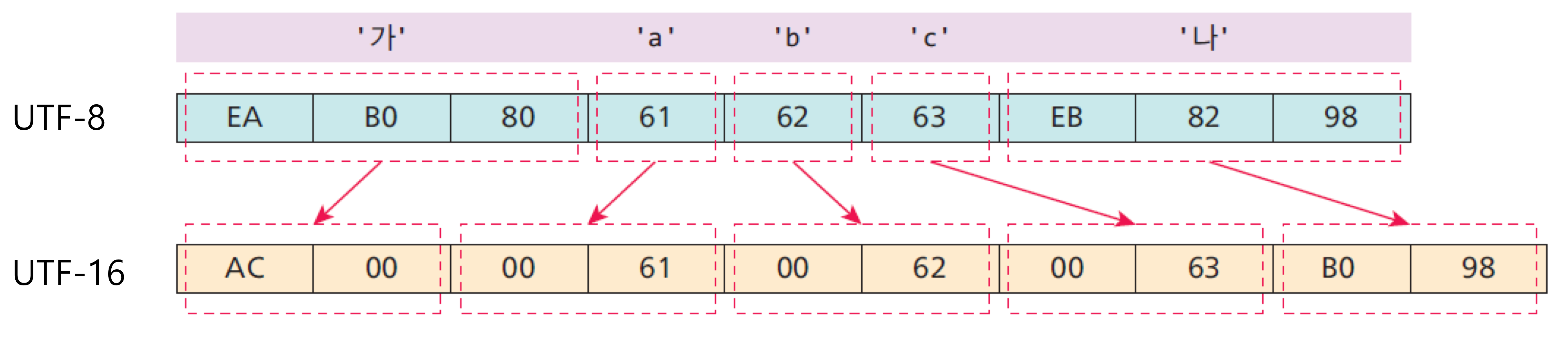
- UTF-8 : 1~4byte로 인코딩하는 가변 길이 인코딩 방식, 기본적으로 첫 128개의 문자들은 1byte에 그대로 인코딩
- UTF-16 : 16bit 기반의 인코딩 방식, 한글 2byte, ANSI와 호환이 되지 않는 문제 있음
6-2) InputStreamReader
- 바이트 스트림 -> 문자 스트림으로 변환
BufferedReader in = new BufferedReader(new InputStreamReader(
new FileInputStream(FileDir), "UTF8"));
- UTF-8 코딩 파일 읽기
public class CharEncodingTest {
public static void main(String[] args) throws IOException {
File FileDir = new File("input.txt");
BufferedReader in = new BufferedReader(new InputStreamReader(
new FileInputStream(fileDir), "UTF-8"));
String str;
while ((str=in.readLine()) != null) {
System.out.println(str);
}
in.close();
}
}
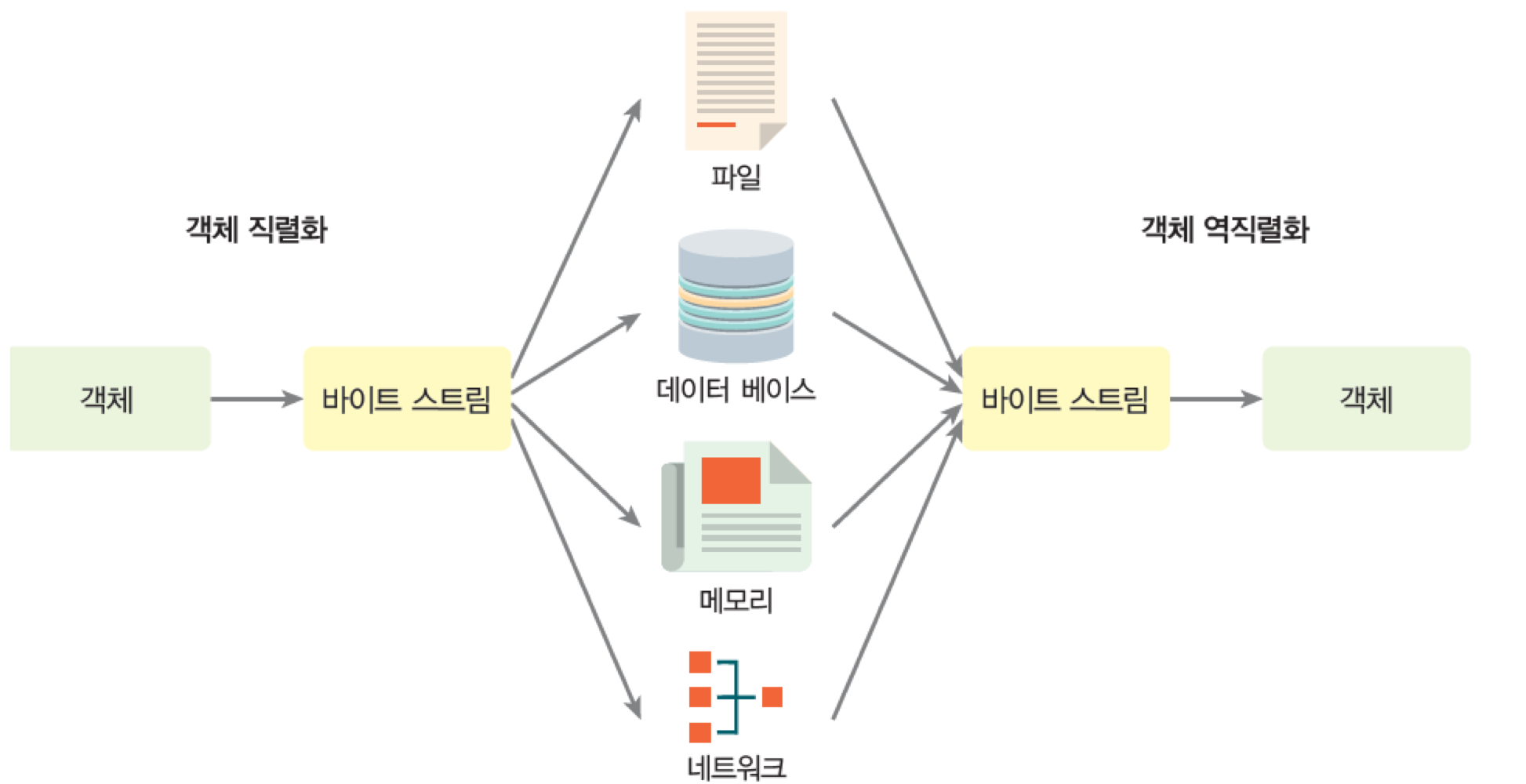
7. 객체 저장하기 : 객체 직렬화
- 객체 직렬화 : 객체가 가진 데이터들을 순차적인 데이터로 변환
- 순차적인 데이터가 되면 파일에 쉽게 저장할 수 있음
- 직렬화 지원 : Serializable 인터페이스 구현
- 역직렬화 : 직렬화된 데이터를 읽어서 자신의 상태를 복구하는 것
- Date 객체 저장하기
public class ObjectStreamTest {
public static void main(String[] args) throws Exception {
ObjectInputStream in = null;
ObjectOutputStream out = null;
int c;
out = new ObjectOutputStream(new FileOutputStream("object.dat"));
out.writeObject(new Date());
out.close();
in = new ObjectInputStream(new FileInputStream("object.dat"));
Date d = (Date) in.readObject();
System.out.println(d);
in.close();
}
}
// Sat Jan 06 14:46:32 KST 2018
8. Path 객체
- 경로를 나타내는 클래스
- "D:\sources\test.txt" 와 같은 경로를 받아서 객체 반환
public class PathTest {
public static void main(String[] args) {
Path path = Paths.get("D:\\sources\\test.txt");
System.out.println("전체 경로: " + path);
System.out.println("파일 이름: " + path.getFileName());
System.out.println("부모 이름: " + path.getParent().getFileName());
}
}
/**
전체 경로: D:\sources\test.txt
파일 이름: test.txt
부모 이름: sources
**/
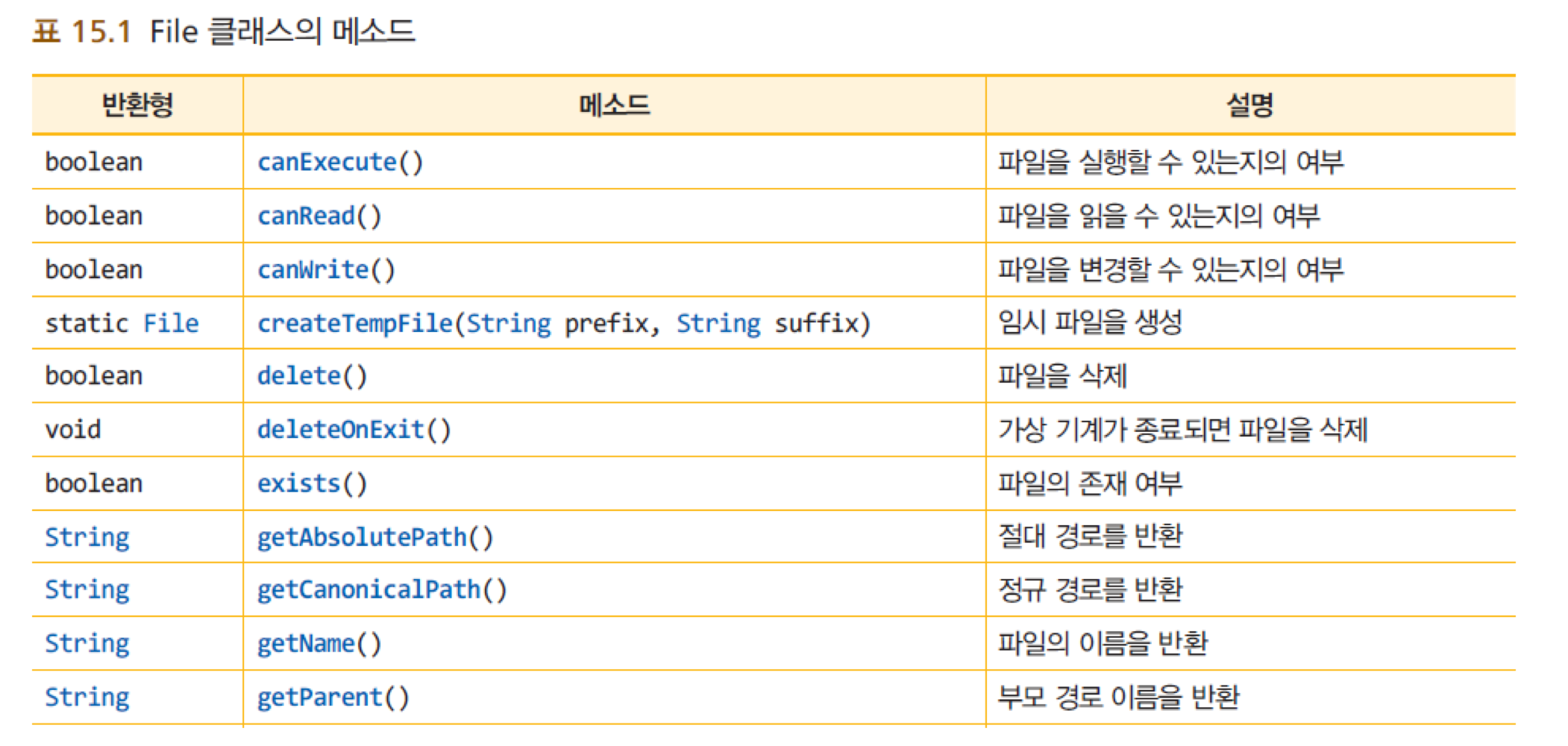
9. File 객체
- 파일을 조작하고 검사하는 코드를 쉽게 작성하게 해주는 클래스
- 파일이 아닌, 파일 이름을 나타내는 객체!
File file = new File("data.txt");
10. 스트림 라이브러리로 파일 처리하기
// 현재 디렉터리의 모든 파일을 출력하는 코드
Files.list(Paths.get(".")).forEach(System.out::println);
// 파일 읽어서 각 줄 끝에 있는 불필요한 공백을 제거하고 빈 줄을 필터링한 후에 출력
Files.lines(new File("test.txt").toPath())
.map(s -> s.trim())
.filter(s -> !s.isEmpty())
.forEach(System.out::println);
class Box<T> { ... } // T : 타입 매개변수 - String도 될 수 있고, Integer도 될 수 있음
2. 기존의 방법
일반적인 객체를 처리하려면 Object 참조 변수 사용: 어떤 객체이든지 참조 가능
public class Box {
private Object data;
private void set(Object data) { this.data = data; }
public Object get() { return data; }
}
Box b = new Box();
b.set("Hello World!"); // 문자열 객체 저장
String s = (String)b.get(); // Object 타입을 String 타입으로 형변환
b.set(new Integer(10)); // 정수 객체 저장
Integer i = (Integer)b.get(); // Object 타입을 Integer 타입으로 형변환
b.set("Hello World!");
Integer i = (Integer)b.get(); // 오류! 문자열을 정수 객체로 형변환 (x)
3. 제네릭을 이용한 방법
class Box<T> {
private T data;
public void set(T data) { this.data = data; }
public T get() { return data; }
}
Box<String> b = new Box<String>();
b.set("Hello World!"); // 문자열 저장
String s = b.get();
Box<String> stringBox = new Box<>(); // 뒤에 나오는 타입 <> 생략 가능
stringBox.set(new Integer(10)); // 정수 타입을 저장하려고 하면 컴파일 오류!
4. 제네릭 메소드
일반 클래스의 메소드에서도 타입 매개 변수를 사용해서 제네릭 메소드 정의 가능
이 경우에는 타입 매개 변수의 범위가 메소드 내부로 한정됨
public class MyArray {
public static <T> T getLast(T[] a) { // 제네릭 메소드 정의
return a[a.length - 1];
}
}
public class MyArrayTest {
public static void main(String\[\] args) {
String\[\] language = { "C++", "C#", "JAVA" };
String last = MyArray.getLast(language); // last는 "JAVA"
System.out.println(last);
}
}
// JAVA
예제2
public class GenericTest {
public static <T> void printArray(T[] array) {
for (T element : array) {
System.out.println(element + " ");
}
System.out.println();
}
public static void main(String[] args) {
Integer[] iArray = {10, 20, 30, 40, 50}; // wrapper 클래스
Double[] dArray = {1.1, 1.2, 1.3, 1.4, 1.5};
Character[] cArray = {'K', 'O', 'R', 'E', 'A'};
printArray(iArray);
printArray(dArray);
printArray(cArray);
}
}
/**
10 20 30 40 50
1.1 1.2 1.3 1.4 1.5
K O R E A
**/
제네릭 메소드에는 기본 data type을 매개 변수로 넘길 수 없음!
객체 데이터 타입을 넘겨야 함 -> wrapper 클래스 이용
1. 컬렉션 collection
자바에서 자료구조를 구현한 클래스
list, stack, queue, set, hash table 등
컬렉션 인터페이스와 컬렉션 클래스로 나누어 제공
컬렉션 인터페이스
인터페이스
설명
Collection
모든 자료구조의 부모 인터페이스로서 객체의 모임 나타냄
Set
집합 (중복된 원소 불가)
List
순서가 있는 자료구조 (중복된 원소 가능)
Map
키와 값들이 연관되어 있는 dictionary와 같은 자료구조
Queue
선입선출 자료구조
2. 컬렉션 특징
제네릭 사용
컬렉션에는 int, double과 같은 기초 자료형 사용 불가. 클래스만 가능!
기초 자료형은 wrapper 클래스로 사용 (Integer, Double 등)
기본 자료형을 저장하면 자동으로 래퍼 클래스의 객체로 변환됨 (오토박싱)
3. 컬렉션 인터페이스 주요 메소드
메소드
설명
boolean isEmpty()boolean contains(Object obj)boolean cotainsAll(Colllection<?> c)
// 기존
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("thread start");
}
}).start();
// 람다식
new Thread( () -> System.out.println("thread start") ).start();
배열의 모든 요소 출력
// 기존
List<Integer> list = Arrays.asList( 1, 2, 3, 4, 5 );
for (Integer n : list )
System.out.println(n);
// 람다식
list.forEach( n -> System.out.println(n) );
<br>
8. 컬렉션 - Vector 클래스
가변 크기의 배열 (dynamic array)
vector의 크기는 자동으로 관리됨
import java.util.*;
public class VectorEx {
public static void main(String[] args) {
Vector<String> vec = new Vector<String>(2);
vec.add("Apple");
vec.add("Orange");
vec.add("Mango");
System.out.println("Vector size: " + vec.size());
Collections.sort(vec);
for(String s : vec)
System.out.print(s + " ");
}
}
// Vector size: 3
// Apple Mango Orange
9. ArrayList
가변 크기의 배열(Array)
ArrayList<String> list = new ArrayList<String>();
메소드
설명
list.add()
원소 추가
list.set(2, "GRAPE")
인덱스 2의 원소를 "GRAPE"로 교체
list.remove(3)
인덱스 3의 원소 삭제
class Point {
int x, y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
public String toString() { return "(" + x + ", " + y + ")"); }
}
public class ArrayListTest {
public static void main(String[] args) {
ArrayList<Point> list = new ArrayList();
list.add(new Point(0, 0));
list.add(new Point(4, 0));
list.add(new Point(3, 5));
list.add(new Point(-1, 3));
list.add(new Point(13, 2));
System.out.println(list);
}
}
// [(0, 0), (4, 0), (3, 5), (-1, 3), (13, 2)]
10. Vector vs ArrayList
Vector는 스레드 간 동기화 지원
ArrayList는 동기화 X - Vector보다 성능은 우수함
11. LinkedList
빈번하게 삽입과 삭제가 일어나는 경우에 사용
배열 중간 삽입은 원소들의 이동이 발생하지만, 연결 리스트는 링크만 수정하면 됨
import java.util.*;
public class LinkedListTest {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<String>();
list.add("MILK");
list.add("BREAD");
list.add("BUTTER");
list.add(1, "APPLE");
list.add(2, "GRAPE");
list.remove(3);
for(int i = 0; i < list.size(); i++)
System.out.println(list.get(i) + " ");
}
}
// MILK APPLE GRAPE
12. ArrayList vs LinkedList
ArrayList는 인덱스를 가지고 원소에 접근할 경우, 항상 일정한 시간만 소요됨
ArrayList는 리스트의 각각의 원소를 위해 노드 객체를 할당할 필요 없음
동시에 많은 원소를 이동해야 하는 경우 System.arraycopy() 메소드 사용 가능
리스트의 처음에 빈번하게 원소를 추가하거나, 내부 원소 삭제를 반복하는 경우에는 LinkedList를 사용하는 것이 나음
이들 연산은 LinkedList에서는 일정한 시간만 걸리지만, ArrayList에서는 원소의 개수에 비례하는 시간 소요됨
13. Set
원소의 중복 허용X
순서 없음
인터페이스 구현 방법
HashSet : 해쉬 테이블에 원소 저장 -> 성능 면에서 가장 우수, 순서가 일정하지 않다는 단점
TreeSet : red-black tree에 원소 저장 -> 값에 따라 순서가 결정됨, HashSet보다는 느림
LinkedHashSet : 해쉬 테이블과 연결 리스트를 결합한 것, 원소 순서 = 삽입 순서
import java.util.*;
public class SetTest {
public static void main(String[] args) {
HashSet<String> set = new HashSet<String>();
set.add("Milk");
set.add("Break");
set.add("Butter");
set.add("Cheese");
set.add("Ham");
set.add("Ham");
System.out.println(set);
if(set.contains("Ham"))
System.out.println("Ham도 포함되어 있음");
}
}
// [Ham, Butter, Cheese, Milk, Bread]
// Ham도 포함되어 있음
큐의 처음에 있는 원소 제거하거나 가져옴 정확히 어떤 원소인지는 큐의 정렬 정책에 따라 달라짐
import java.util.LinkedList;
import java.util.Queue;
public class QueueTest {
public static void main(String[] ars) {
Queue<Integer> q = new LinkedList<>();
for (int i = 0; i < 5; i++)
q.add(i);
System.out.println("큐의 요소: " + q);
int e = q.remove();
System.out.println("삭제된 요소: " + e);
System.out.println(q);
}
}
// 큐의 요소: [0, 1, 2, 3, 4]
// 삭제된 요소: 0
// [1, 2, 3, 4]
17-1) 우선순위 큐
원소들이 무작위로 삽입되었더라도 정렬된 상태로 추출
remove()를 호출할 때마다 가장 작은 원소가 추출됨
import java.util;
public class PriorityQueueTest {
public static void main(String[] args) {
PriorityQueue<Integer> pq = new PriorityQueue<Integer>();
pq.add(30);
pq.add(80);
pq.add(20);
System.out.println(pq);
System.out.println("삭제된 원소: " + pq.remove());
}
}
// [20, 80, 30]
// 삭제된 원소: 20
18. Collection 클래스
여러 유용한 알고리즘을 구현한 메소드들 제공
18-1) 정렬 sorting
List<String> list = new LinkedList<String>();
list.add("철수");
list.add("영희");
Collections.sort(list); // 리스트 안 문자열이 정렬됨
리스트 안의 문자열 정렬
import java.util.*;
public class Sort {
public static void main(String[] args) {
String[] sample = {"i", "walk", "the", "line"};
List<String> list = Arrays.asList(sample); // 배열을 리스트로 변경
Collections.sort(list);
System.out.println(list);
}
}
// [i, line, the, walk]
사용자 클래스의 객체 정렬
import java.util.*;
class Student implements Comparable<Student> {
int number;
String name;
public Student(int number, String name) {
this.number = number;
this.name = name;
}
public String toString() { return name; }
public int compareTo(Student s) {
return s.number - number;
}
}
public class SortTest {
public static void main(String[] args) {
Student array[] = {
new Student(2, "김철수");
new Student(3, "이철수");
new Student(1, "박철수");
};
List<Student> list = Arrays.asList(array);
Collections.sort(list);
System.out.println(list);
}
}
// [박철수, 김철수, 이철수]
18-2) 섞기 shuffling
정렬의 반대 동작
리스트에 존재하는 정렬을 파괴해서 원소들의 순서를 랜덤하게 만듦
import java.util.*;
public class Shuffle {
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>();
for(int i = 1; i <= 10; i++)
list.add(i);
Collections.shuffle(list);
System.out.println(list);
}
}
// [5, 9, 7, 3, 6, 4, 8, 2, 1, 10]
18-3) 탐색 searching
리스트 안에서 원하는 원소를 찾는 것
선형 탐색 : 정렬되어 있지 않은 경우 처음부터 모든 원소를 방문하는 방법
이진 탐색 : 정렬되어 있는 경우 중간에 있는 원소와 먼저 비교하는 방법
import java.util.*;
public class Search {
public static void main(String[] args) {
int key = 50;
List<Integer> list = new ArrayList<Integer>();
for(int i = 0; i < 100; i++)
list.add(i);
int index = Collections.binarySearch(list, key);
System.out.println("탐색의 반환값: " + index);
}
}
// 탐색의 반환값: 50