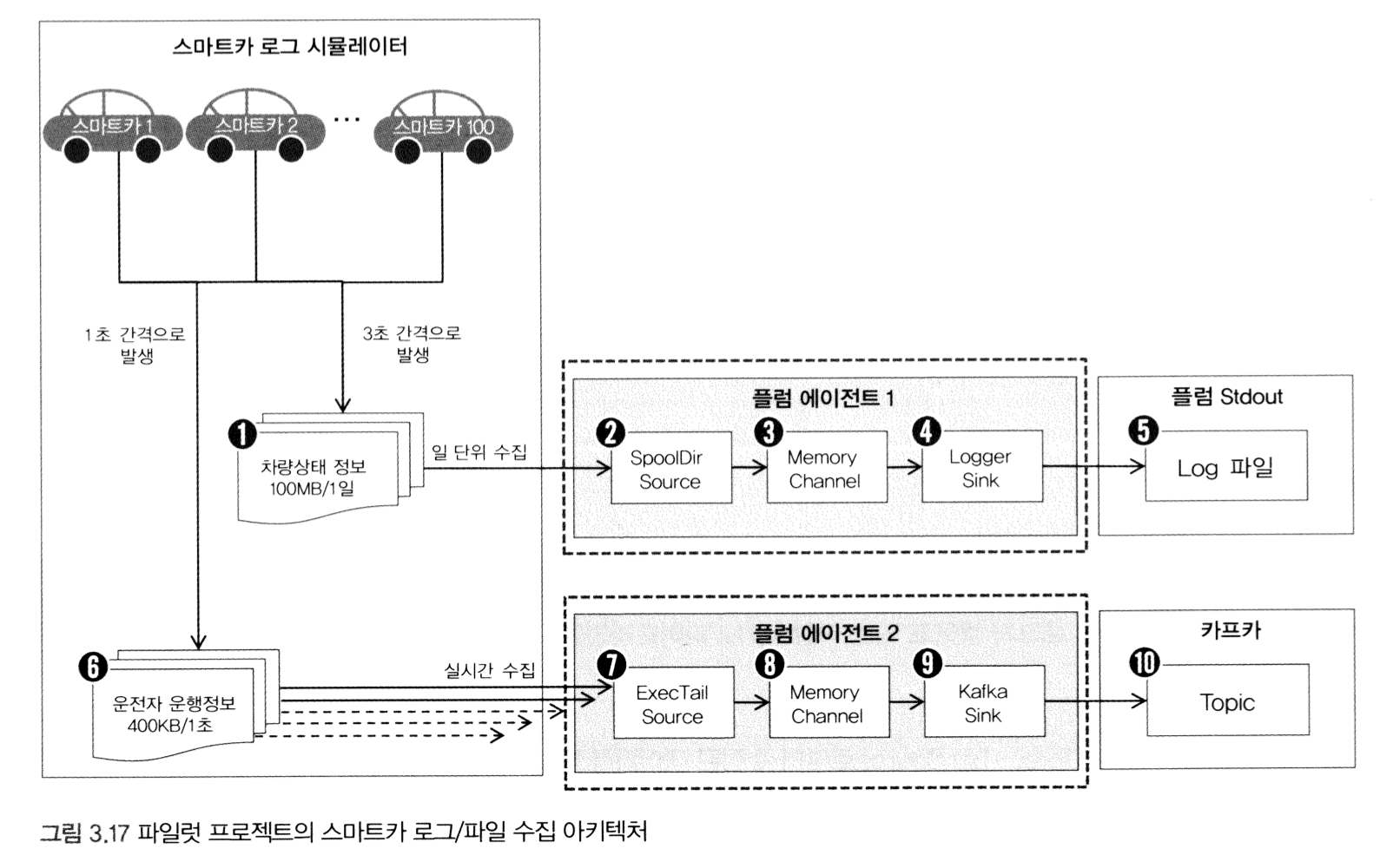
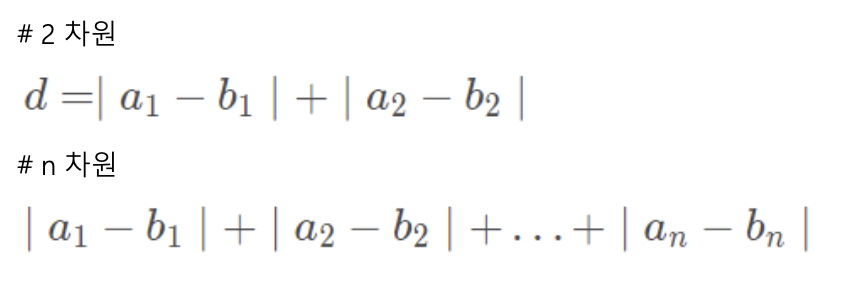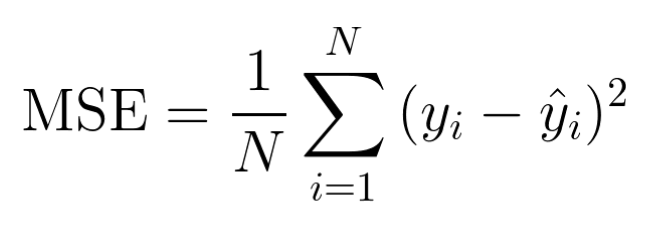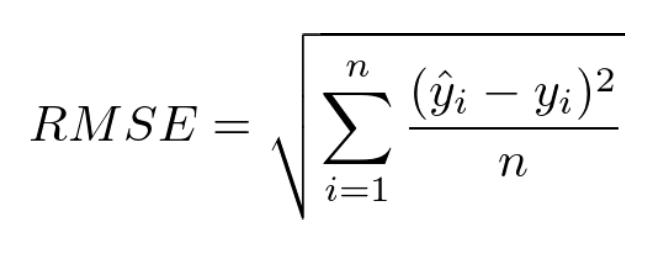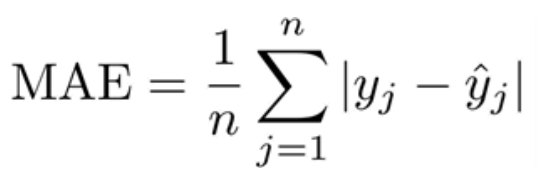import java.util.Scanner;
publicclassJ1085{
publicstaticvoidmain(String[] args){
Scanner sc = new Scanner(System.in);
int x = sc.nextInt();
int y = sc.nextInt();
int w = sc.nextInt();
int h = sc.nextInt();
int left = x;
int right = w-x;
int up = h-y;
int down = y;
int[] arr = {left, right, up, down};
int min = arr[0];
for(int num : arr) {
if(num < min) {
min = num;
}
}
System.out.print(min);
}
}
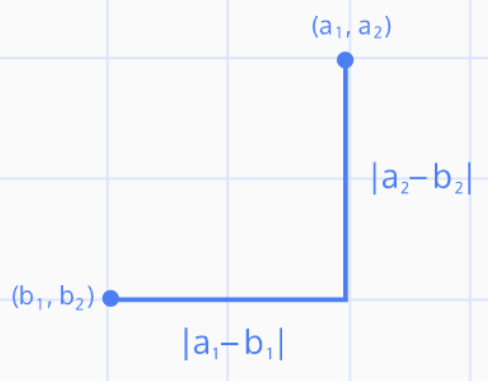
- 독립변수 x에 대응하는 종속변수 y와 가장 유사한 값을 갖는 함수 f(x)를 찾는 과정
→ f(x)를 통해 미래 사건 예측
^y = f(x) ≈ y
- 회귀 분석을 통해 구한 함수 f(x)가 선형 함수일 때 f(x) = 회귀 직선
- 선형 회귀 분석
- 특성과 타겟 사이의 관계를 잘 나타내는 선형 회귀 모형을 찾고, 이들의 상관관계는 가중치/계수(m), 편향(b)에 저장됨
=> ^y = w * x + b
2. 비용 함수 = 손실 함수
- 선형 모델의 예측과 훈련 데이터 사이의 거리를 재는 함수
- 비용 함수의 결과값이 작을수록 선형 모델의 예측이 정확함
- 선형 회귀는 선형 모델이라는 가설을 세우는 방식이므로, 실제 데이터(훈련 데이터)와 선형 모델의 예측 사이에 차이 존재
- 실제 데이터와 선형 모델의 예측 사이의 차이를 평가하는 함수 → 비용 함수를 사용하여 정확도 계산
- MSE 가장 많이 사용 [실제값과 예측값의 차이인 오차들의 제곱의 평균]
3. 선형 회귀 구현
1) 선형 회귀 모델 구현
# 훈련 세트, 테스트 세트 생성from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight, random_stae = 42)
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
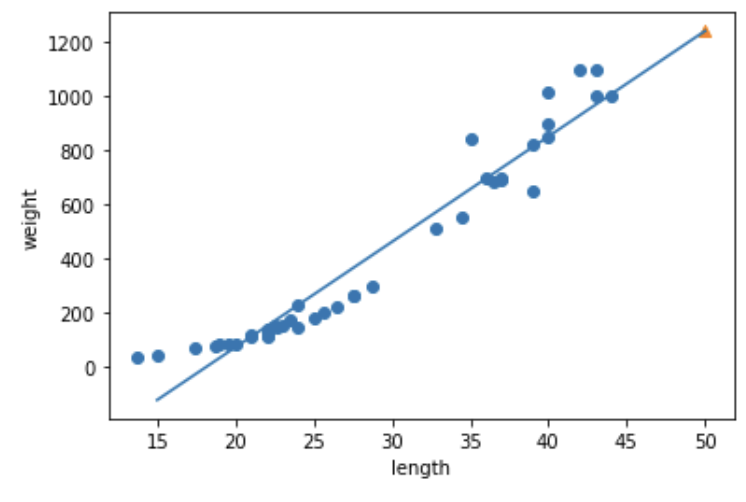
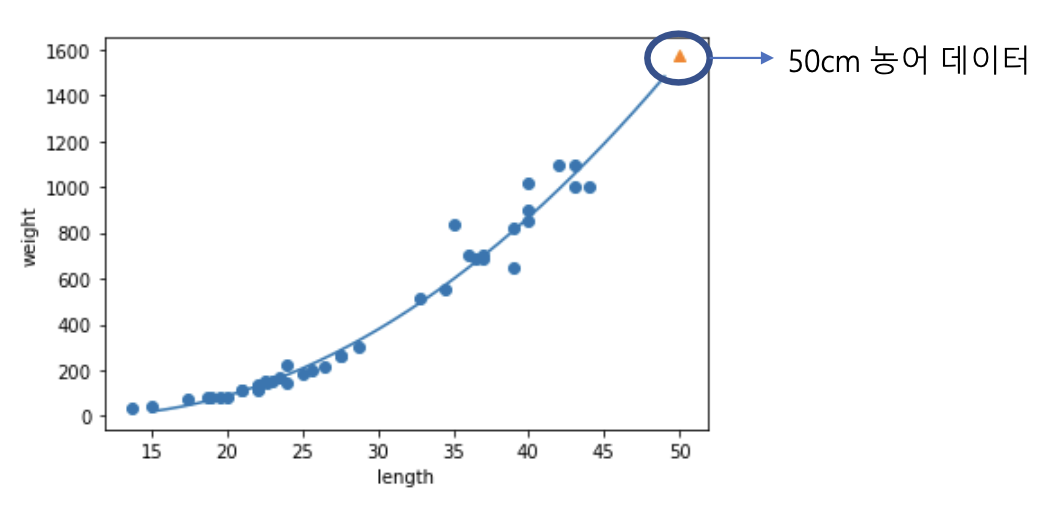
# 50cm 농어 평균 무게 예측from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_input, train_target)
print(lr.predict([50]))
# 1241.83860323
2) 회귀 확인
# 회귀 직선 ^y = W * x + b 구하기print(lr.coef_, lr.intercept_)
# [39.01714496], -709.0186449535477# => y = lr.coef_ * x + lr.intercept_
plt.plot([15, 50], [15*lr.coef_+lr.intercept_, 50*lr.coef_+lr.intercept_])
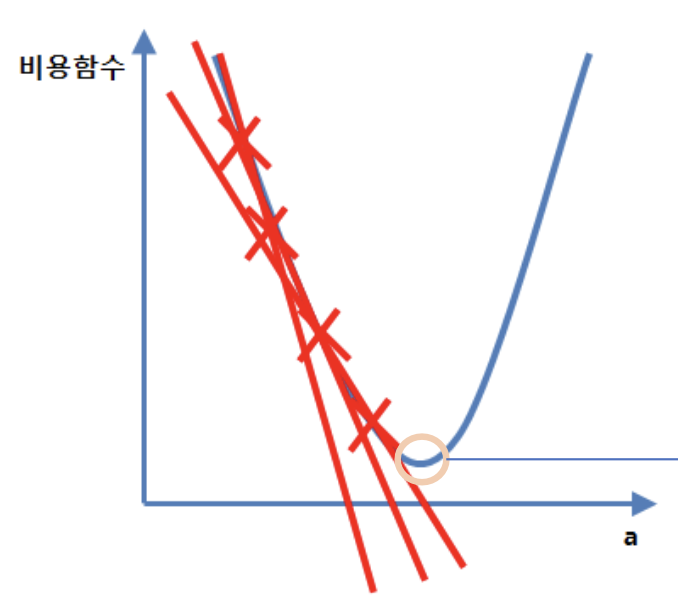
- 비용 함수의 기울기를 계속 낮은 쪽으로 이동시켜 극값(최적값)에 이를 때까지 반복하는 것
- 경사 하강법을 이용하여 비용 함수에서 기울기가 '0'일 때의 비용(오차)값을 구할 수 있음
- 비용 함수의 최소값을 구하면 이때 회귀 함수를 최적화 할 수 있게 됨
- 비용 함수에서 기울기가 '0'일 때 (비용 함수가 최솟값일 때) 모델의 기울기와 y절편을 구하여 회귀 함수 최적화
5. 경사 하강법 - learning rate(학습률)
- 선형 회귀에서 가중치(w)와 편향(b)을 경사 하강법에서 반복 학습시킬 때, 한 번 반복 학습시킬 때마다 포인트를 얼만큼씩 이동시킬 것인지 정하는 상수
- 학습률이 너무 작은 경우: local minimum에 빠질 수 있음
- 학습률이 너무 큰 경우: 수렴이 일어나지 않음
=> 적당한 learning rate를 찾는 것이 중요!
- 시작을 0.01로 시작해서 overshooting이 일어나면 값을 줄이고, 학습 속도가 매우 느리다면 값을 올리는 방향으로 진행
import numpy as np
import matplotlib.pyplot as plt
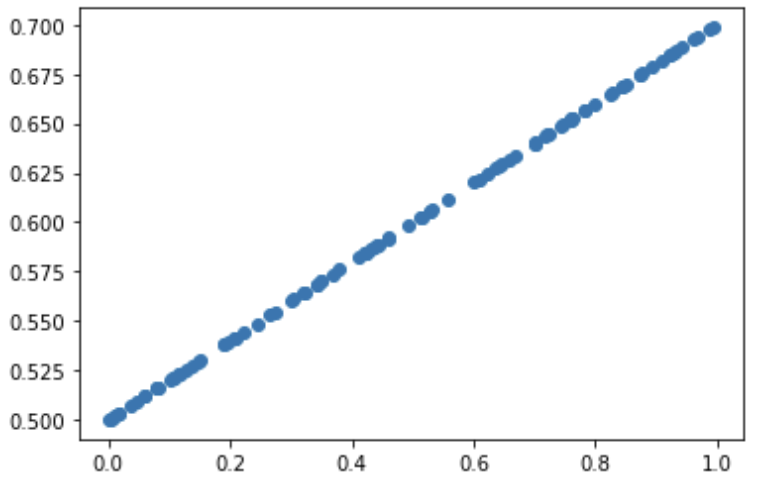
X = np.random.rand(100)
Y = 0.2 * X + 0.5# 실제값 함수 가정
plt.figure()
plt.scatter(X, Y)
plt.show()
# 실제값, 예측값 산점도 그리는 함수defplot_prediction(pred, y):
plt.figure()
plt.scatter(X, Y)
plt.scatter(X, pred)
plt.show()
# 경사 하강법 구현
W = np.random.uniform(-1, 1)
b = np.random.uniform(-1, 1)
learning_rate = 0.7# 임의for epoch inrange(100):
Y_pred = W * X + b # 예측값
error = np.abs(Y_pred - Y).mean()
if error < 0.001:
break# gradient descent 계산 (반복할 때마다 변경되는 W, b값)
w_grad = learning_rate * ((Y_pred-Y) * X).mean()
b_grad = learning_rate * ((Y_pred-Y)).mean()
# W, b 값 갱신
W = W - w_grad
b = b - b_grad
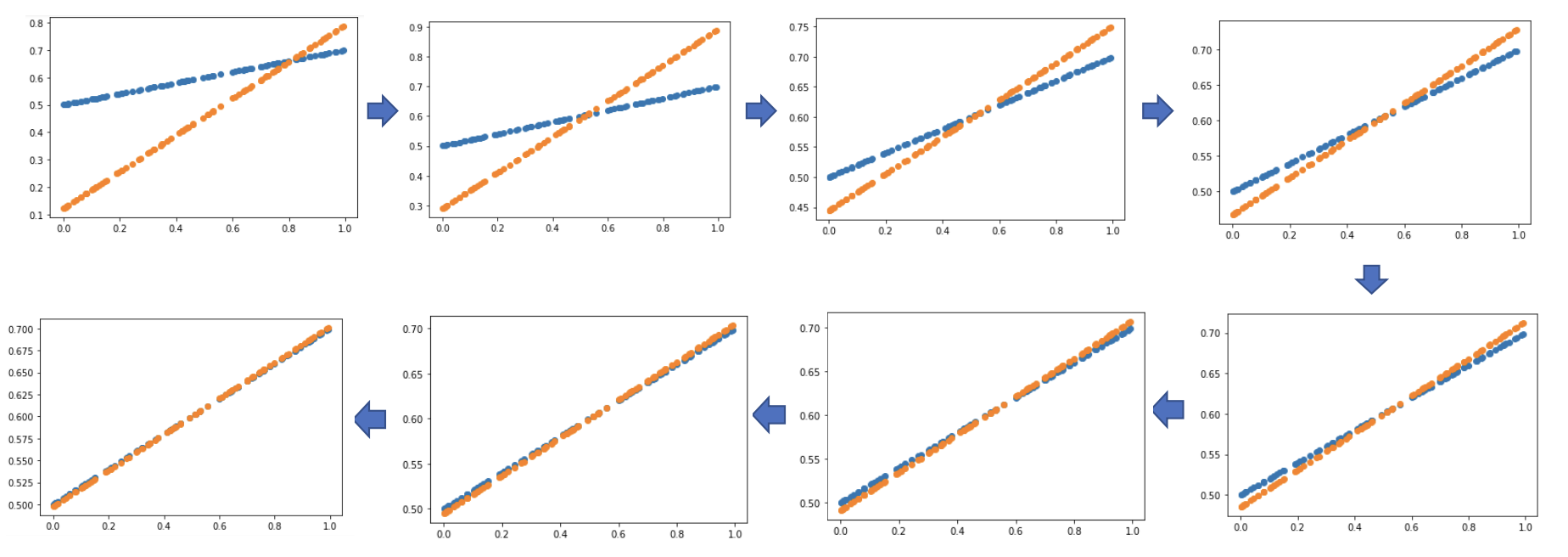
# 실제값과 예측값이 얼마나 근사해지는지 epoch % 5 ==0 될 때마다 그래프 그림if epoch % 5 == 0:
Y_pred = W * X + b
plot_prediction(Y_pred, Y)
[파랑: 실제값, 주황: 예측값]
- 반복문이 실행되면서 오차가 점차 작아짐을 알 수 있음
- 최종적으로 오차가 줄어들며 실제값을 정확히 추정할 수 있음!
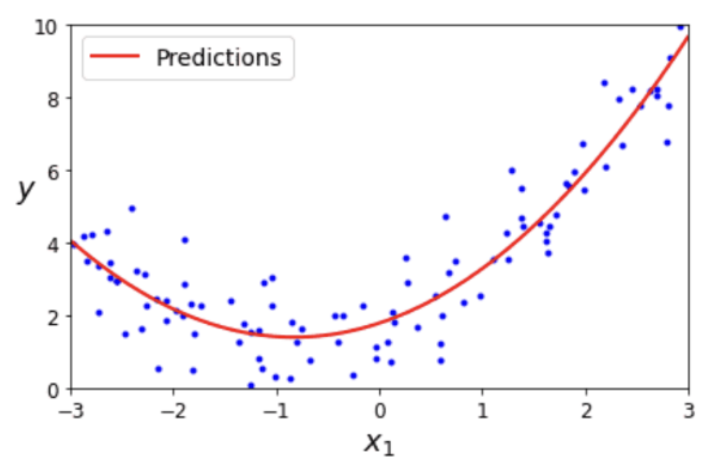
6. 다항 회귀
- 다항식을 사용한 선형 회귀
- y = a * x² + b * x + c 에서 x²을 z로 치환하면 y = a * z + b * x + c라는 선형식으로 쓸 수 있음
=> 다항식을 이용해서도 선형 회귀를 할 수 있음 → 최적의 곡선 찾기
- 비선형성을 띄는 데이터도 선형 모델을 활용하여 학습시킬 수 있다는 것
- 다항 회귀 기법: log, exp, 제곱 등을 적용해 선형식으로 변형한 뒤 학습시키는 것
위의 선형회귀 모델의 문제점 해결
# 50cm 농어 평균 무게 예측# 훈련 세트, 테스트 세트의 길이를 제곱한 값의 열 추가 - 새로운 훈련, 테스트 세트 생성
train_poly = np.column_stack((train_input**2, train_input))
test_poly = np.column_statck((test_input**2, test_input))
# 새로운 훈련 세트, 테스트 세트로 선형 회귀 모델 훈련
lr = LinearRegression()
lr.fit(train_poly, train_target)
# 무게 예측print(lr.predict([50**2, 50]))
# [1573.98423528]
classsklearn.neighbors.KNeighborsRegressor(n_neighbhors=5, *, weights='uniform', algorithm='auto',
leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None):'''
n_neighbors: 이웃의 수 K (defualt = 5)
weights: 예측에 사용되는 가중 방법 결정 (default = 'uniform') or callable
"uniform" : 각각의 이웃이 모두 동일한 가중치
"distance" : 거리가 가까울수록 높은 가중치
callable : 사용자가 직접 정의한 함수 사용
algorithm('auto', 'ball_tree', 'kd_tree', 'brute') : 가장 가까운 이웃을 계산할 때 사용할 알고리즘
"auto" : 입력된 훈련 데이터에 기반해 가장 적절한 알고리즘 사용
"ball_tree" : Ball-Tree 구조
"kd_tree" : KD-Tree 구조
"brute" : Brute-Force 탐색 사용
leaf_size : Ball-Tree나 KD-Tree의 leaf size 결정 (default = 30)
- 트리를 저장하기 위한 메모리, 트리의 구성과 쿼리 처리 속도에 영향
p : 민코프스키 미터법의 차수 결정 (1이면 맨해튼 거리, 2이면 유클리드 거리)
'''
from sklearn.neighbors import KNeighborRegressor
knr = KNeighborsRegressor()
knr.fit(train_input, train_target)
knr.score(test_input, test_target) # 테스트 모델에 대한 평가# 0.9928094061
test_prediction = knr.predict(test_input) # 테스트 세트에 대한 예측
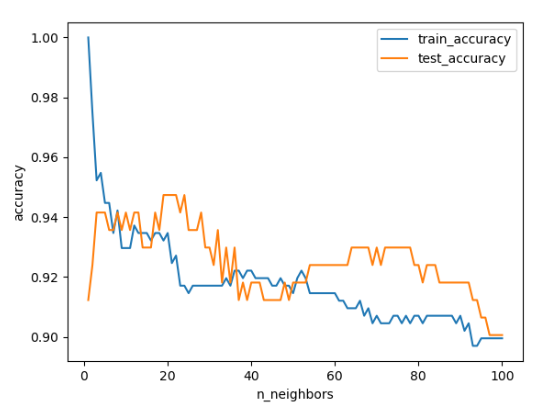
knr.score(train_input, train_target) # 훈련 모델에 대한 평가# 0.9698823289 이 경우는 과소적합 (훈련 < 테스트 점수)
knr.n_neighbors = 3# 모델을 훈련세트에 잘 맞게 하기 위해 k 줄임 (5→3)
knr.fit(train_input, train_target) # 재훈련
knr.score(train_input, train_target)
# 0.9804899950
knr.score(test_input, test_target)
# 0.9746459963 # 훈련 > 테스트 점수이고, 차이가 크지 않으므로 적합!
knr.KNeighborRegressor()
x = np.arange(5, 45).reshape(-1, 1)
knr.n_neighbors = 3
knr = KNeighborsRegressor()
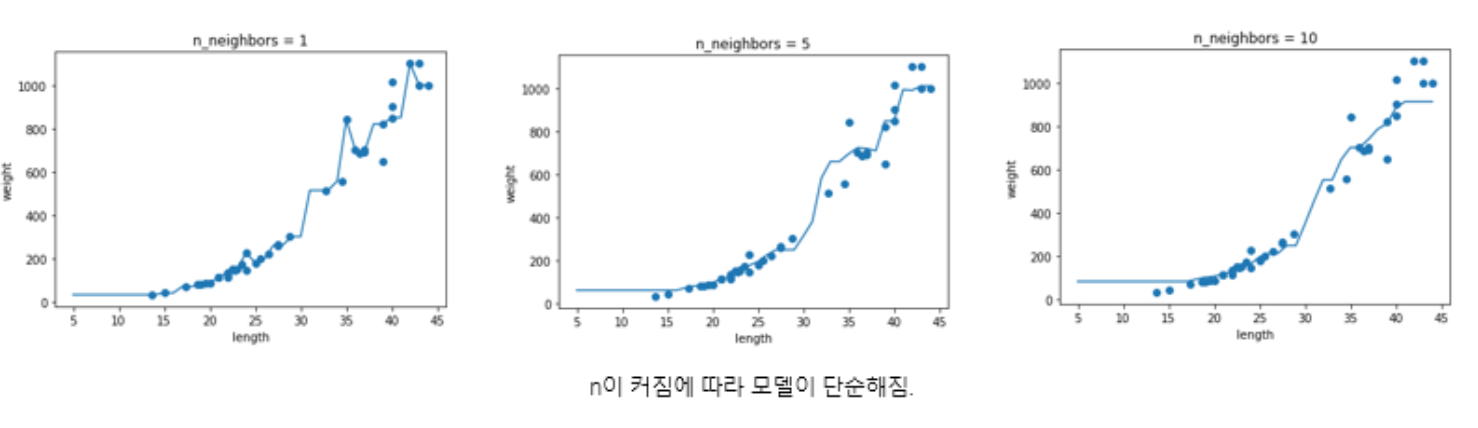
x =np.arange(5, 45).reshape(-1, 1) # 5에서 45까지 x 좌표 생성 for n in [1, 5, 10]:
knr.n_neighbors = n
knr.fit(train_input, train_target) # 모델 훈련
prediction = knr.predict(x) # 지정한 범위 x에 대한 예측
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.title('n_neighbors = {}'.format(n))
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
df = df.dropna(how = 'all')
df = df.dropna(thresh = 1)
df = df.dropna(subset=['col1', 'col2', 'col3'], how = 'all') # 모두 결측치일 때 해당 행 삭제
df = df.dropna(subset=['col1', 'col2', 'col3'], thresh = 2) # 특정 열에 2개 초과의 결측치가 있을 때 해당 행 삭제
5-2) 대치
- 단순 대치: 중앙값, 최빈값, 0, 분위수, 주변값, 예측값 등으로 결측치 대치
- 다중 대치: 단순 대치법을 여러번! (대치 - 분석 - 결합)
- 판다스에서 결측치 대치하는 함수들
fillna()
# 전체 결측치를 특정 단일값으로 대치
df.fillna(0)
# 특정 열에 결측치가 있을 경우 다른 값으로 대치
df['col'] = df['col'].fillna(0)
df['col'] = df['col'].fillna(df['col'].mean())
# 결측치 바로 이후 행 값으로 채우기
df.fillna(method='bfill')
# 결측치 바로 이전 행 값으로 채우기
df.fillna(method='pad')
replace()
# 결측치 값 0으로 채우기
df.replace(to_replace = np.nan, value = 0)
interpolate()
# 인덱스를 무시하고, 값을 선형적으로 같은 간격으로 처리
df.interpolate(method = 'linear', limit_direction = 'forward')
5-3) 예측 모델
- 결측값을 제외한 데이터로부터 모델을 훈련하고 추정값을 계산하고 결측치 대체
- K-NN, 가중 K-NN, 로지스틱 회귀, SVM, 랜덤 포레스트 방식 등
7. 중복 데이터 처리
- 중복은 언제든지 발생할 수 있지만, 중복 데이터 사이에 속성의 차이나 값의 불일치가 발생한 경우, 처리해야 함
- 두 개체를 합치거나 응용에 적합한 속성을 가진 데이터를 선택하는 등
# 중복 데이터 확인
df.duplicated(['col'])
# 중복 데이터 삭제
drop_duplicates()
# 해당 열의 첫 행을 기준으로 중복 여부 판단 후, 중복되는 나머지 행 삭제
drop_duplicated(['col'])
df.drop_duplicates(keep = )
subset = None# default, 특정 열 지정 X, 모든 열에 대해 작업 수행
keep = 'first'# 가장 처음에 나온 데이터만 남김
keep = 'last'# 가장 마지막에 나온 데이터만 남김
keep = False# 중복된 어떤 데이터도 남기지 않음
8. 불균형 데이터 처리
- 분류를 목적으로 하는 데이터 셋에 클래스 라벨의 비율이 불균형한 경우
- 각 클래스에 속한 데이터 개수 차이가 큰 데이터
- 정상 범주의 관측치 수와 이상 범주의 관측치 수가 현저히 차이나는 데이터
- 이상 데이터를 정확히 찾아내지 못할 수 있음
8-1) Under Sampling
- 다수 범주의 데이터를 소수 범주의 데이터 수에 맞게 줄이는 샘플링 방식
- Random Undersampling, Tomek's Link, CNN
8-2) Over Sampling
- 소수 범주의 데이터를 다수 범주의 데이터 수에 맞게 늘리는 샘플링 방식
- Random Oversampling
- ADASYN, SMOTE
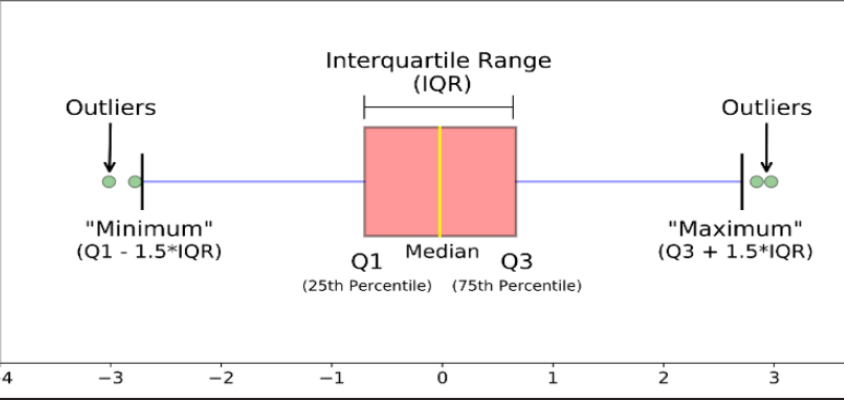
9. 이상치 탐지 기법
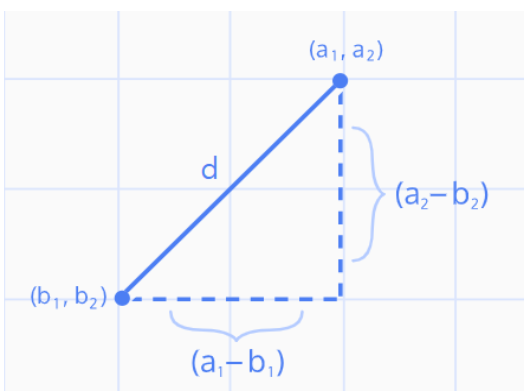
1) z-score
- z = (x - μ) / σ
- 변수가 정규분포 따른다고 가정, 각 특성값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지 나타냄
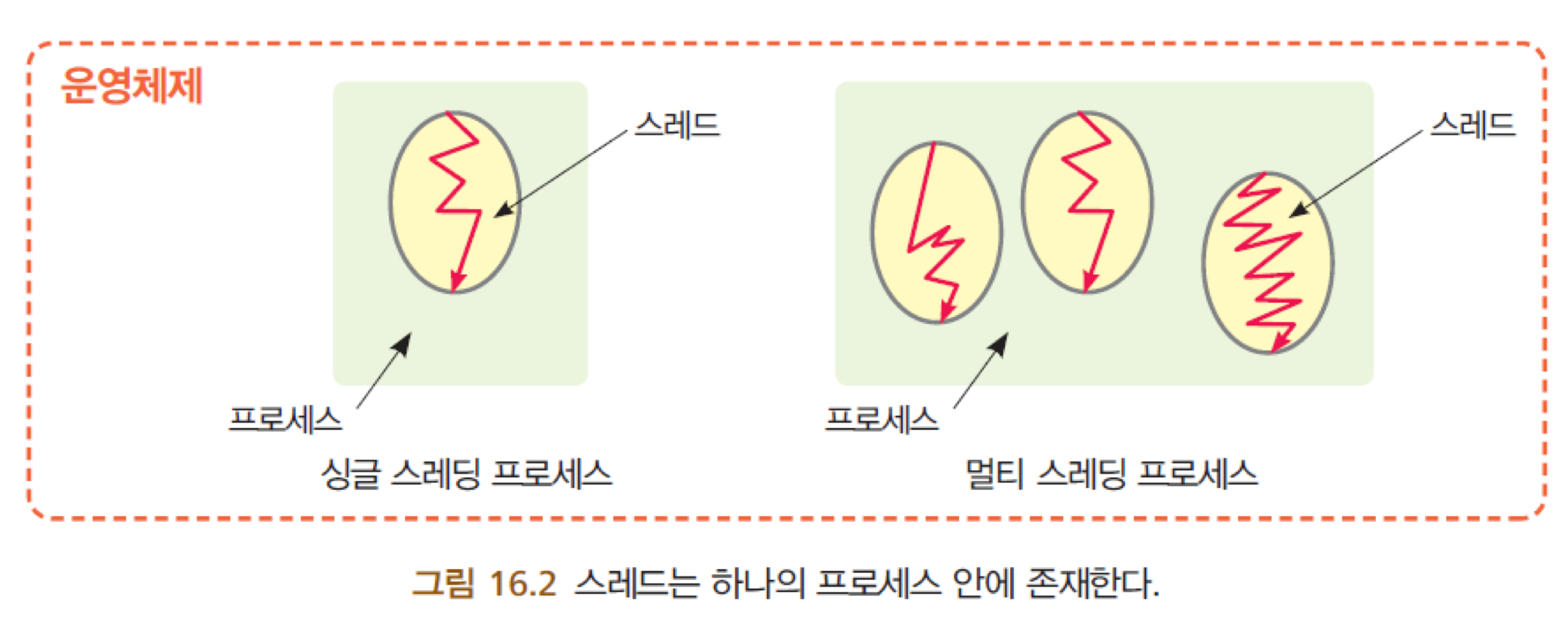
classMyThreadextendsThread{
publicvoidrun(){
for (int i = 0; i <= 10; i++)
System.out.print(i + " ");
}
}
publicclassMyThreadTest{
publicstaticvoidmain(String args[]){
Thread t = new MyThread();
t.start();
}
}
// 0 1 2 3 4 5 6 7 8 9 10
3-2) 스레드 생성: Runnable 인터페이스 구현하는 방법
- Runnable 인터페이스를 구현한 클래스 작성
- run() 메소드 작성
- Thread 객체 생성하고 Runnable 객체 인수로 전달
- start() 호출해서 스레드 시작
classMyRunnableimplementsRunnable{
publicvoidrun(){
for (int i = 0; i <= 10; i++)
System.out.print(i + " ");
}
}
publicclassMyRunnableTest{
publicstaticvoidmain(String[] args){
Thread t = new Thread(new MyRunnable());
t.start();
}
}
// 0 1 2 3 4 5 6 7 8 9 10
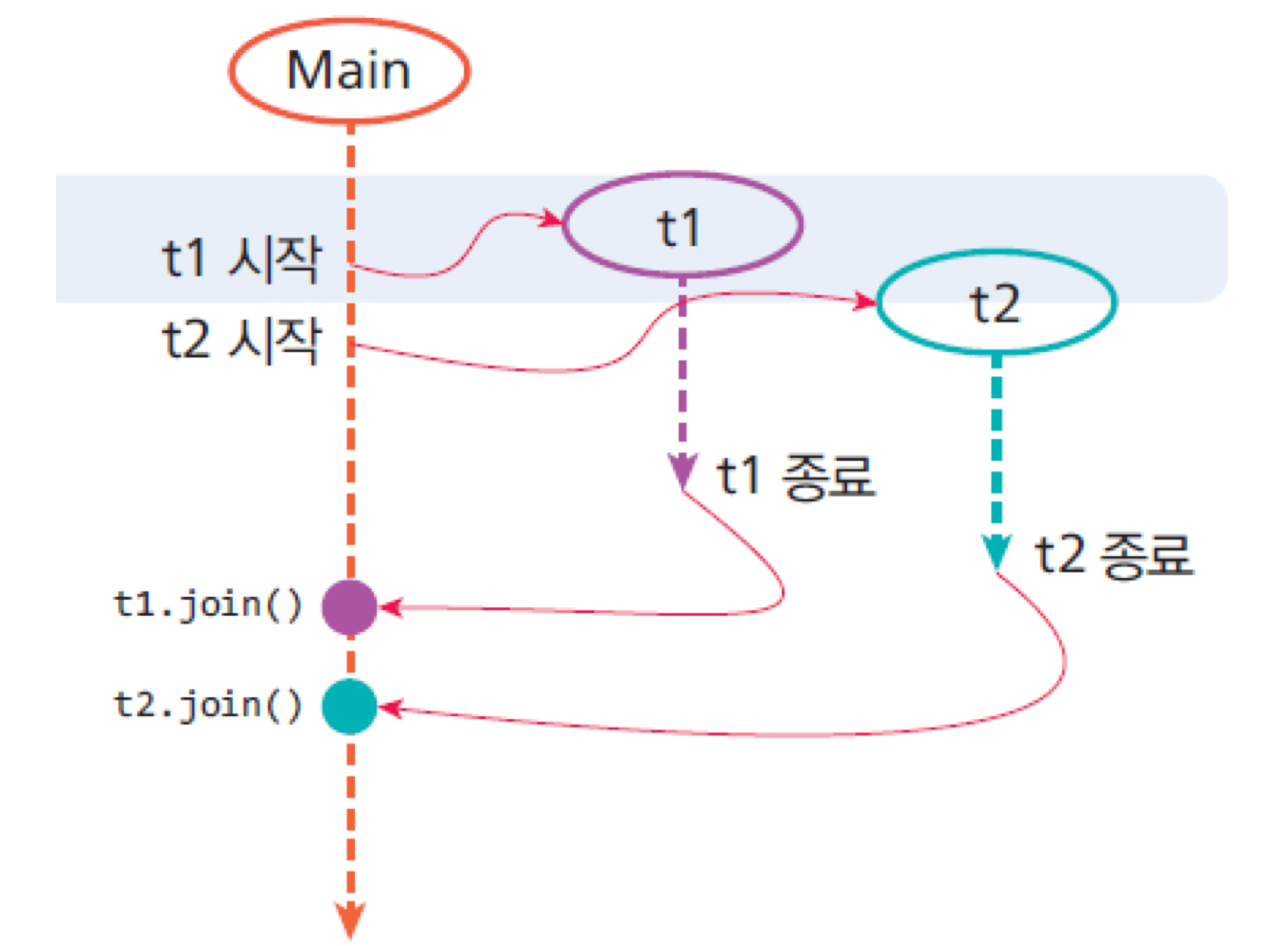
- 스레드 2개 예제
classMyThreadextendsThread{
publicvoidrun(){
for (int i = 0; i < 10; i ++) {
System.out.print(i + " ");
}
}
}
classMyRunnableimplementsRunnable{
publicvoidrun(){
for (int i = 0; i < 30; i ++) {
System.out.print("[" + i + "]");
}
}
}
publicclassThreadTest{
publicstaticvoidmain(String[] args)throws InterruptedException {
System.out.println("main start");
MyThread mt = new MyThread();
mt.start();
MyThread mt2 = new MyThread();
mt2.start();
Thread t = new Thread(new MyRunnable()); // runnable -바로 스타트 불가.
t.start();
// 모든 작업이 끝났을 때 종료 메세지를 출력하고 싶은 경우
mt.join();
mt2.join();
t.join(); // 끝날 때까지 기다리기
System.out.println("\nmain end");
}
}
/**
main start
0 1 2 3 4 0 5 6 7 8 9 1 2 3 4 5 6 7 8 9 [0][1][2][3][4][5][6][7][8][9][10][11][12][13][14][15][16][17][18][19][20][21][22][23][24][25][26][27][28][29]
main end
**/
- 람다식 이용한 스레드 작성
publicclassLambdaTest{
publicstaticvoidmain(String[] args){
Runnable task = () -> {
for (int i = 0; i <= 10; i++)
System.out.print(i + " ");
};
new Thread(task).start();
}
}
// 0 1 2 3 4 5 6 7 8 9 10
4. 스레드 상태
- New : Thread 클래스의 인스턴스는 생성되었지만, start() 메소드를 호출하기 전
- Runnable : start() 메소드가 호출되어 실행 가능한 상태, 하지만 아직 스케줄러가 선택하지 않았으므로 실행 상태는 아님
- 실행 가능 상태 : 스레드가 스케줄링 큐에 넣어지고, 스케줄러에 의해 우선순위에 따라 실행
- 실행 중지 상태
- 스레드나 다른 스레드가 suspend()를 호출하는 경우
- 스레드가 wait() 호출하는 경우
- 스레드가 sleep() 호출하는 경우
- 스레드가 입출력 작업을 하기 위해 대기하는 경우
5. 스레드 스케줄링
- 대부분 스레드 스케줄러는 선점형 스케줄링과 타임 슬라이싱을 사용해 스레드 스케줄링
- 어떤 스케줄링을 선택하느냐는 JVM에 의해 결정됨
6. 스레드 우선순위
- 1 ~ 10 사이의 숫자료 표시됨
- 기본 우선순위 : NORM_PRIORITY(5)
- MIN_PRIORITY(1)
- MAX_PRIORITY(10)
- void setPriority(int newPriority) : 현재 스레드의 우선 순위 변경
- getPriority() : 현재 스레드의 우선 순위 반환
7. sleep()
- 지정된 시간동안 스레드 재움
- 스레드가 수면 상태로 있는 동안 인터럽트되면 InterruptedException 발생
- 4초 간격으로 메시지 출력
publicclassSleepTest{
publicstaticvoidmain(String[] args)throws InterruptedException {
String messages[] = {"Hello.",
"My name is A.",
"I'm majoring in computer science.",
"I'm taking a JAVA class."};
for (int i = 0; i < messages.length; i++) {
Thread.sleep(4000);
System.out.println(messages[i]);
}
}
}
/**
Hello.
My name is A.
I'm majoring in computer science.
I'm taking a JAVA class.
**/
8. join()
- 스레드가 종료될 때까지 기다리는 메소드
- 특정 스레드가 작업을 완료할 때까지 현재 스레드의 실행을 중지하고 기다리는 것
9. 인터럽트와 yield()
- 인터럽트 : 하나의 스레드가 실행하고 있는 작업을 중지하도록 하는 메커니즘 -> 대기 상태나 수면 상태가 됨
- yield() : CPU를 다른 스레드에게 양보하는 메소드
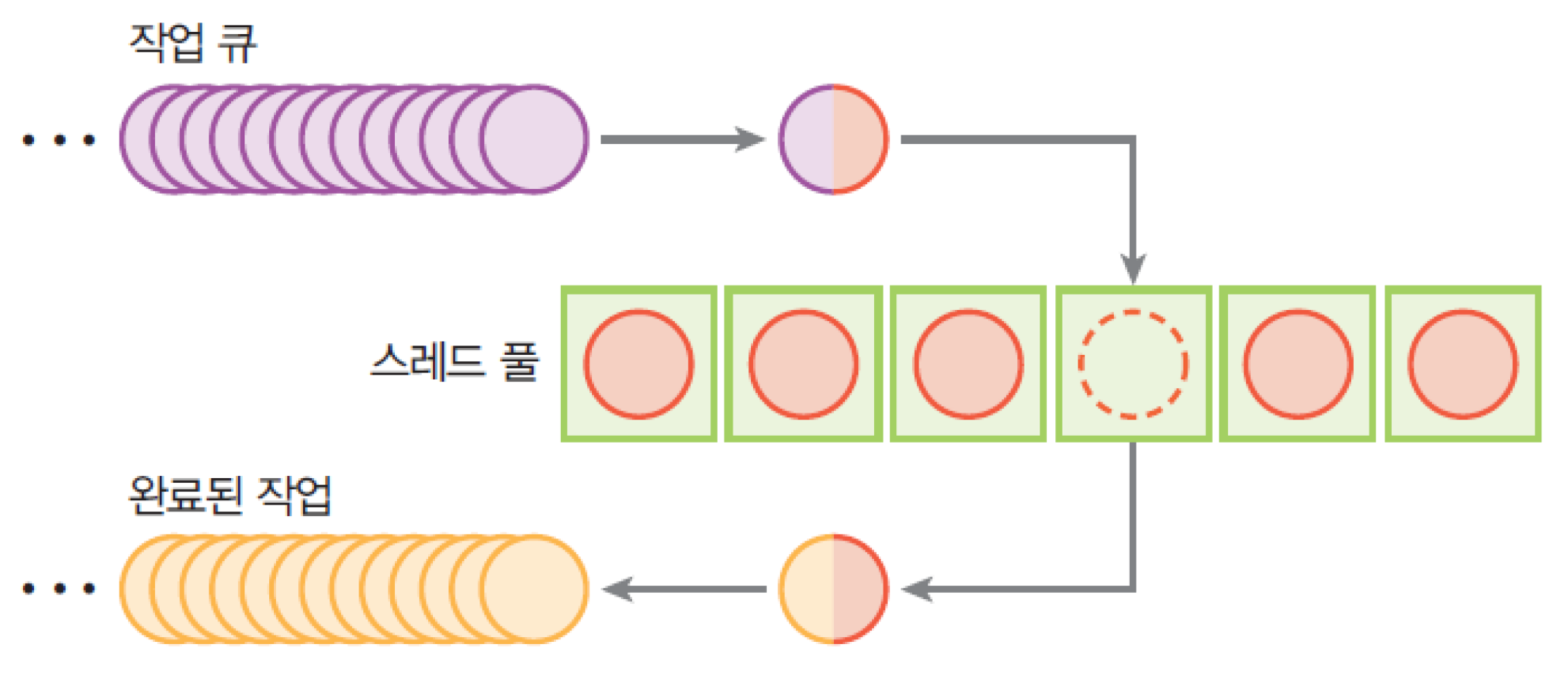
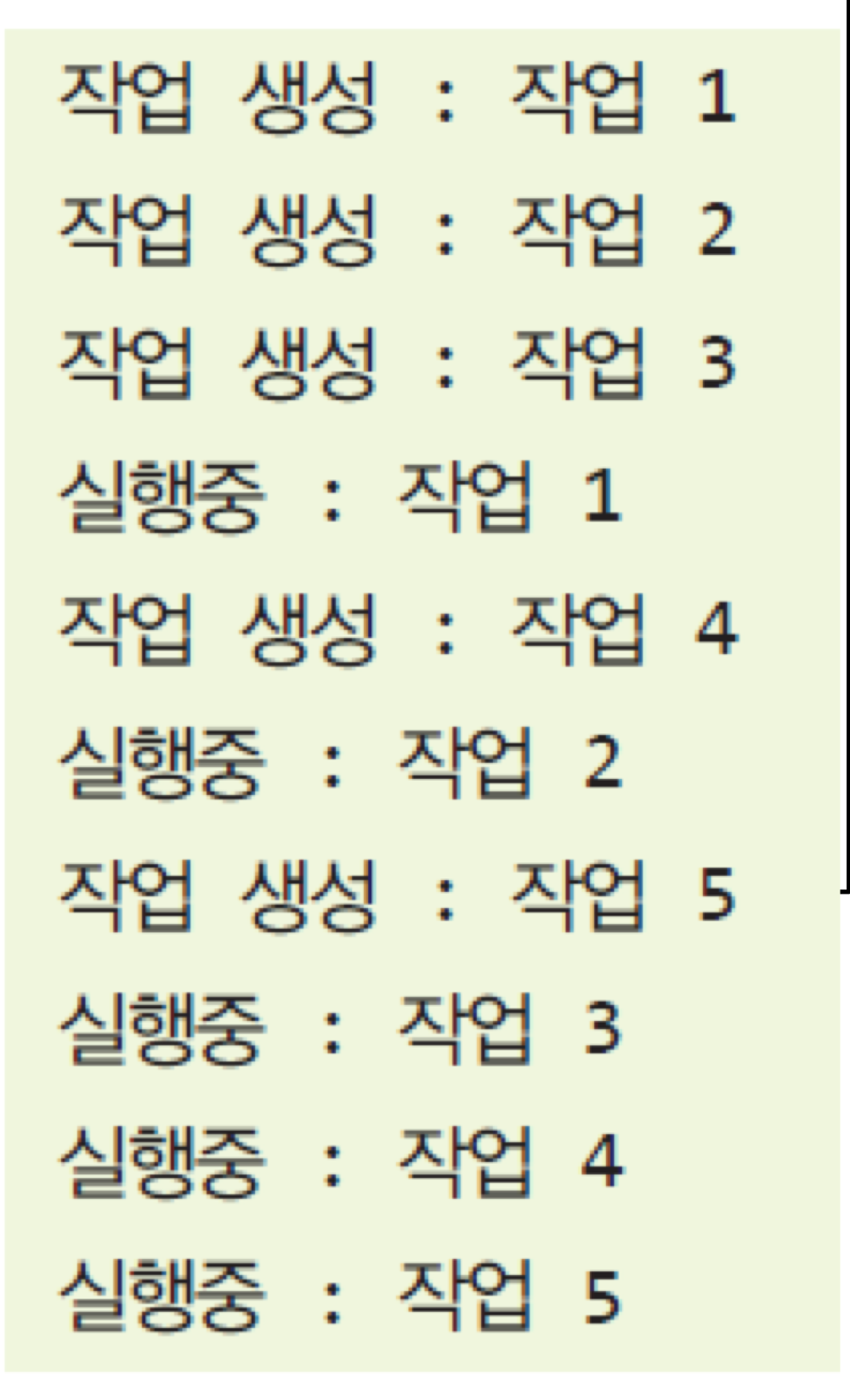
10. 자바 스레드 풀
- 스레드 풀 : 미리 초기화된 스레드들이 모여 있는 곳
- 스레드 풀의 동일한 스레드를 사용하여 N개의 작업을 쉽게 실행할 수 있음
- 스레드의 개수보다 작업의 개수가 더 많은 경우, 작업은 FIFO 큐에서 기다려야 함
- Java5 부터 자바 API는 Executor 프레임워크 제공
-> 개발자는 Runnable 객체를 구현하고 ThreadPoolExecutor로 보내기만 하면 됨
import java.io.*;
publicclassDataStreamTest{
publicstaticvoidmain(String[] args)throws IOException {
DataInputStream in = null;
DataOutputStream out = null;
try {
out = new DataOutputStream(new FileOutputStream("data.bin"));
out.writeInt(123);
out.writeFloat(123.456F);
out.close();
in = new DataInputStream(new FileInputStream("data.bin"));
int aint = in.readInt();
float afloat = in.readFloat();
System.out.println(aint);
System.out.println(afloat);
}
finally { // 예외에 상관없이 실행if (in != null) // in이 생성 되어있다면
in.close();
if (out != null)
out.close();
}
}
}
// 123// 123.456
5. 버퍼 스트림
- 버퍼 입력 스트림: 입력 장치에서 한번에 많이 읽어서 버퍼에 저장, 입력을 요구하면 버퍼에서 꺼내서 반환함
- 버퍼가 비었을 때만 입력 장치에서 읽음
inputStream = new BufferedReader(new FileReader("input.txt"));
outputStream = new BufferedWriter(new FileWriter("output.txt"));
- 줄 단위로 복사하기 (BufferedReader, PrintWriter 클래스 사용)
import java.io.*;
publicclassCopyLines{
publicstaticvoidmain(String[] args){
try (BufferedReader in = new BufferedReader(new FileReader("test.txt"))) {
PrintWriter out = new PrintWriter(new FileWriter("output.txt"))) {
String line;
while ((line = in.readLine()) != null) {
out.println(line);
}
} catch(IOException e) {
e.printStackTrace();
}
}
}
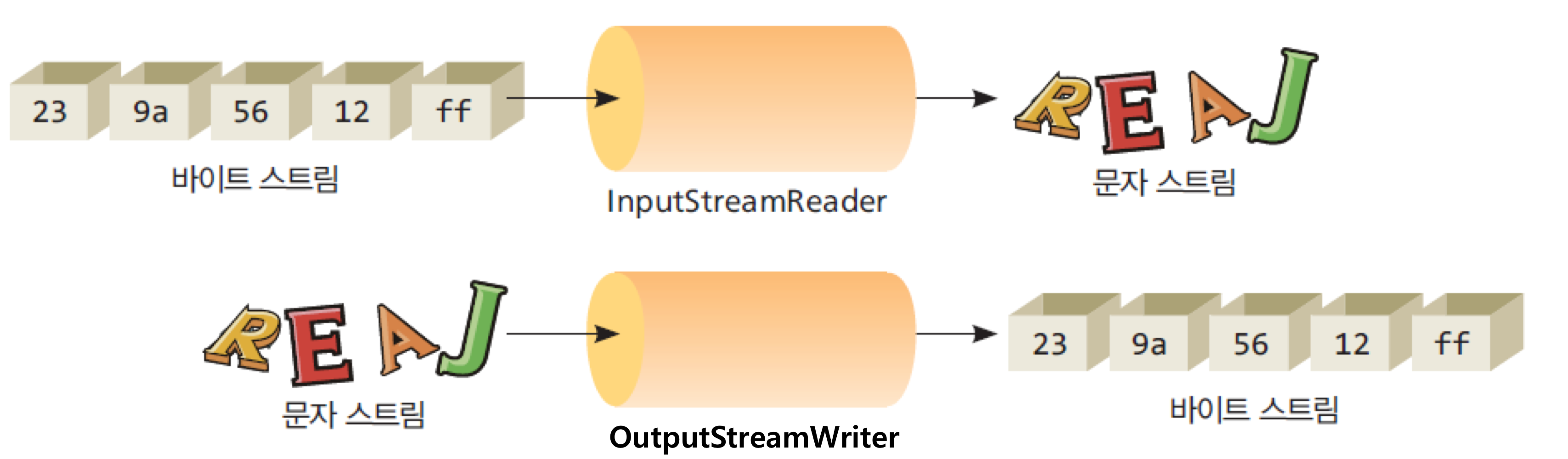
6. InputStreamReader, OutputStreamWriter 클래스
- 바이트 스트림과 문자 스트림을 연결하는 두 개의 범용 브릿지 스트림
6-1) 한글 코드
- ASCII
- EUC-KR : 한글 완성형, 16비트, 국내 규격
- CP949 (MS949) : 한글 지원을 위해 MS 윈도우 계열에서 등장한 확장 완성형 인코딩 방식, ANSI
- 유니코드 : 전 세계에서 사용하는 수많은 문자들 각각에 부여한 코드들의 집합
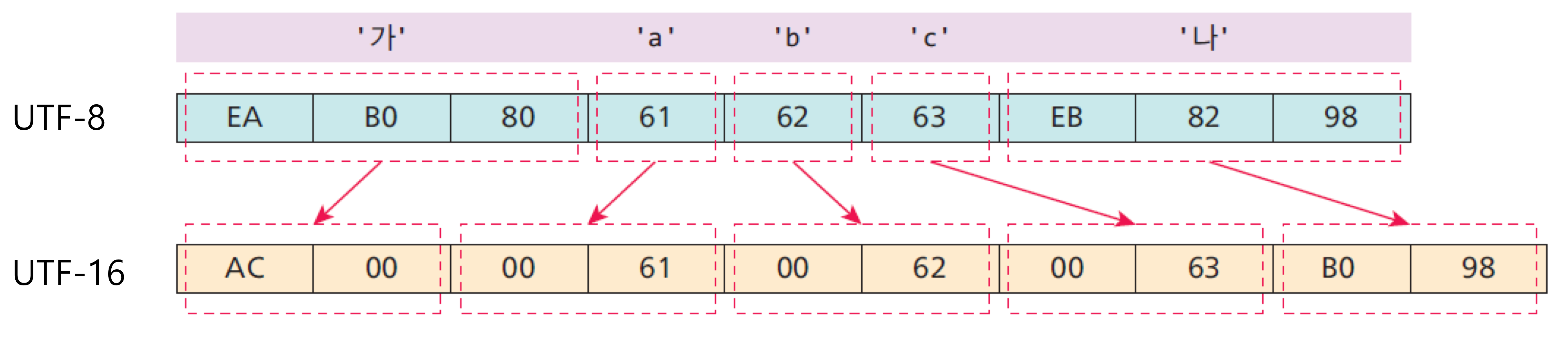
- UTF-8 : 1~4byte로 인코딩하는 가변 길이 인코딩 방식, 기본적으로 첫 128개의 문자들은 1byte에 그대로 인코딩
- UTF-16 : 16bit 기반의 인코딩 방식, 한글 2byte, ANSI와 호환이 되지 않는 문제 있음
6-2) InputStreamReader
- 바이트 스트림 -> 문자 스트림으로 변환
BufferedReader in = new BufferedReader(new InputStreamReader(
new FileInputStream(FileDir), "UTF8"));
- UTF-8 코딩 파일 읽기
publicclassCharEncodingTest{
publicstaticvoidmain(String[] args)throws IOException {
File FileDir = new File("input.txt");
BufferedReader in = new BufferedReader(new InputStreamReader(
new FileInputStream(fileDir), "UTF-8"));
String str;
while ((str=in.readLine()) != null) {
System.out.println(str);
}
in.close();
}
}
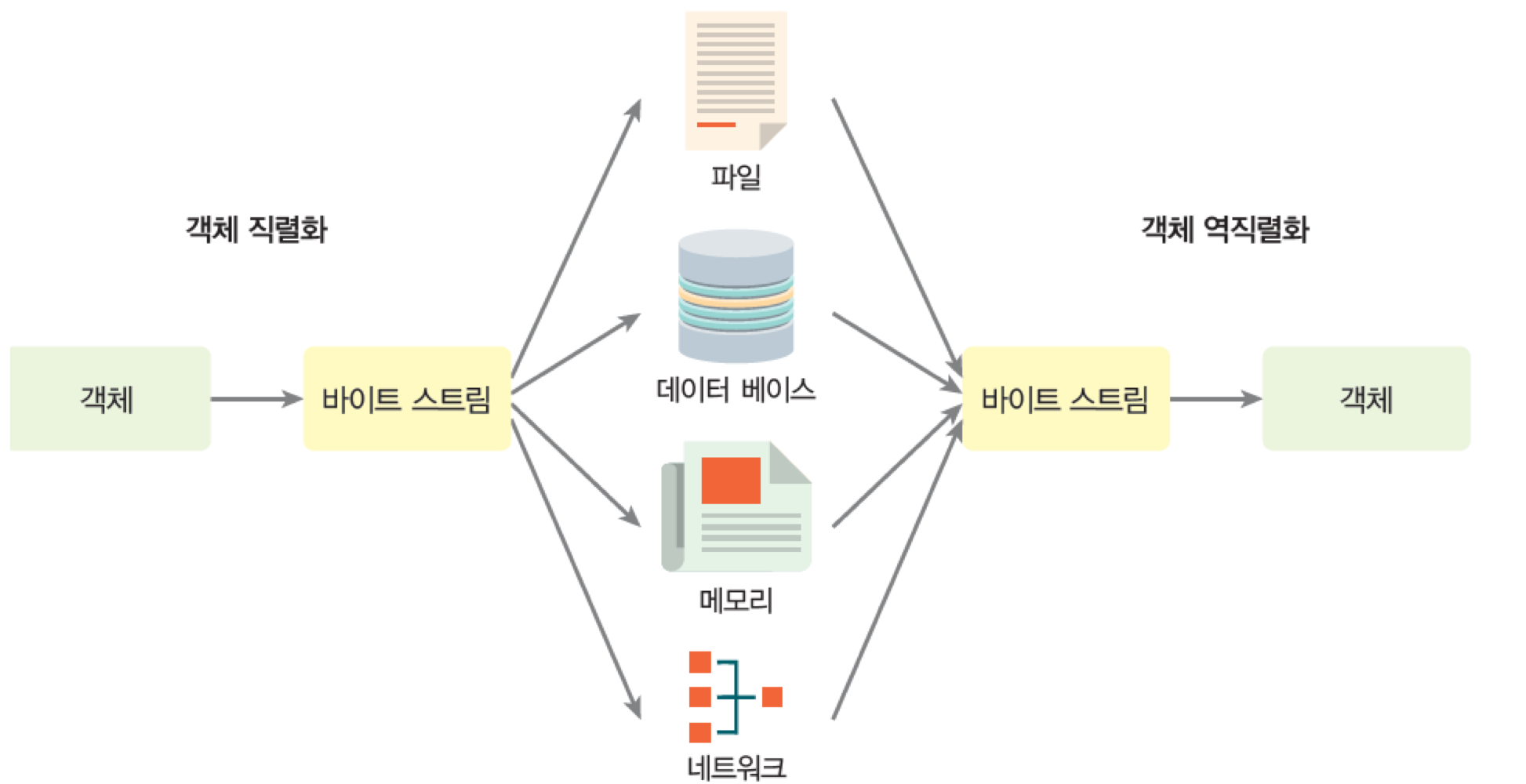
7. 객체 저장하기 : 객체 직렬화
- 객체 직렬화 : 객체가 가진 데이터들을 순차적인 데이터로 변환
- 순차적인 데이터가 되면 파일에 쉽게 저장할 수 있음
- 직렬화 지원 : Serializable 인터페이스 구현
- 역직렬화 : 직렬화된 데이터를 읽어서 자신의 상태를 복구하는 것
- Date 객체 저장하기
publicclassObjectStreamTest{
publicstaticvoidmain(String[] args)throws Exception {
ObjectInputStream in = null;
ObjectOutputStream out = null;
int c;
out = new ObjectOutputStream(new FileOutputStream("object.dat"));
out.writeObject(new Date());
out.close();
in = new ObjectInputStream(new FileInputStream("object.dat"));
Date d = (Date) in.readObject();
System.out.println(d);
in.close();
}
}
// Sat Jan 06 14:46:32 KST 2018
8. Path 객체
- 경로를 나타내는 클래스
- "D:\sources\test.txt" 와 같은 경로를 받아서 객체 반환
publicclassPathTest{
publicstaticvoidmain(String[] args){
Path path = Paths.get("D:\\sources\\test.txt");
System.out.println("전체 경로: " + path);
System.out.println("파일 이름: " + path.getFileName());
System.out.println("부모 이름: " + path.getParent().getFileName());
}
}
/**
전체 경로: D:\sources\test.txt
파일 이름: test.txt
부모 이름: sources
**/
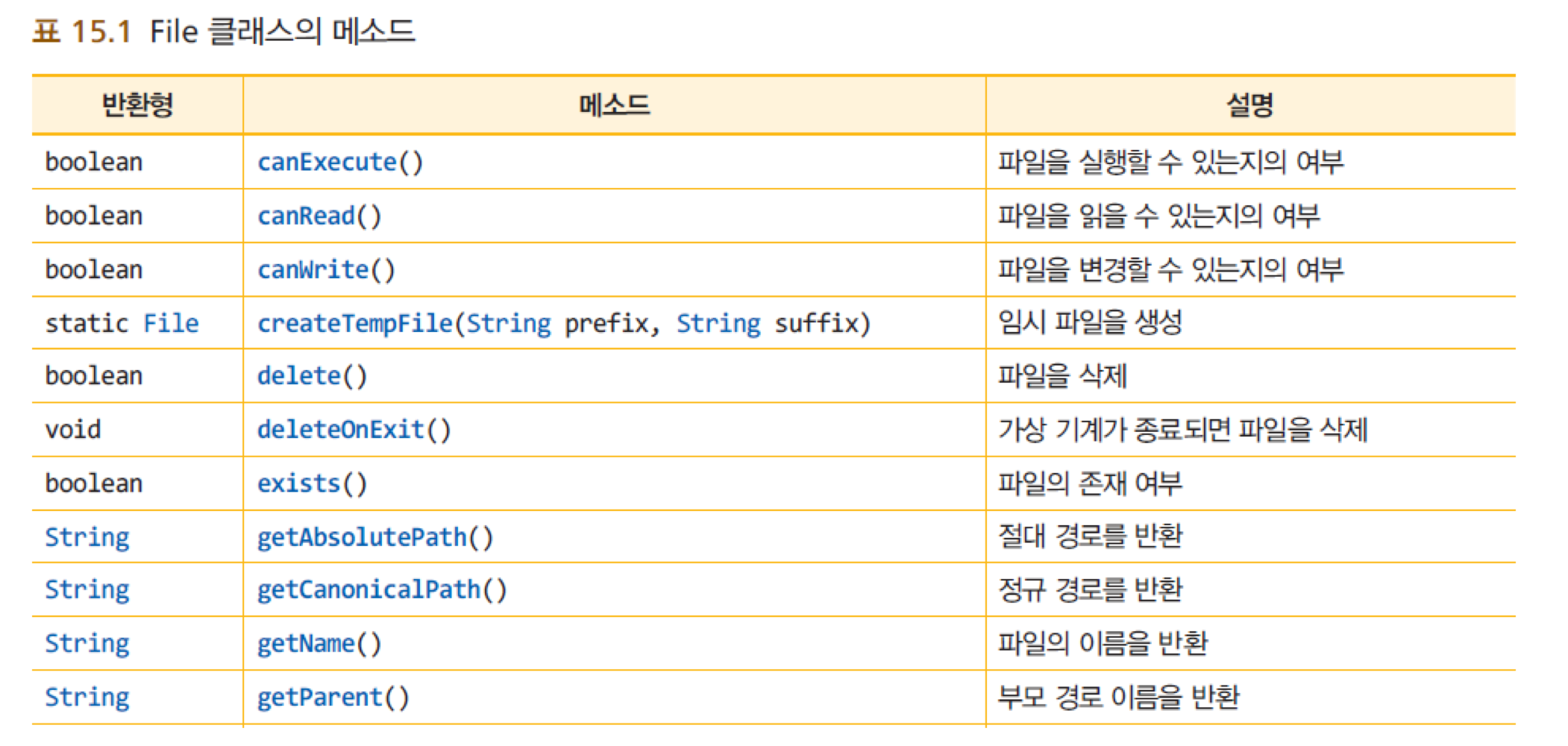
9. File 객체
- 파일을 조작하고 검사하는 코드를 쉽게 작성하게 해주는 클래스
- 파일이 아닌, 파일 이름을 나타내는 객체!
File file = new File("data.txt");
10. 스트림 라이브러리로 파일 처리하기
// 현재 디렉터리의 모든 파일을 출력하는 코드
Files.list(Paths.get(".")).forEach(System.out::println);
// 파일 읽어서 각 줄 끝에 있는 불필요한 공백을 제거하고 빈 줄을 필터링한 후에 출력
Files.lines(new File("test.txt").toPath())
.map(s -> s.trim())
.filter(s -> !s.isEmpty())
.forEach(System.out::println);
class Box<T> { ... } // T : 타입 매개변수 - String도 될 수 있고, Integer도 될 수 있음
2. 기존의 방법
일반적인 객체를 처리하려면 Object 참조 변수 사용: 어떤 객체이든지 참조 가능
publicclassBox{
private Object data;
private void set(Object data) { this.data = data; }
public Object get() { returndata; }
}
Box b = new Box();
b.set("Hello World!"); // 문자열 객체 저장
String s = (String)b.get(); // Object 타입을 String 타입으로 형변환
b.set(new Integer(10)); // 정수 객체 저장
Integer i = (Integer)b.get(); // Object 타입을 Integer 타입으로 형변환
b.set("Hello World!");
Integer i = (Integer)b.get(); // 오류! 문자열을 정수 객체로 형변환 (x)
3. 제네릭을 이용한 방법
classBox<T> {
private T data;
public void set(T data) { this.data = data; }
public T get() { returndata; }
}
Box<String> b = new Box<String>();
b.set("Hello World!"); // 문자열 저장
String s = b.get();
Box<String> stringBox = new Box<>(); // 뒤에 나오는 타입 <> 생략 가능
stringBox.set(new Integer(10)); // 정수 타입을 저장하려고 하면 컴파일 오류!
// 기존List<Integer> list = Arrays.asList( 1, 2, 3, 4, 5 );
for (Integer n : list )
System.out.println(n);
// 람다식list.forEach( n -> System.out.println(n) );
<br>